This document comprehensively describes the procedure of running a MapReduce job using Oozie. Its targeted audience is all forms of users who will install, use and operate Oozie.
NOTE: This tutorial has been prepared assuming GNU/Linux as the choice of development and production platform.
Hadoop MapReduce is a programming model and software framework for writing applications that rapidly process vast amounts of data in parallel on the Grid. Although MapReduce applications can be launched independently, there are obvious advantages on submitting them via Oozie such as:
Follow the instructions on Hadoop MapReduce Tutorial to run a simple MapReduce application (wordcount). This involves invoking the hadoop commands to submit the mapreduce job by specifying various commandline options.
In order to describe the key differences in submitting a job using Oozie, lets compare the following two approaches.
Hadoop Map-Reduce Job Submission
$ hadoop jar /usr/ninja/wordcount.jar org.myorg.WordCount -Dmapred.job.queue.name=queue_name /usr/ninja/wordcount/input /usr/ninja/wordcount/output
Oozie Map-Reduce Job Submission
Oozie acts as a middle-man between the user and hadoop. The user provides details of his job to Oozie and Oozie executes it on Hadoop via a launcher job followed by returning the results. It provides a way for the user to set the various above parameters such as mapred.job.queue.name, input directory, output directory in a workflow XML file. A workflow is defined as a set of actions arranged in a DAG (Direct Acyclic Graph) as shown below:
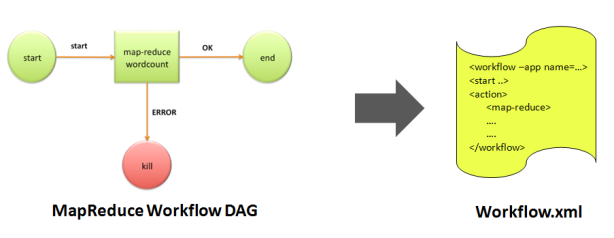
Below are the three components required to launch a simple MapReduce workflow:
I: Properties File - job.properties
This file is present locally on the node from which the job is submitted (either a local machine or the gateway node). Its main purpose is to specify essential parameters needed for running the workflow. One mandatory property to be specified is oozie.wf.application.path that points to the location of the HDFS where workflow.xml exists. In addition, definition for all those variables used in workflow.xml (eg: $jobTracker, $inputDir, ..) can be added here. For some specific versions of Hadoop, additional authentication parametersPROVIDE LINK might also need to be defined. For our example, this file looks like below:
nameNode=hdfs://localhost:9000 # or use a remote-server url. eg: hdfs://abc.xyz.yahoo.com:8020
jobTracker=localhost:9001 # or use a remote-server url. eg: abc.xyz.yahoo.com:50300
queueName=default
examplesRoot=map-reduce
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}
inputDir=input-data
outputDir=map-reduce
II: Workflow XML - workflow.xml
This file defines the workflow for the particular job as a set of actions. For our example, this file looks like below:
<workflow-app name='wordcount-wf' xmlns="uri:oozie:workflow:0.2">
<start to='wordcount'/>
<action name='wordcount'>
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<property>
<name>mapred.mapper.class</name>
<value>org.myorg.WordCount.Map</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.myorg.WordCount.Reduce</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>${inputDir}</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${outputDir}</value>
</property>
</configuration>
</map-reduce>
<ok to='end'/>
<error to='end'/>
</action>
<kill name='kill'>
<value>${wf:errorCode("wordcount")}</value>
</kill/>
<end name='end'/>
</workflow-app>
Details of the basic XML tags used in workflow.xml (exhaustive description of all elements available in the Workflow XML Schema Definitionprovide link):
Format: jobtracker_hostname:port_number
Example: localhost:9001, abc.xyz.yahoo.com:50300
Format: hdfs://namenode_hostname:port_number
Example: hdfs://localhost:9000, hdfs://abc.xyz.yahoo.com:8020
jobtracker and namenode need to be same as the ones defined in the hadoop configuration files. If they are different, they would need to be updated.
III: Libraries - lib/ This is a directory in the HDFS which contains libraries used in the workflow (such as jar files (.jar) or shared object files (.so)). During runtime, the Oozie server picks up contents of this directory and deploys them on the actual compute node using Hadoop distributed cache. When submitting job from the users local system, this lib directory would have to be manually copied over to the HDFS before the workflow can run. This can be done using the Hadoop filesystem commmand put. Additional ways of linking files and archives are dealt with in a subsequent section How to specify symbolic links for files and archives . In our example, the lib/ directory would contain the wordcount.jar file.
