

SINGA是一个通用的分布式深度学习平台,面向训练大规模数据集上的大型深度学习模型。其设计基于一种直观的编程模型,即深度学习中层(layer)的抽象。SINGA支持大部分深度学习模型,包括卷积神经网络(CNN)、受限波尔兹曼模型(RBM)和循环神经网络(RNN)等,为用户提供许多可直接使用的内建层。SINGA架构灵活,支持同步训练、异步训练和混合式训练。为了并行地训练深度学习模型,SINGA支持不同的神经网络划分机制,即批次维度划分(batch dimension partition),特征维度划分(feature dimension partition)和多维度混合划分(hybrid partition)。
作为一个分布式系统,SINGA的首要目标就是具有良好的可扩展性。换言之,SINGA希望在准确度一定的情况下,通过利用更多的计算资源(即计算机)减少模型的训练时间。
SINGA的另一个目标是易用性。对程序员来说,开发和训练深层的复杂结构的深度学习模型十分困难。分布式训练又进一步增加了程序员的负担,比如:数据和模型划分,网络通信等。因此,提供一个易用的编程模型是十分重要的,可以让程序员在实现自己的深度学习模型和算法时不必考虑底层的分布式平台。
扩展性是分布式深度学习的重要研究问题。SINGA提供了一个利用不同训练框架扩展性的通用平台。同步训练框架可提高每次训练迭代的效率,同时异步训练框架可加快模型收敛。在预算(比如:集群规模)一定的情况下,用户可以运行一个混合训练框架,在效率和收敛速度之间权衡,以取得最大的扩展性。
SINGA的编程模型是基于层的抽象而设计,这对于深度学习模型而言是十分直观的。很多深度学习模型可以直接用这种编程模型来表达和训练。
 图1 - 随机梯度下降流程图
图1 - 随机梯度下降流程图
对于特定的任务,训练一个深度学习模型就是找出能产生良好特征的转换函数中的最优参数。参数的合适程度由损失函数来度量,如交叉熵损失函数(Cross-Entropy Loss)。因为损失函数一般都是非线性和非凸的,难以得到一个封闭形式解。典型的解决方案是使用随机梯度下降(SGD)算法,首先随机地初始化参数,然后迭代地更新参数值,减小损失函数值,如图1所示。
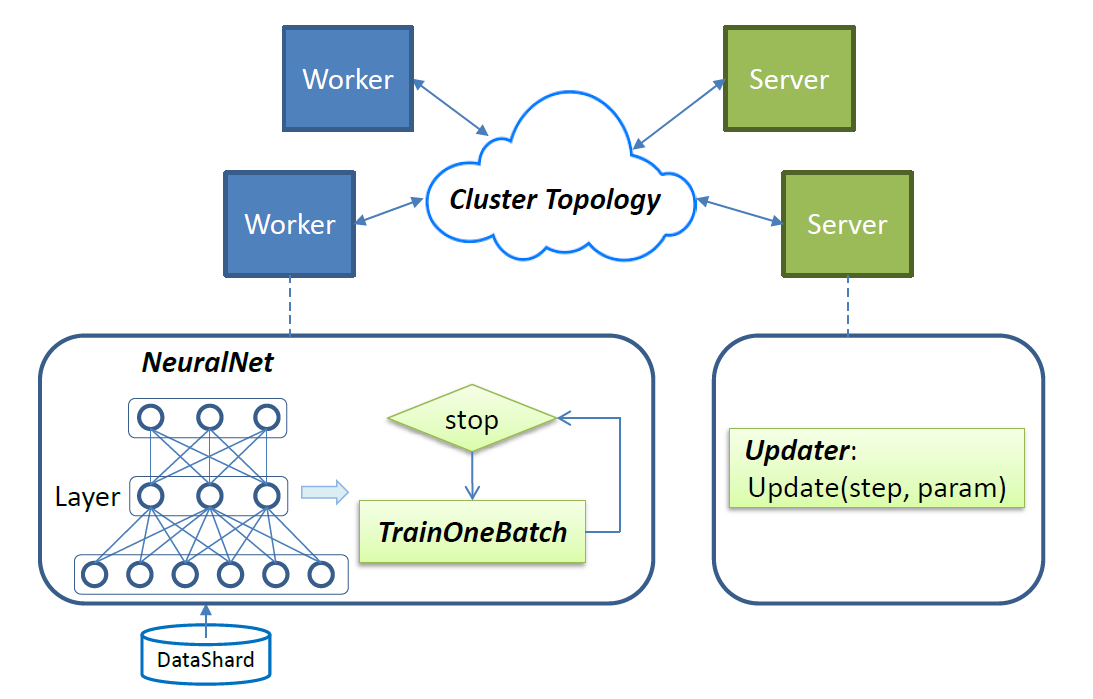 图2 - SINGA 概览
图2 - SINGA 概览
SINGA使用随机梯度下降来训练深度学习模型中的参数。训练的作业会被分配到作业者(worker)单元和服务器(server)单元,如图2所示。每次迭代中,作业者调用 TrainOneBatch 函数计算参数的梯度。 TainOneBatch 函数以一个神经网络对象 NeuralNet 作为输入,以一定的顺序遍历 NeuralNet。计算得到的梯度将发送给局部的根节点(stub),该局部根节点聚合请求并转发给对应的服务器请求更新。服务器给作业者发回更新后的参数,进入下一轮迭代。
在SINGA中提交一个作业(即训练一个深度学习模型),用户需要将任务配置传给主函数中的SINGA driver。作业配置需要明确图2中的四个主要部分:
作业提交过程跟Hadoop的作业提交类似,用户在主函数中配置好自己的任务,设置mapper和reducer等。在Hadoop中,用户可用自己实现的或者内建的mapper和reducer来配置他们的作业;类似地,在SINGA中,用户也可以用自己实现的或者内建的layer,updater等来配置他们的作业。