

SINGA is a general distributed deep learning platform for training big deep learning models over large datasets. It is designed with an intuitive programming model based on the layer abstraction. A variety of popular deep learning models are supported, namely feed-forward models including convolutional neural networks (CNN), energy models like restricted Boltzmann machine (RBM), and recurrent neural networks (RNN). Many built-in layers are provided for users. SINGA architecture is sufficiently flexible to run synchronous, asynchronous and hybrid training frameworks. SINGA also supports different neural net partitioning schemes to parallelize the training of large models, namely partitioning on batch dimension, feature dimension or hybrid partitioning.
As a distributed system, the first goal of SINGA is to have good scalability. In other words, SINGA is expected to reduce the total training time to achieve certain accuracy with more computing resources (i.e., machines).
The second goal is to make SINGA easy to use. It is non-trivial for programmers to develop and train models with deep and complex model structures. Distributed training further increases the burden of programmers, e.g., data and model partitioning, and network communication. Hence it is essential to provide an easy to use programming model so that users can implement their deep learning models/algorithms without much awareness of the underlying distributed platform.
Scalability is a challenging research problem for distributed deep learning training. SINGA provides a general architecture to exploit the scalability of different training frameworks. Synchronous training frameworks improve the efficiency of one training iteration, and asynchronous training frameworks improve the convergence rate. Given a fixed budget (e.g., cluster size), users can run a hybrid framework that maximizes the scalability by trading off between efficiency and convergence rate.
SINGA comes with a programming model designed based on the layer abstraction, which is intuitive for deep learning models. A variety of popular deep learning models can be expressed and trained using this programming model.
 Figure 1 - SGD flow.
Figure 1 - SGD flow.
Training a deep learning model is to find the optimal parameters involved in the transformation functions that generate good features for specific tasks. The goodness of a set of parameters is measured by a loss function, e.g., Cross-Entropy Loss. Since the loss functions are usually non-linear and non-convex, it is difficult to get a closed form solution. Typically, people use the stochastic gradient descent (SGD) algorithm, which randomly initializes the parameters and then iteratively updates them to reduce the loss as shown in Figure 1.
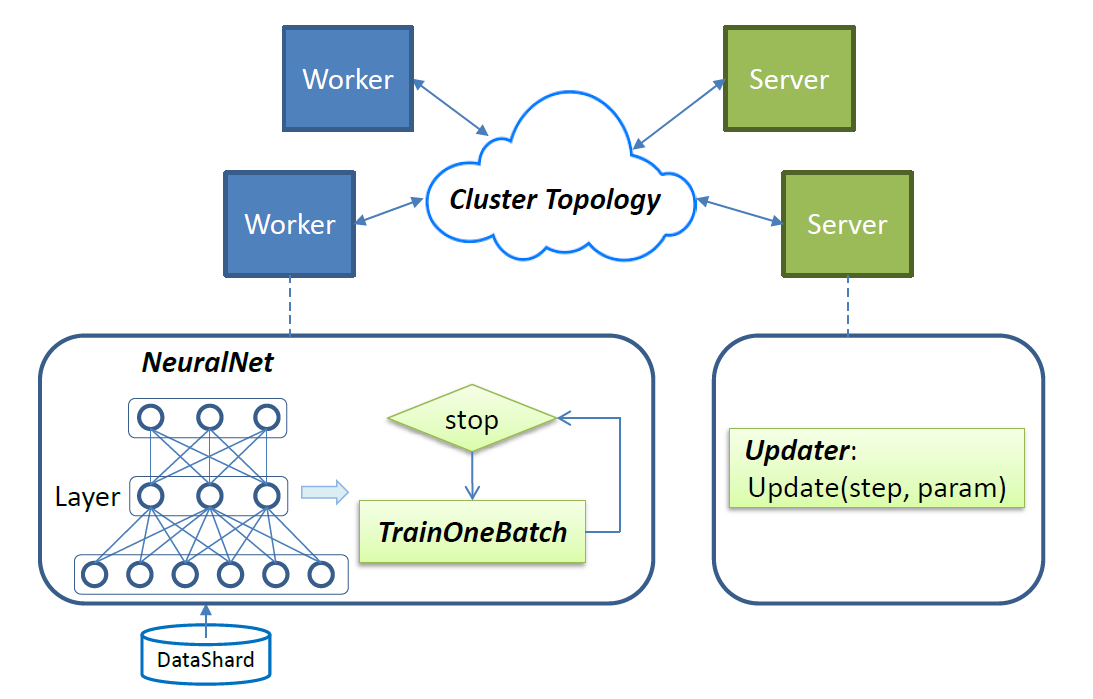 Figure 2 - SINGA overview.
Figure 2 - SINGA overview.
SGD is used in SINGA to train parameters of deep learning models. The training workload is distributed over worker and server units as shown in Figure 2. In each iteration, every worker calls TrainOneBatch function to compute parameter gradients. TrainOneBatch takes a NeuralNet object representing the neural net, and visits layers of the NeuralNet in certain order. The resultant gradients are sent to the local stub that aggregates the requests and forwards them to corresponding servers for updating. Servers reply to workers with the updated parameters for the next iteration.
To submit a job in SINGA (i.e., training a deep learning model), users pass the job configuration to SINGA driver in the main function. The job configuration specifies the four major components in Figure 2,
This process is like the job submission in Hadoop, where users configure their jobs in the main function to set the mapper, reducer, etc. In Hadoop, users can configure their jobs with their own (or built-in) mapper and reducer; in SINGA, users can configure their jobs with their own (or built-in) layer, updater, etc.