Reasoners and rule engines: Jena inference support
This section of the documentation describes the current support for inference available within Jena. It includes an outline of the general inference API, together with details of the specific rule engines and configurations for RDFS and OWL inference supplied with Jena.
Not all of the fine details of the API are covered here: refer to the Jena Javadoc to get the full details of the capabilities of the API.
Note that this is a preliminary version of this document, some errors or inconsistencies are possible, feedback to the mailing lists is welcomed.
Index¶
- Overview of inference support
- The inference API
- The RDFS reasoner
- The OWL reasoner
- The transitive reasoner
- The general purpose rule engine
- Extending the inference support
- Futures
Overview of inference support¶
The Jena inference subsystem is designed to allow a range of inference engines or reasoners to be plugged into Jena. Such engines are used to derive additional RDF assertions which are entailed from some base RDF together with any optional ontology information and the axioms and rules associated with the reasoner. The primary use of this mechanism is to support the use of languages such as RDFS and OWL which allow additional facts to be inferred from instance data and class descriptions. However, the machinery is designed to be quite general and, in particular, it includes a generic rule engine that can be used for many RDF processing or transformation tasks.
We will try to use the term inference to refer to the abstract process of deriving additional information and the term reasoner to refer to a specific code object that performs this task. Such usage is arbitrary and if we slip into using equivalent terms like reasoning and inference engine please forgive us.
The overall structure of the inference machinery is illustrated below.
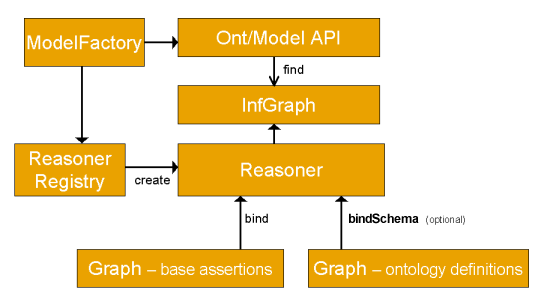
Applications normally access the inference machinery by using the ModelFactory
to associate a data set with some reasoner to create a new Model. Queries to
the created model will return not only those statements that were present in
the original data but also additional statements than can be derived from the
data using the rules or other inference mechanisms implemented by the reasoner.
As illustrated the inference machinery is actually implemented at the level
of the Graph SPI, so that any of the different Model interfaces can be constructed
around an inference Graph. In particular, the Ontology
API provides convenient ways to link appropriate reasoners into the OntModels
that it constructs. As part of the general RDF API we also provide an InfModel,
this is an extension to the normal Model interface that provides
additional control and access to an underlying inference graph.
The reasoner API supports the notion of specializing a reasoner by binding
it to a set of schema or ontology data using the bindSchema call.
The specialized reasoner can then be attached to different sets of instance
data using bind calls. In situations where the same schema information
is to be used multiple times with different sets of instance data then this
technique allows for some reuse of inferences across the different uses of the
schema. In RDF there is no strong separation between schema (aka Ontology AKA
tbox) data and instance (AKA abox) data and so any data, whether class or instance
related, can be included in either the bind or bindSchema
calls - the names are suggestive rather than restrictive.
To keep the design as open ended as possible Jena also includes a ReasonerRegistry.
This is a static class though which the set of reasoners currently available
can be examined. It is possible to register new reasoner types and to dynamically
search for reasoners of a given type. The ReasonerRegistry also
provides convenient access to prebuilt instances of the main supplied reasoners.
Available reasoners¶
Included in the Jena distribution are a number of predefined reasoners:
- Transitive reasoner: Provides support for storing and traversing class and property lattices.
This implements just the transitive and reflexive properties
of
rdfs:subPropertyOfandrdfs:subClassOf. - RDFS rule reasoner: Implements a configurable subset of the RDFS entailments.
- OWL, OWL Mini, OWL Micro Reasoners: A set of useful but incomplete implementation of the OWL/Lite subset of the OWL/Full language.
- Generic rule reasoner: A rule based reasoner that supports user defined rules. Forward chaining, tabled backward chaining and hybrid execution strategies are supported.
[index]
The Inference API¶
- Generic reasoner API
- Small examples
- Operations on inference models
- Validation
- Extended list statements
- Direct and indirect relations
- Derivations
- Accessing raw data and deductions
- Processing control
- Tracing
Generic reasoner API¶
Finding a reasoner¶
For each type of reasoner there is a factory class (which conforms to the interface
ReasonerFactory)
an instance of which can be used to create instances of the associated
Reasoner.
