

# MLP Example
Multilayer perceptron (MLP) is a subclass of feed-forward neural networks. A MLP typically consists of multiple directly connected layers, with each layer fully connected to the next one. In this example, we will use SINGA to train a simple MLP model proposed by Ciresan for classifying handwritten digits from the MNIST dataset.
Please refer to the installation page for instructions on building SINGA, and the quick start for instructions on starting zookeeper.
We have provided scripts for preparing the training and test dataset in examples/cifar10/.
# in examples/mnist $ cp Makefile.example Makefile $ make download $ make create
After the datasets are prepared, we start the training by
./bin/singa-run.sh -conf examples/mnist/job.conf
After it is started, you should see output like
Record job information to /tmp/singa-log/job-info/job-1-20150817-055231 Executing : ./singa -conf /xxx/incubator-singa/examples/mnist/job.conf -singa_conf /xxx/incubator-singa/conf/singa.conf -singa_job 1 E0817 07:15:09.211885 34073 cluster.cc:51] proc #0 -> 192.168.5.128:49152 (pid = 34073) E0817 07:15:14.972231 34114 server.cc:36] Server (group = 0, id = 0) start E0817 07:15:14.972520 34115 worker.cc:134] Worker (group = 0, id = 0) start E0817 07:15:24.462602 34073 trainer.cc:373] Test step-0, loss : 2.341021, accuracy : 0.109100 E0817 07:15:47.341076 34073 trainer.cc:373] Train step-0, loss : 2.357269, accuracy : 0.099000 E0817 07:16:07.173364 34073 trainer.cc:373] Train step-10, loss : 2.222740, accuracy : 0.201800 E0817 07:16:26.714855 34073 trainer.cc:373] Train step-20, loss : 2.091030, accuracy : 0.327200 E0817 07:16:46.590946 34073 trainer.cc:373] Train step-30, loss : 1.969412, accuracy : 0.442100 E0817 07:17:06.207080 34073 trainer.cc:373] Train step-40, loss : 1.865466, accuracy : 0.514800 E0817 07:17:25.890033 34073 trainer.cc:373] Train step-50, loss : 1.773849, accuracy : 0.569100 E0817 07:17:51.208935 34073 trainer.cc:373] Test step-60, loss : 1.613709, accuracy : 0.662100 E0817 07:17:53.176766 34073 trainer.cc:373] Train step-60, loss : 1.659150, accuracy : 0.652600 E0817 07:18:12.783370 34073 trainer.cc:373] Train step-70, loss : 1.574024, accuracy : 0.666000 E0817 07:18:32.904942 34073 trainer.cc:373] Train step-80, loss : 1.529380, accuracy : 0.670500 E0817 07:18:52.608111 34073 trainer.cc:373] Train step-90, loss : 1.443911, accuracy : 0.703500 E0817 07:19:12.168465 34073 trainer.cc:373] Train step-100, loss : 1.387759, accuracy : 0.721000 E0817 07:19:31.855865 34073 trainer.cc:373] Train step-110, loss : 1.335246, accuracy : 0.736500 E0817 07:19:57.327133 34073 trainer.cc:373] Test step-120, loss : 1.216652, accuracy : 0.769900
After the training of some steps (depends on the setting) or the job is finished, SINGA will checkpoint the model parameters.
To train a model in SINGA, you need to prepare the datasets, and a job configuration which specifies the neural net structure, training algorithm (BP or CD), SGD update algorithm (e.g. Adagrad), number of training/test steps, etc.
Before using SINGA, you need to write a program to pre-process the dataset you use to a format that SINGA can read. Please refer to the Data Preparation to get details about preparing this MNIST dataset.
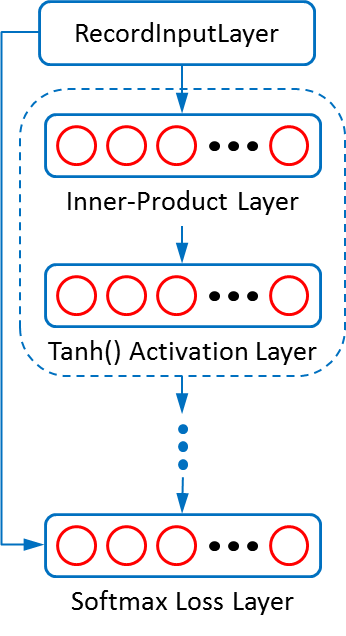
Figure 1 shows the structure of the simple MLP model, which is constructed following Ciresan’s paper. The dashed circle contains two layers which represent one feature transformation stage. There are 6 such stages in total. They sizes of the InnerProductLayers in these circles decrease from 2500->2000->1500->1000->500->10.
Next we follow the guide in neural net page and layer page to write the neural net configuration.
We configure a data layer to read the training/testing Records from DataShard.
layer {
name: "data"
type: kShardData
sharddata_conf {
path: "examples/mnist/mnist_train_shard"
batchsize: 1000
}
exclude: kTest
}
layer {
name: "data"
type: kShardData
sharddata_conf {
path: "examples/mnist/mnist_test_shard"
batchsize: 1000
}
exclude: kTrain
}
We configure two parser layers to extract the image feature and label from Recordss loaded by the data layer. The MnistLayer will normalize the pixel values into [-1,1].
layer{
name:"mnist"
type: kMnist
srclayers: "data"
mnist_conf {
norm_a: 127.5
norm_b: 1
}
}
layer{
name: "label"
type: kLabel
srclayers: "data"
}
All InnerProductLayers are configured similarly as,
layer{
name: "fc1"
type: kInnerProduct
srclayers:"mnist"
innerproduct_conf{
num_output: 2500
}
param{
name: "w1"
...
}
param{
name: "b1"
..
}
}
with the num_output decreasing from 2500 to 10.
A STanhLayer is connected to every InnerProductLayer except the last one. It transforms the feature via scaled tanh function.
layer{
name: "tanh1"
type: kSTanh
srclayers:"fc1"
}
The final Softmax loss layer connects to LabelLayer and the last STanhLayer.
layer{
name: "loss"
type:kSoftmaxLoss
softmaxloss_conf{ topk:1 }
srclayers:"fc6"
srclayers:"label"
}
The normal SGD updater is selected. The learning rate shrinks by 0.997 every 60 steps (i.e., one epoch).
updater{
type: kSGD
learning_rate{
base_lr: 0.001
type : kStep
step_conf{
change_freq: 60
gamma: 0.997
}
}
}
The MLP model is a feed-forward model, hence Back-propagation algorithm is selected.
train_one_batch {
alg: kBP
}
The following configuration set a single worker and server for training. Training frameworks page introduces configurations of a couple of distributed training frameworks.
cluster {
nworker_groups: 1
nserver_groups: 1
}