

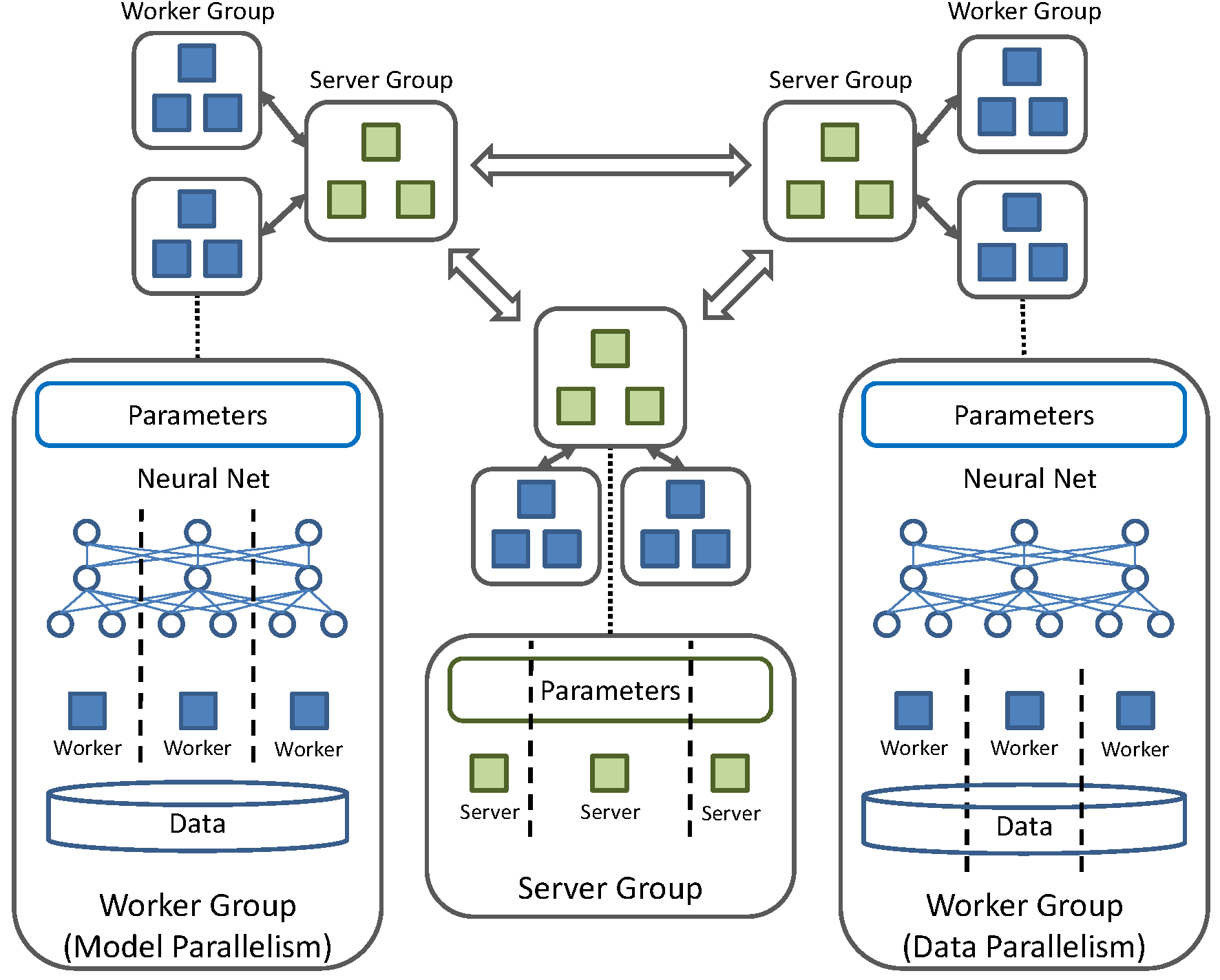
Fig.1 - Logical system architecture
SINGA has flexible architecture to support different distributed training frameworks (both synchronous and asynchronous). The logical system architecture is shown in Fig.1. The architecture consists of multiple server groups and worker groups:
There are different strategies to distribute the training workload among workers within a group:
In SINGA, servers and workers are execution units running in separate threads. They communicate through messages. Every process runs the main thread as a stub that aggregates local messages and forwards them to corresponding (remote) receivers.
Each server group and worker group have a ParamShard object representing a complete model replica. If workers and servers resident in the same process, their ParamShard (partitions) can be configured to share the same memory space. In this case, the messages transferred between different execution units just contain pointers to the data, which reduces the communication cost. Unlike in inter-process cases, the messages have to include the parameter values.