The factory instances can be located by going directly to a known factory class
and using the static theInstance() method or by retrieval from
a global ReasonerRegistry
which stores factory instances indexed by URI assigned to the reasoner.
In addition, there are convenience methods on the ReasonerRegistry
for locating a prebuilt instance of each of the main reasoners (getTransitiveReasoner,
getRDFSReasoner, getRDFSSimpleReasoner, getOWLReasoner, getOWLMiniReasoner, getOWLMicroReasoner).
Note that the factory objects for constructing reasoners are just there to simplify the design and extension of the registry service. Once you have a reasoner instance, the same instance can reused multiple times by binding it to different datasets, without risk of interference - there is no need to create a new reasoner instance each time.
If working with the Ontology API it is not always necessary to explicitly locate a reasoner. The prebuilt instances of OntModelSpec provide easy access to the appropriate reasoners to use for different Ontology configurations.
Similarly, if all you want is a plain RDF Model with RDFS inference included
then the convenience methods ModelFactory.createRDFSModel can be
used.
Configuring a reasoner¶
The behaviour of many of the reasoners can be configured. To allow arbitrary
configuration information to be passed to reasoners we use RDF to encode the
configuration details. The ReasonerFactory.create method can be
passed a Jena Resource object, the properties of that object will
be used to configure the created reasoner.
To simplify the code required for simple cases we also provide a direct Java
method to set a single configuration parameter, Reasoner.setParameter.
The parameter being set is identified by the corresponding configuration property.
For the built in reasoners the available configuration parameters are described
below and are predefined in the ReasonerVocabulary
class.
The parameter value can normally be a String or a structured value. For example, to set a boolean value one can use the strings "true" or "false", or in Java use a Boolean object or in RDF use an instance of xsd:Boolean
Applying a reasoner to data¶
Once you have an instance of a reasoner it can then be attached to a set of RDF data to create an inference model. This can either be done by putting all the RDF data into one Model or by separating into two components - schema and instance data. For some external reasoners a hard separation may be required. For all of the built in reasoners the separation is arbitrary. The prime value of this separation is to allow some deductions from one set of data (typically some schema definitions) to be efficiently applied to several subsidiary sets of data (typically sets of instance data).
If you want to specialize the reasoner this way, by partially-applying it to
a set schema data, use the Reasoner.bindSchema method which returns
a new, specialized, reasoner.
To bind the reasoner to the final data set to create an inference model see
the ModelFactory
methods, particularly ModelFactory.createInfModel.
Accessing inferences¶
Finally, having created a inference model then any API operations which access RDF statements will be able to access additional statements which are entailed from the bound data by means of the reasoner. Depending on the reasoner these additional virtual statements may all be precomputed the first time the model is touched, may be dynamically recomputed each time or may be computed on-demand but cached.
Reasoner description¶
The reasoners can be described using RDF metadata which can be searched to
locate reasoners with appropriate properties. The calls Reasoner.getCapabilities
and Reasoner.supportsProperty are used to access this descriptive
metadata.
[API index] [main index]
Some small examples¶
These initial examples are not designed to illustrate the power of the reasoners but to illustrate the code required to set one up.
Let us first create a Jena model containing the statements that some property "p" is a subproperty of another property "q" and that we have a resource "a" with value "foo" for "p". This could be done by writing an RDF/XML or N3 file and reading that in but we have chosen to use the RDF API:
String NS = "urn:x-hp-jena:eg/"; // Build a trivial example data set Model rdfsExample = ModelFactory.createDefaultModel(); Property p = rdfsExample.createProperty(NS, "p"); Property q = rdfsExample.createProperty(NS, "q"); rdfsExample.add(p, RDFS.subPropertyOf, q); rdfsExample.createResource(NS+"a").addProperty(p, "foo");
Now we can create an inference model which performs RDFS inference over this data by using:
InfModel inf = ModelFactory.createRDFSModel(rdfsExample); // [1]
We can then check that resulting model shows that "a" also has property "q" of value "foo" by virtue of the subPropertyOf entailment:
Resource a = inf.getResource(NS+"a"); System.out.println("Statement: " + a.getProperty(q));
Which prints the output:
Statement: [urn:x-hp-jena:eg/a, urn:x-hp-jena:eg/q, Literal<foo>]
Alternatively we could have created an empty inference model and then added in the statements directly to that model.