Now, follow the steps below to try out the wordcount mapreduce application:
$ cd ~ $ mkdir map-reduce $ mkdir map-reduce/lib
It should be noted that this workflow directory and its contents are created on the local filesystem and they must be copied to the HDFS filesystem once they are ready.
Tip: The following Oozie command line option can be used to perform XML schema validation on the workflow XML file and return errors if any:
$ oozie validate ~/map_reduce/workflow.xml
$ cat ~/map_reduce/job.properties
nameNode=hdfs://localhost:9000
jobTracker=localhost:9001
queueName=default
examplesRoot=map-reduce
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}
inputDir=input-data
outputDir=map-reduce
job.properties workflow.xml lib/ lib/wordcount.jar
However, it should be noted that the job.properties file is always used from the local filesystem and it need not be copied to the HDFS filesystem.
$ hadoop fs -put ~/map-reduce map-reduce
$ oozie job -oozie http://localhost:4080/oozie/ -config ~/map-reduce/job.properties -run ... ... job: 14-20090525161321-oozie-ninj
-config option specifies the location of the properties file, which in our case is in the user's home directory. (Note: only the workflow and libraries need to be on HDFS, not the properties file).
-oozie option specifies the location of the Oozie server. This could be omitted if the variable OOZIE_URL is set with the server url.
$ oozie job -info 14-20090525161321-oozie-ninj -oozie http://localhost:4080/oozie/ ... ... .--------------------------------------------------------------------------------------------------------------------------------------------------------------- Workflow Name : wordcount-wf App Path : hdfs://localhost:4080/user/ninja/map-reduce Status : SUCCEEDED Run : 0 User : ninja Group : users Created : 2011-09-21 05:01 +0000 Started : 2011-09-21 05:01 +0000 Ended : 2011-09-21 05:01 +0000 Actions .---------------------------------------------------------------------------------------------------------------------------------------------------------------- Action Name Type Status Transition External Id External Status Error Code Start Time End Time .---------------------------------------------------------------------------------------------------------------------------------------------------------------- wordcount map-reduce OK end job_200904281535_0254 SUCCEEDED - 2011-09-21 05:01 +0000 2011-09-21 05:01 +0000 .----------------------------------------------------------------------------------------------------------------------------------------------------------------
Tip: A graphical view of the workflow job status can be obtained via the Oozie web console.
In Oozie, there are numerous ways to specify the values for parameters being passed using configuration xml files. And, there is an order of precedence in which these parameters are evaluated. Below are the different ways of passing parameters for the MapReduce job to Oozie. The variables values can be defined in:
Variable Substitution
Example 1:
in job.properties:
VAR=job-properties
in config-default.xml:
<property><name>VAR</name><value>config-default-xml</value></property>
in workflow.xml:
<property><name>VARIABLE</name><value>${VAR}</value></property>
then VARIABLE is resolved to "job-properties".
Example 2:
in job.properties:
variable4=job-properties
in config-default.xml:
<property><name>variable4</name><value>config-default-xml</value></property>
in workflow.xml:
<job-xml>mr3-job.xml</job-xml>
... ...
<property><name>variable4</name><value>grideng</value></property>
in mr3-job.xml:
<property><name>mapred.job.queue.name</name><value>${variable4}</value></property>
then mapred.job.queue.name is resolved to "grideng".
Example 3:
in workflow.xml:
<job-xml>mr3-job.xml</job-xml>
... ...
<property><name>mapred.job.queue.name</name><value>grideng</value></property>
in mr3-job.xml:
<property><name>mapred.job.queue.name</name><value>bogus</value></property>
then mapred.job.queue.name is resolved to "grideng".
Example 4:
in job.properties:
nameNode=hdfs://abc.xyz.yahoo.com:8020
outputDir=output-allactions
in workflow.xml:
<case to="end">${fs:exists(concat(concat(concat(concat(concat(nameNode,"/user/"),wf:user()),"/"),wf:conf("outputDir")),"/streaming/part-00000")) and (fs:fileSize(concat(concat(concat(concat(concat(nameNode,"/user/"),wf:user()),"/"),wf:conf("outputDir")),"/streaming/part-00000")) gt 0) == "true"}</case>
Note: A variable defined in workflow.xml VAR can be referenced as ${VAR} only if VAR follows strict Java identifier naming conventions (no spaces in between). If however, dots must be used in the names, then the variable would need to be referenced as ${wf:conf('VAR')}.
