Latest News
Create actionable knowledge from medical plain text.
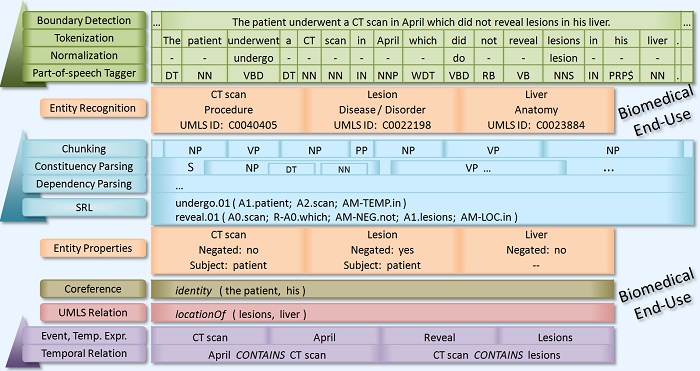
Apache cTAKES™ is a natural language processing system for extraction of information from electronic medical record clinical free-text.
Powerful
Unlock the 80% of patient information hidden within clinical documents.
Discover codable entities, temporal events, properties and relations missing from structured data.
Fast
Process individual documents with sub-second near real-time performance.
Process Database- or file-stored batches at 50,000 clinical notes per hour.*
Modular
Use only the components you need.
Fully customize pipelines to use any Apache UIMA compatible component.
Portable
Run on any major computer platform.
Embed cTAKES in any Java application or run the included GUI Tools.
Free
Download the latest 100% free and open-source release.
Contribute new ideas, data, code and modules.