If we wanted to use a different reasoner which is not available as a convenience method or wanted to configure one we would change line [1]. For example, to create the same set up manually we could replace \[1\] by:
Reasoner reasoner = ReasonerRegistry.getRDFSReasoner(); InfModel inf = ModelFactory.createInfModel(reasoner, rdfsExample);
or even more manually by
Reasoner reasoner = RDFSRuleReasonerFactory.theInstance().create(null); InfModel inf = ModelFactory.createInfModel(reasoner, rdfsExample);
The purpose of creating a new reasoner instance like this variant would be to enable configuration parameters to be set. For example, if we were to listStatements on inf Model we would see that it also "includes" all the RDFS axioms, of which there are quite a lot. It is sometimes useful to suppress these and only see the "interesting" entailments. This can be done by setting the processing level parameter by creating a description of a new reasoner configuration and passing that to the factory method:
Resource config = ModelFactory.createDefaultModel() .createResource() .addProperty(ReasonerVocabulary.PROPsetRDFSLevel, "simple"); Reasoner reasoner = RDFSRuleReasonerFactory.theInstance().create(config); InfModel inf = ModelFactory.createInfModel(reasoner, rdfsExample);
This is a rather long winded way of setting a single parameter, though it can be useful in the cases where you want to store this sort of configuration information in a separate (RDF) configuration file. For hardwired cases the following alternative is often simpler:
Reasoner reasoner = RDFSRuleReasonerFactory.theInstance()Create(null); reasoner.setParameter(ReasonerVocabulary.PROPsetRDFSLevel, ReasonerVocabulary.RDFS_SIMPLE); InfModel inf = ModelFactory.createInfModel(reasoner, rdfsExample);
Finally, supposing you have a more complex set of schema information, defined in a Model called schema, and you want to apply this schema to several sets of instance data without redoing too many of the same intermediate deductions. This can be done by using the SPI level methods:
Reasoner boundReasoner = reasoner.bindSchema(schema); InfModel inf = ModelFactory.createInfModel(boundReasoner, data);
This creates a new reasoner, independent from the original, which contains the schema data. Any queries to an InfModel created using the boundReasoner will see the schema statements, the data statements and any statements entailed from the combination of the two. Any updates to the InfModel will be reflected in updates to the underlying data model - the schema model will not be affected.
[API index] [main index]
Operations on inference models¶
For many applications one simply creates a model incorporating some inference
step, using the ModelFactory methods, and then just works within
the standard Jena Model API to access the entailed statements. However, sometimes
it is necessary to gain more control over the processing or to access additional
reasoner features not available as virtual triples.
Validation¶
The most common reasoner operation which can't be exposed through additional triples in the inference model is that of validation. Typically the ontology languages used with the semantic web allow constraints to be expressed, the validation interface is used to detect when such constraints are violated by some data set.
A simple but typical example is that of datatype ranges in RDFS. RDFS allows us to specify the range of a property as lying within the value space of some datatype. If an RDF statement asserts an object value for that property which lies outside the given value space there is an inconsistency.
To test for inconsistencies with a data set using a reasoner we use the InfModel.validate()
interface. This performs a global check across the schema and instance data
looking for inconsistencies. The result is a ValidityReport object
which comprises a simple pass/fail flag (ValidityReport.isValid())
together with a list of specific reports (instances of the ValidityReport.Report
interface) which detail any detected inconsistencies. At a minimum the individual
reports should be printable descriptions of the problem but they can also contain
an arbitrary reasoner-specific object which can be used to pass additional information
which can be used for programmatic handling of the violations.
For example, to check a data set and list any problems one could do something like:
Model data = FileManager.get().loadModel(fname); InfModel infmodel = ModelFactory.createRDFSModel(data); ValidityReport validity = infmodel.validate(); if (validity.isValid()) { System.out.println("OK"); } else { System.out.println("Conflicts"); for (Iterator i = validity.getReports(); i.hasNext(); ) { System.out.println(" - " + i.next()); } }
The file testing/reasoners/rdfs/dttest2.nt declares a property
bar with range xsd:integer and attaches a bar
value to some resource with the value "25.5"^^xsd:decimal.
If we run the above sample code on this file we see:
Conflicts
- Error (dtRange): Property http://www.hpl.hp.com/semweb/2003/eg#bar has a typed range Datatype[http://www.w3.org/2001/XMLSchema#integer -> class java.math.BigInteger]that is not compatible with 25.5:http://www.w3.org/2001/XMLSchema#decimal
Whereas the file testing/reasoners/rdfs/dttest3.nt uses the value
"25"^^xsd:decimal instead, which is a valid integer and so passes.