Since new MR API (a.k.a. Hadoop 20 API) is neither stable nor supported, it is highly recommended not to use new MR API. Instead, Hadoop team recommends using the old API at least until Hadoop 0.23.x is released. The reasons behind this recommendation are as follows:
However, if you really need to run MapReduce jobs written using the 20 API in Oozie, below are the changes you need to make in workflow.xml.
<property>
<name>mapred.reducer.new-api</name>
<value>true</value>
</property>
<property>
<name>mapred.mapper.new-api</name>
<value>true</value>
</property>
The changes to be made in workflow.xml file are highlighted below:
<map-reduce xmlns="uri:oozie:workflow:0.1">
<job-tracker>abc.xyz.yahoo.com:50300</job-tracker>
<name-node>hdfs://abc.xyz.yahoo.com:8020</name-node>
<prepare>
<delete path="hdfs://abc.xyz.yahoo.com:8020/user/ninja/yoozie_test/output-mr20-fail" />
</prepare>
<configuration>
<!-- BEGIN: SNIPPET TO ADD IN ORDER TO MAKE USE OF HADOOP 20 API -->
<property>
<name>mapred.mapper.new-api</name>
<value>true</value>
</property>
<property>
<name>mapred.reducer.new-api</name>
<value>true</value>
</property>
<!-- END: SNIPPET -->
<property>
<name>mapreduce.map.class</name>
<value>org.myorg.WordCount$TokenizerMapper</value>
</property>
<property>
<name>mapreduce.reduce.class</name>
<value>org.myorg.WordCount$IntSumReducer</value>
</property>
<property>
<name>mapred.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<property>
<name>mapred.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/user/ninja/yoozie_test/input-data</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>/user/ninja/yoozie_test/output-mr20/mapRed20</value>
</property>
<property>
<name>mapred.job.queue.name</name>
<value>grideng</value>
</property>
<property>
<name>mapreduce.job.acl-view-job</name>
<value>*</value>
</property>
<property>
<name>oozie.launcher.mapreduce.job.acl-view-job</name>
<value>*</value>
</property>
</configuration>
</map-reduce>
This example generates a user-defined hadoop-counter named ['COMMON']['COMMON.ERROR_ACCESS_DH_FILES'] in the first action mr1 and describes how to access its value in the subsequent action java1.
The changes made in the workflow.xml are highlighted below:
<workflow-app xmlns='uri:oozie:workflow:0.1' name='java-wf'>
<start to='mr1' />
<action name='mr1'>
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.mapper.class</name>
<value>org.myorg.SampleMapper</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.myorg.SampleReducer</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>${inputDir}</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${outputDir}/streaming-output</value>
</property>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024M</value>
</property>
</configuration>
</map-reduce>
<ok to="java1" />
<error to="fail" />
</action>
<action name='java1'>
<java>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<main-class>org.myorg.MyTest</main-class>
<!-- BEGIN: SNIPPET TO ADD TO ACCESS HADOOP COUNTERS DEFINED IN PREVIOUS ACTIONS -->
<arg>${hadoop:counters("mr1")["COMMON"]["COMMON.ERROR_ACCESS_DH_FILES"]}</arg>
<!-- END: SNIPPET TO ADD -->
<capture-output/>
</java>
<ok to="pig1" />
<error to="fail" />
</action>
<kill name="fail">
<value>${wf:errorCode("wordcount")}</value>
</kill>
<end name='end' />
</workflow-app>
MapReduce tasks are launched with some default memory limits that are provided by the system or by the cluster's administrators. Memory intensive jobs might need to use more than these default values. Hadoop has some configuration options that allow these to be changed. Without such modifications, memory intensive jobs could fail due to OutOfMemory errors in tasks or could get killed when the limits are enforced by the system. This section describes a way in which this could be tuned from within Oozie.
