


Welcome to Hadoop!
Hadoop is a software platform that lets one easily write and run applications that process vast amounts of data.
Here's what makes Hadoop especially useful:
- Scalable: Hadoop can reliably store and process petabytes.
- Economical: It distributes the data and processing across clusters of commonly available computers. These clusters can number into the thousands of nodes.
- Efficient: By distributing the data, Hadoop can process it in parallel on the nodes where the data is located. This makes it extremely rapid.
- Reliable: Hadoop automatically maintains multiple copies of data and automatically redeploys computing tasks based on failures.
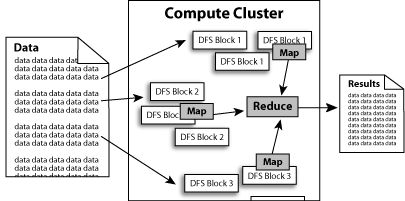
Hadoop implements MapReduce, using the Hadoop Distributed File System (HDFS) (see figure below.) MapReduce divides applications into many small blocks of work. HDFS creates multiple replicas of data blocks for reliability, placing them on compute nodes around the cluster. MapReduce can then process the data where it is located.
Hadoop has been demonstrated on clusters with 2000 nodes. The current design target is 10,000 node clusters.
Hadoop is a Lucene sub-project that contains the distributed computing platform that was formerly a part of Nutch.
For more information about Hadoop, please see the Hadoop wiki.
Getting Started
The Hadoop project plans to scale Hadoop up to handling thousands of computers. However, to begin with you can start by installing in on a single machine or a very small cluster.
- Learn about Hadoop by reading the documentation.
- Download Hadoop from the release page.
- Hadoop Quickstart.
- Hadoop Cluster Setup.
- Discuss it on the mailing list.
Getting Involved
Hadoop is an open source volunteer project under the Apache Software Foundation. We encourage you to learn about the project and contribute your expertise. Here are some starter links:
- See our How to Contribute to Hadoop page.
- Give us feedback: What can we do better?
- Join the mailing list: Meet the community.