Note that the individual validation records can include warnings as well as
errors. A warning does not affect the overall isValid() status
but may indicate some issue the application may wish to be aware of. For example,
it would be possible to develop a modification to the RDFS reasoner which warned
about use of a property on a resource that is not explicitly declared to have
the type of the domain of the property.
A particular case of this arises in the case of OWL. In the Description Logic
community a class which cannot have an instance is regarded as "inconsistent".
That term is used because it generally arises from an error in the ontology.
However, it is not a logical inconsistency - i.e. something giving rise to a
contradiction. Having an instance of such a class is, clearly a logical error.
In the Jena 2.2 release we clarified the semantics of isValid().
An ontology which is logically consistent but contains empty classes is regarded
as valid (that is isValid() is false only if there is a logical
inconsistency). Class expressions which cannot be instantiated are treated as
warnings rather than errors. To make it easier to test for this case there is
an additional method Report.isClean() which returns true if the
ontology is both valid (logically consistent) and generated no warnings (such
as inconsistent classes).
Extended list statements¶
The default API supports accessing all entailed information at the level of individual triples. This is surprisingly flexible but there are queries which cannot be easily supported this way. The first such is when the query needs to make reference to an expression which is not already present in the data. For example, in description logic systems it is often possible to ask if there are any instances of some class expression. Whereas using the triple-based approach we can only ask if there are any instances of some class already defined (though it could be defined by a bNode rather than be explicitly named).
To overcome this limitation the InfModel API supports a notion
of "posit", that is a set of assertions which can be used to temporarily
declare new information such as the definition of some class expression. These
temporary assertions can then be referenced by the other arguments to the listStatements
command. With the current reasoners this is an expensive operation, involving
the temporary creation of an entire new model with the additional posits added
and all inference has to start again from scratch. Thus it is worth considering
preloading your data with expressions you might need to query over. However,
for some external reasoners, especially description logic reasoners, we anticipate
restricted uses of this form of listStatement will be important.
Direct and indirect relationships¶
The second type of operation that is not obviously convenient at the triple level involves distinguishing between direct and indirect relationships. If a relation is transitive, for example rdfs:subClassOf, then we can define the notion of the minimal or direct form of the relationship from which all other values of the relation can be derived by transitive closure.
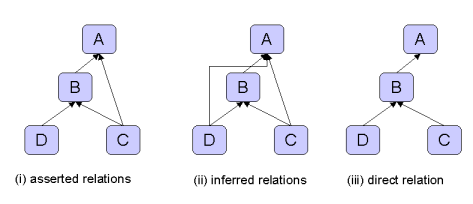
Normally, when an InfGraph is queried for a transitive relation the results
returned show the inferred relations, i.e. the full transitive closure (all
the links (ii) in the illustration). However, in some cases, such when as building
a hierarchical UI widget to represent the graph, it is more convenient to only
see the direct relations (iii). This is achieved by defining special direct
aliases for those relations which can be queried this way. For the built in
reasoners this functionality is available for rdfs:subClassOf and
rdfs:subPropertyOf and the direct aliases for these are defined
in ReasonerVocabulary.
Typically the easiest way to work with such indirect and direct relations is to use the Ontology API which hides the grubby details of these property aliases.
Derivations¶
It is sometimes useful to be able to trace where an inferred statement was
generated from. This is achieved using the InfModel.getDerivation(Statement)
method. This returns a iterator over a set Derviation
objects through which a brief description of the source of the derivation can
be obtained. Typically understanding this involves tracing the sources for other
statements which were used in this derivation and the Derivation.PrintTrace
method is used to do this recursively.
The general form of the Derivation objects is quite abstract but in the case
of the rule-based reasoners they have a more detailed internal structure that
can be accessed - see RuleDerivation.
Derviation information is rather expensive to compute and store. For this reason,
it is not recorded by default and InfModel.serDerivationLogging(true)
must be used to enable derivations to be recorded. This should be called before
any queries are made to the inference model.