A property mapred.child.java.opts can be defined in workflow.xml as below:
<workflow-app xmlns='uri:oozie:workflow:0.1' name='streaming-wf'>
<start to='streaming1' />
<action name='streaming1'>
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<streaming>
<mapper>/bin/cat</mapper>
<reducer>/usr/bin/wc</reducer>
</streaming>
<configuration>
<property>
<name>mapred.input.dir</name>
<value>${inputDir}</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${outputDir}/streaming-output</value>
</property>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<!-- BEGIN: SNIPPET TO ADD TO INCREASE MEMORY FOR THE HADOOP JOB-->
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024M</value>
</property>
<!-- END: SNIPPET TO ADD -->
</configuration>
</map-reduce>
<ok to="end" />
<error to="fail" />
</action>
<kill name="fail">
<value>${wf:errorCode("wordcount")}</value>
</kill>
<end name='end' />
</workflow-app>
In order to define and use a custom input format in the map-reduce action, the property mapred.input.format.class needs to be included in the workflow.xml as highlighted below:
<workflow-app xmlns='uri:oozie:workflow:0.1' name='streaming-wf'>
<start to='streaming1' />
<action name='streaming1'>
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<streaming>
<mapper>/bin/cat</mapper>
<reducer>/usr/bin/wc</reducer>
</streaming>
<configuration>
<property>
<name>mapred.input.dir</name>
<value>${inputDir}</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${outputDir}/streaming-output</value>
</property>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<!-- BEGIN: SNIPPET TO ADD TO DEFINE A CUSTOM INPUT FORMAT -->
<property>
<name>mapred.input.format.class</name>
<value>com.yahoo.ymail.antispam.featurelibrary.TextInputFormat</value>
</property>
<!-- END: SNIPPET TO ADD -->
</configuration>
</map-reduce>
<ok to="end" />
<error to="fail" />
</action>
<kill name="fail">
<value>${wf:errorCode("wordcount")}</value>
</kill>
<end name='end' />
</workflow-app>
NOTE: It should be noted that the jar file containing the custom input format class must be placed in the workflow's lib/ directory.
MapReduce applications can specify symbolic names for files and archives passed through the options \âfiles and \âarchives using # such as below:
$ hadoop jar hadoop-examples.jar wordcount -files dir1/dict.txt#dict1,dir2/dict.txt#dict2 -archives mytar.tgz#tgzdir input output
Here, the files dir1/dict.txt and dir2/dict.txt can be accessed by tasks using the symbolic names dict1 and dict2 respectively. The archive mytar.tgz will be placed and unarchived into a directory by the name tgzdir.
Oozie supports these by allowing <file> and <archive> tags that can be defined in the workflow.xml as below:
<workflow-app name='wordcount-wf' xmlns="uri:oozie:workflow:0.2">
<start to='wordcount'/>
<action name='wordcount'>
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="hdfs://abc.xyz.yahoo.com:8020/user/ninja/test/output" />
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<property>
<name>mapred.mapper.class</name>
<value>org.myorg.WordCount.Map</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.myorg.WordCount.Reduce</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>${inputDir}</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${outputDir}</value>
</property>
</configuration>
<!-- BEGIN: SNIPPET TO ADD TO DEFINE FILE/ARCHIVE TAGS -->
<file>testdir1/dict.txt#dict1</file>
<archive>testtar.tgz#tgzdir</archive>
<!-- END: SNIPPET TO ADD -->
</map-reduce>
<ok to='end'/>
<error to='end'/>
</action>
<kill name='kill'>
<value>${wf:errorCode("wordcount")}</value>
</kill/>
<end name='end'/>
</workflow-app>
Here, the files test1/dict.txt can be accessed by tasks using the symbolic names. The symbolic names cannot be a multi-level path (ie. their names should not contain any '/'). This also emphasizes the fact that symbolic links are always in the current working directory. The archive testtar.tgz will be placed and unarchived into a directory by the name tgzdir.
Please note that the âlibjars option supported by the Hadoop command-line is not supported by Oozie.
Hadoop Streaming allows the user to create and run Map/Reduce jobs with any executable or script as the mapper and/or the reducer (instead of providing the mapper and reducer as conventional java classes). The commandline way of launching such a Hadoop MapReduce streaming job is as follows:
$ hadoop jar lib/hadoop-streaming-0.20.1.3006291003.jar -D mapred.job.queue.name=unfunded -input /user/ninja/input-data -output /user/ninja/output-dir -mapper /bin/cat -reducer /usr/bin/wc
In order to accomplish the same using Oozie, the following <streaming> element needs to be included inside the <map-reduce> action.
