

SINGA는 대규모 데이터 분석을 위한 딥러닝 모델의 트레이닝을 목적으로 한 “분산 딥러닝 플랫폼” 입니다. 모델이 되는 뉴럴네트워크의 “Layer” 개념에 따라서 직관적인 프로그래밍을 할 수 있도록 디자인되어 있습니다.
Convolutional Neural Network 와 같은 피드포워드 네트워크와 Restricted Boltzmann Machine 과 같은 에너지 모델, Recurrent Neural Network 모델 등 다양한 모델을 지원합니다.
다양한 기능을 가지는 “Layer”들이 Built-in Layer 로 준비되어 있습니다.
SINGA 아키텍처는 synchronous (동기), asynchronous (비동기), 그리고 hybrid (하이브리드) 트레이닝을 할 수 있도록 설계되어 있습니다.
대형 모델의 트레이닝을 병렬화하는 다양한 partition 스킴 (배치 및 특징 분할)을 지원합니다.
확장성 : 분산 시스템으로써 더 많은 자원을 이용하여 특정 정밀도에 도달 할 때까지 트레이닝 속도를 향상시킨다.
유용성 : 대규모 분산 모델의 효율적인 트레이닝에 필요한 데이터와 모델의 분할, 네트워크 통신등 프로그래머의 작업을 단순화하고, 복잡한 모델 및 알고리즘의 구축을 쉽게 한다.
확장성은 분산 딥러닝에서 중요한 연구 과제입니다. SINGA는 다양한 트레이닝 프레임워크의 확장성을 유지할 수 있도록 설계되어 있습니다.
Synchronous (동기) : 트레이닝의 1단계에서 얻을 수있는 효과를 높입니다.
Asynchronous (비동기) : 트레이닝의 수렴 속도를 향상시킵니다.
Hybrid (하이브리드) : 코스트 및 리소스 (클러스터 크기 등)에 맞는 효과와 수렴 속도의 균형을 잡고 확장성을 향상시킵니다.
SINGA는 딥러닝 모델의 네트워크 “레이어” 개념에 따라 직관적으로 프로그래밍을 할 수 있도록 디자인되어 있습니다. 다양한 모델을 쉽게 구축하고 트레이닝 할 수 있습니다.
 Figure 1 - SGD Flow
Figure 1 - SGD Flow
“딥러닝 모델을 학습한다”는 것은 특정 작업(분류, 예측 등)을 달성하기 위하여 사용되는 특징량(feature)을 생성하는 변환 함수의 최적 파라미터를 찾는다는 것입니다. 그 변수의 좋고 나쁨은, Cross-Entropy Loss (https://en.wikipedia.org/wiki/Cross_entropy) 등의 loss function (손실 함수)으로 확인합니다. 이 함수는 일반적으로 비선형 또는 비 볼록 함수이므로 閉解을 찾기가 힘듭니다.
그래서 Stochastic Gradient Descent (확률적구배강하법)을 이용합니다. Figure 1과 같이 랜덤으로 초기화 된 파라미터 값을, 손실 함수가 작아 지도록 반복 업데이트하고 있습니다.
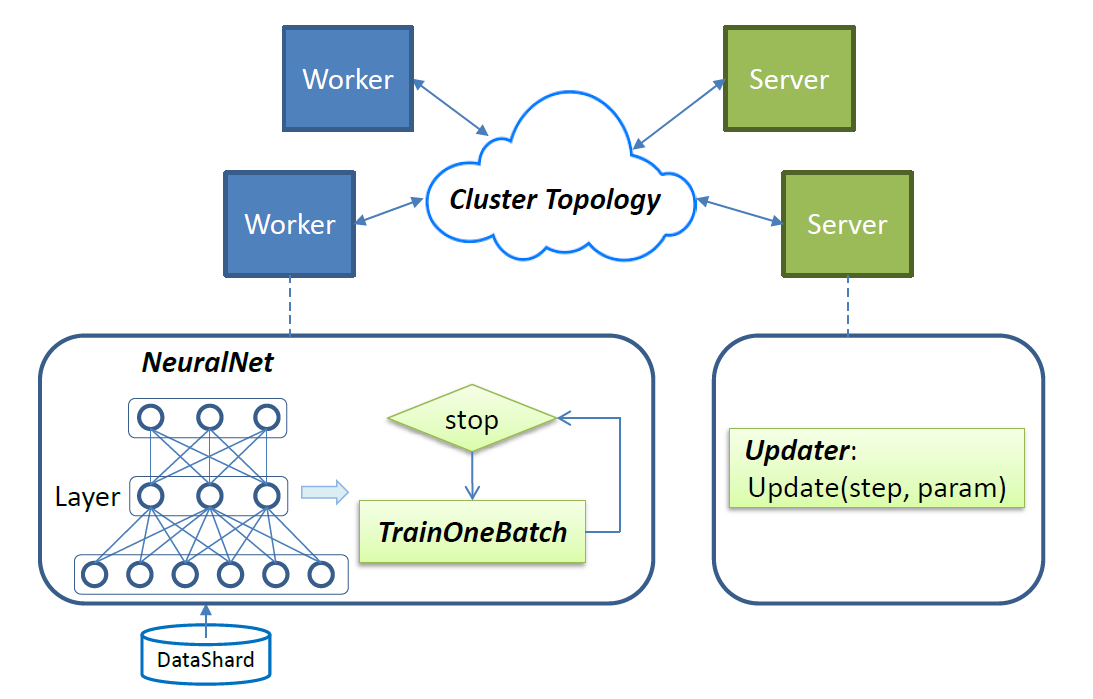 Figure 2 - SINGA Overview
Figure 2 - SINGA Overview
트레이닝에 필요한 워크로드는 workers 와 servers 에 분산됩니다. Figure 2와 같이 루프(iteration)마다 workers 는 TrainOneBatch 함수를 불러서 파라미터 구배를 계산합니다. TrainOneBatch 는 뉴럴네트워크의 구조가 기술 된 NeuralNet 정보에 따라서 “Layer”를 차례로 둘러봅니다. 계산 된 구배는 로컬노드의 stub 에 보내져 집계 된 후, 해당 servers 에 전송됩니다. Servers 는 업데이트 된 파라미터 값을 workers 한테 되돌려주고, 다음 루프(iteration)를 진행합니다.
SINGA에서 “Job”이란 뉴럴네트워크 모델과 데이터 트레이닝 방법, 클러스터 토폴로지 등이 기술 된 “Job Configuration”을 말합니다. Job configuration 은 Figure 2에 그려진 다음의 4가지 요소를 가집니다.
main 함수의 SINGA 드라이버를 써서 Job 을 넘깁니다.
이 프로세스는 Hadoop에서의 Job 서브미션과 비슷합니다. 유저가 main 함수에서 작업 설정을 합니다. Hadoop 유저는 자신의 mapper와 reducer를 설정하지만 SINGA 에서는 유저의 Layer 나 Updater 등을 설정합니다.