

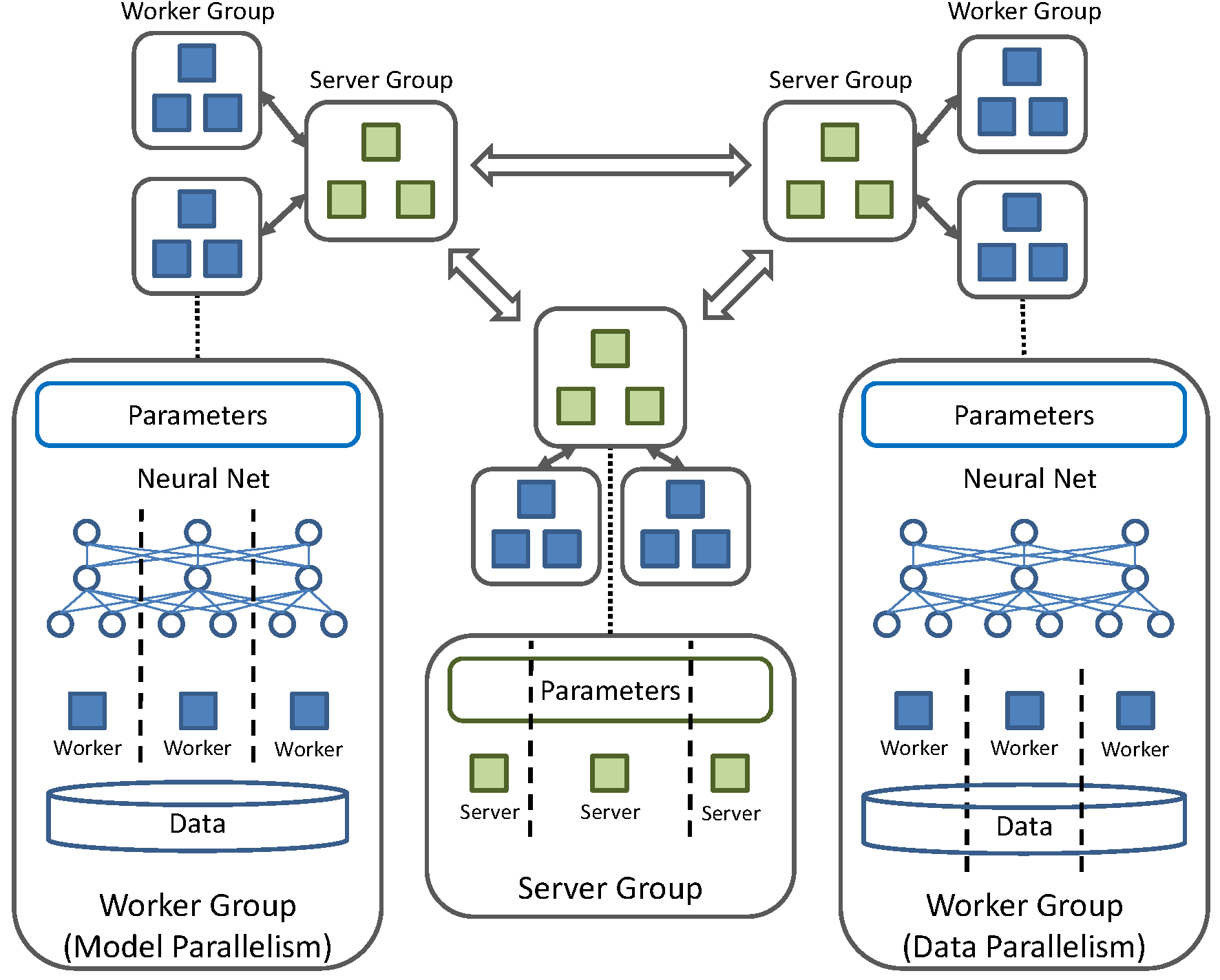
Fig.1 - 시스템 아키텍처
SINGA는 다양한 분산 트레이닝 프레임워크 (동기 혹은 비동기 트레이닝)을 지원하는 구조를 가지고 있습니다. 특징으로는 여러 server그룹 과 worker그룹을 가지고 있습니다.
Server 그룹
Server그룹은 모델 매개 변수의 복제를 가지고 worker그룹의 요청에 따라 매개 변수의 업데이트를 담당합니다. 인접된 server그룹들은 매개 변수를 정기적으로 동기화합니다. 일반적으로 하나의 server그룹은 여러 server로 구성되며, 각 server는 모델 매개 변수의 분할 된 부분을 담당합니다.
Worker 그룹
각 worker그룹은 하나의 server그룹과 통신합니다. 하나의 worker그룹은 매개 변수의 구배계산을 담당합니다. 또한 분할 된 일부 데이터를 써서 “전체”모델의 레프리카를 트레이닝합니다. 모든 worker그룹들은 해당 server그룹들과 비동기 통신을 합니다. 그러나 같은 worker그룹의 worker들은 동기합니다.
동일 그룹 내에서 worker들의 분산 트레이닝에는 많은 방법이 있습니다.
모델 병렬화
각 worker그룹에 배정 된 모든 데이터에 대해 매개 변수의 부분 집합을 계산합니다.
데이터 병렬화
각 worker는 배분 된 데이터의 부분 집합에 대해 모든 매개 변수를 계산합니다.
하이브리드 병렬화
위의 방법을 조합한 하이브리드 병렬화를 지원합니다.
SINGA에서 servers 와 workers는 다른 스레드에서 실행되는 유닛입니다.
이들은 messages를 이용하여 통신을 합니다. 모든 프로세스는 메인 스레드인 stub을 실행하여 로컬 messages를 수집하고 대응되는 receiver에 전송합니다.
각 server그룹과 worker그룹은 “전체”모델 레프리카인 ParamShard 를 가집니다. 만약 workers 와 servers 가 동일한 프로세스에서 실행 된다면, 그 ParamShard (파티션)은 메모리 공간을 공유하도록 설정됩니다. 이 경우 다른 실행 유닛 사이를 오가는 messages는 통신 비용을 줄이기 위해 데이터의 포인터 만 포함합니다. 프로세스 간 통신의 경우와는 달리 messages는 파라미터 값을 포함합니다.