<streaming>
<mapper>/bin/cat</mapper>
<reducer>/usr/bin/wc</reducer>
</streaming>
The complete workflow.xml file looks like below with the highlighted addition:
<workflow-app xmlns='uri:oozie:workflow:0.1' name='streaming-wf'>
<start to='streaming1' />
<action name='streaming1'>
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<!-- BEGIN: SNIPPET TO ADD FOR HADOOP STREAMING ACTION -->
<streaming>
<mapper>/bin/cat</mapper>
<reducer>/usr/bin/wc</reducer>
</streaming>
<!-- END: SNIPPET TO ADD -->
<configuration>
<property>
<name>mapred.input.dir</name>
<value>${inputDir}</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${outputDir}/streaming-output</value>
</property>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024M</value>
</property>
</configuration>
</map-reduce>
<ok to="end" />
<error to="fail" />
</action>
<kill name="fail">
<value>${wf:errorCode("wordcount")}</value>
</kill>
<end name='end' />
</workflow-app>
CASE-8: HOW TO USE THE OOZIE WEB-CONSOLE
Oozie web-console provides a way to view all the submitted workflow and coordinator jobs in a browser. Each job could be examined in detail to reveal its job configuration, workflow definition and all the actions defined for it. It can be accessed by visiting the url used to submit the job, for eg: http://localhost:4080/oozie.
Note: Please note that the web-console is read-only user interface and it cannot be used to submit a job or modify its status.
Below are some screenshots describing how a job could be drilled down for further details using the web-console.
All the jobs are listed in the grid with filters available above to view the desired job.
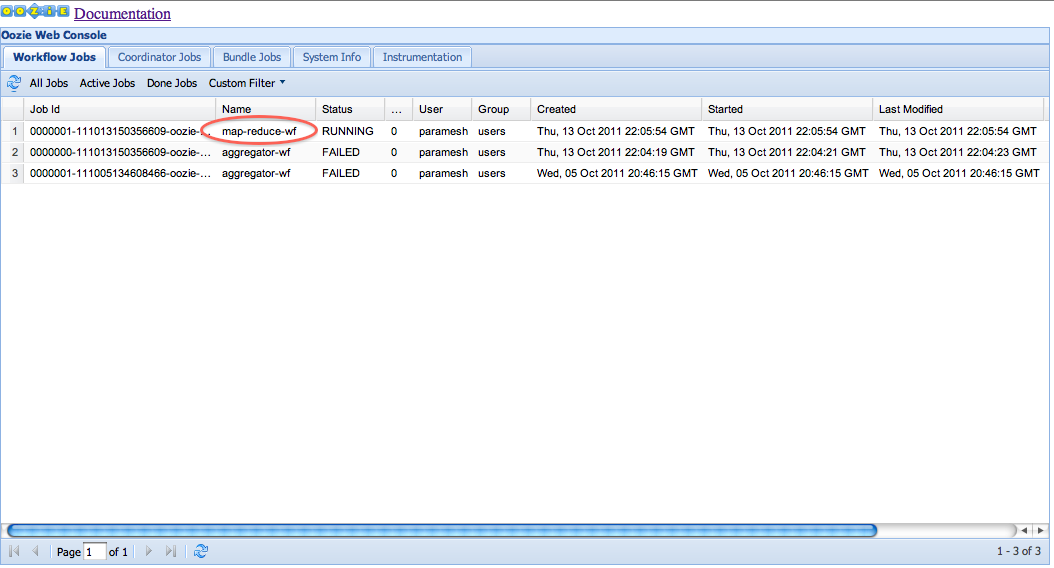
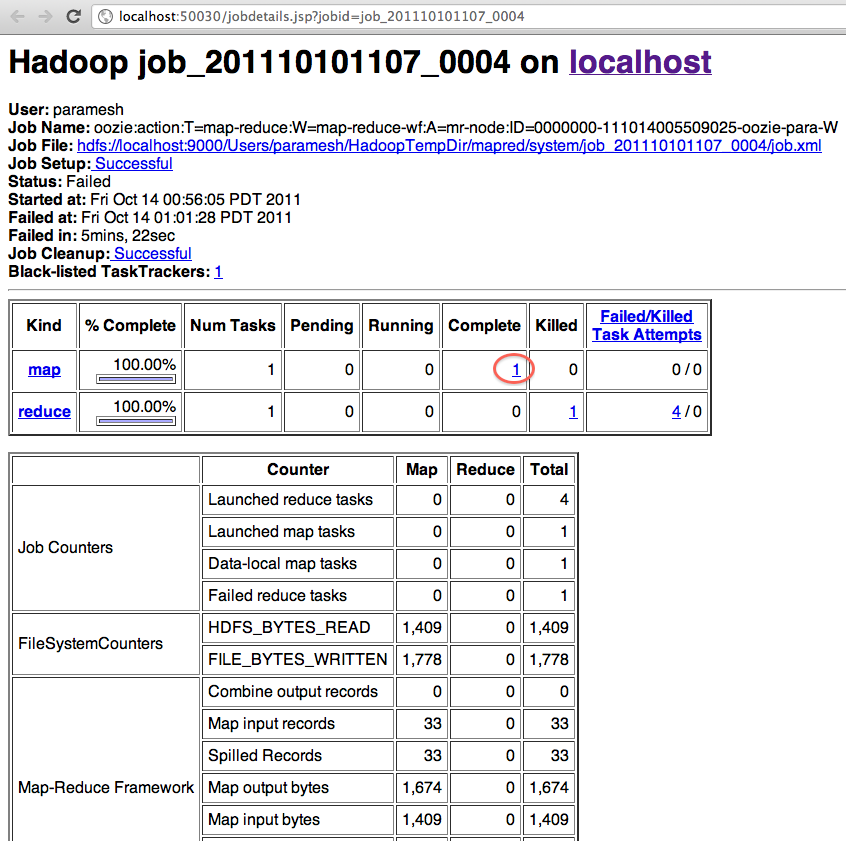
Clicking a job displays the job details and all actions defined under it.
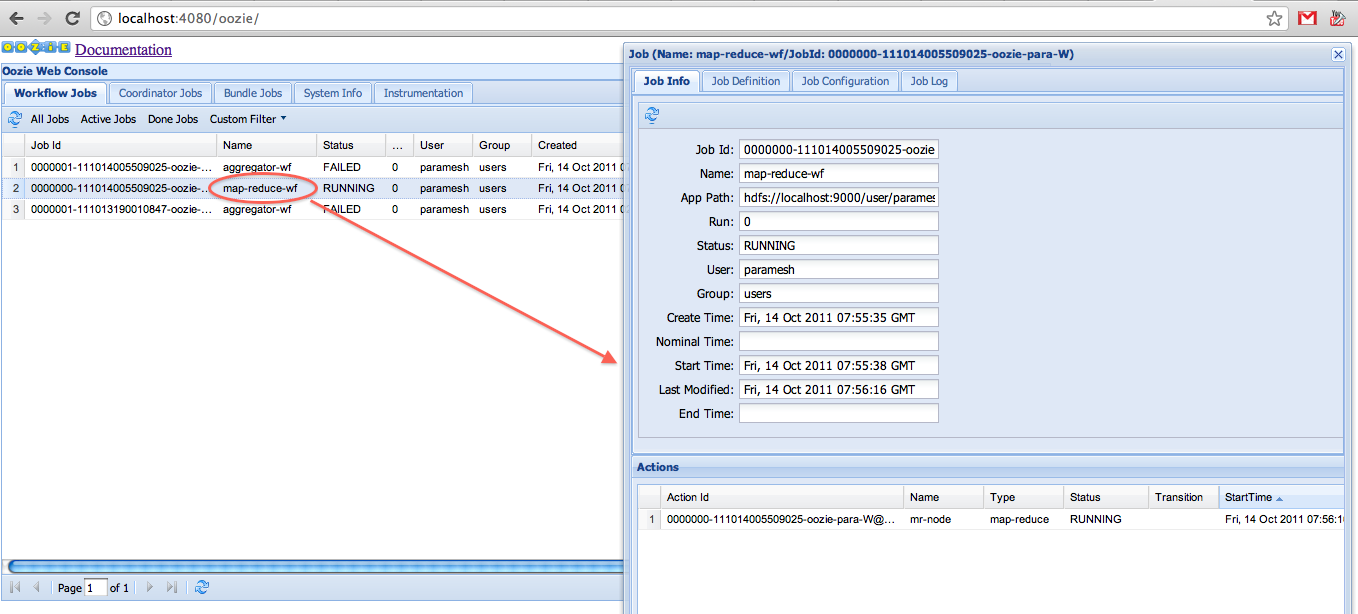
Each action could be further drilled down by clicking on the browse icon beside the Console URL field.

Hadoop job logs are available at this point and the task tracker logs can be accessed by clicking around.