As an illustration suppose that we have a raw data model which asserts three triples:
eg:A eg:p eg:B . eg:B eg:p eg:C . eg:C eg:p eg:D .
and suppose that we have a trivial rule set which computes the transitive closure over relation eg:p
String rules = "[rule1: (?a eg:p ?b) (?b eg:p ?c) -> (?a eg:p ?c)]"; Reasoner reasoner = new GenericRuleReasoner(Rule.parseRules(rules)); reasoner.setDerivationLogging(true); InfModel inf = ModelFactory.createInfModel(reasoner, rawData);
Then we can query whether eg:A is related through eg:p to eg:D and list the derivation route using the following code fragment:
PrintWriter out = new PrintWriter(System.out); for (StmtIterator i = inf.listStatements(A, p, D); i.hasNext(); ) { Statement s = i.nextStatement(); System.out.println("Statement is " + s); for (Iterator id = inf.getDerivation(s); id.hasNext(); ) { Derivation deriv = (Derivation) id.next(); deriv.printTrace(out, true); } } out.flush();
Which generates the output:
Statement is [urn:x-hp:eg/A, urn:x-hp:eg/p, urn:x-hp:eg/D]
Rule rule1 concluded (eg:A eg:p eg:D) <-
Fact (eg:A eg:p eg:B)
Rule rule1 concluded (eg:B eg:p eg:D) <-
Fact (eg:B eg:p eg:C)
Fact (eg:C eg:p eg:D)
Accessing raw data and deductions¶
From an InfModel it is easy to retrieve the original, unchanged,
data over which the model has been computed using the getRawModel()
call. This returns a model equivalent to the one used in the initial bind
call. It might not be the same Java object but it uses the same Java object
to hold the underlying data graph.
Some reasoners, notably the forward chaining rule engine, store the deduced
statements in a concrete form and this set of deductions can be obtained separately
by using the getDeductionsModel() call.
Processing control¶
Having bound a Model into an InfModel by using a
Reasoner its content can still be changed by the normal add
and remove calls to the InfModel. Any such change
the model will usually cause all current deductions and temporary rules to be
discarded and inference will start again from scratch at the next query. Some
reasoners, such as the RETE-based forward rule engine, can work incrementally.
In the non-incremental case then the processing will not be started until a
query is made. In that way a sequence of add and removes can be undertaken without
redundant work being performed at each change. In some applications it can be
convenient to trigger the initial processing ahead of time to reduce the latency
of the first query. This can be achieved using the InfModel.prepare()
call. This call is not necessary in other cases, any query will automatically
trigger an internal prepare phase if one is required.
There are times when the data in a model bound into an InfModel can is changed
"behind the scenes" instead of through calls to the InfModel. If this
occurs the result of future queries to the InfModel are unpredictable. To overcome
this and force the InfModel to reconsult the raw data use the InfModel.rebind()
call.
Finally, some reasoners can store both intermediate and final query results
between calls. This can substantially reduce the cost of working with the inference
services but at the expense of memory usage. It is possible to force an InfModel
to discard all such cached state by using the InfModel.reset()
call. It there are any outstanding queries (i.e. StmtIterators which have not
been read to the end yet) then those will be aborted (the next hasNext() call
will return false).
Tracing¶
When developing new reasoner configurations, especially new rule sets for the
rule engines, it is sometimes useful to be able to trace the operations of the
associated inference engine. Though, often this generates too much information
to be of use and selective use of the print builtin can be more
effective.
Tracing is not supported by a convenience API call but, for those reasoners that support it, it can be enabled using:
reasoner.setParameter(ReasonerVocabulary.PROPtraceOn, Boolean.TRUE);
Dynamic tracing control is sometimes possible on the InfModel itself by retrieving
its underlying InfGraph and calling setTraceOn() call. If you need
to make use of this see the full javadoc for the relevant InfGraph implementation.
[API index] [main index]
The RDFS reasoner¶
- RDFS reasoner - introduction and coverage
- RDFS Configuration
- RDFS Example
- RDFS implementation and performance notes
RDFS reasoner - intro and coverage¶
Jena includes an RDFS reasoner (RDFSRuleReasoner) which supports
almost all of the RDFS entailments described by the RDF Core working group [RDF
Semantics]. The only omissions are deliberate and are described below.
This reasoner is accessed using ModelFactory.createRDFSModel or
manually via ReasonerRegistery.getRDFSReasoner().
During the preview phases of Jena experimental RDFS reasoners were released, some of which are still included in the code base for now but applications should not rely on their stability or continued existence.
When configured in full mode (see below for configuration information) then the RDFS reasoner implements all RDFS entailments except for the bNode closure rules. These closure rules imply, for example, that for all triples of the form:
eg:a eg:p nnn^^datatype .
we should introduce the corresponding blank nodes:
eg:a eg:p _:anon1 . _:anon1 rdf:type datatype .
Whilst such rules are both correct and necessary to reduce RDF datatype entailment down to simple entailment they are not useful in implementation terms. In Jena simple entailment can be implemented by translating a graph containing bNodes to an equivalent query containing variables in place of the bNodes. Such a query is can directly match the literal node and the RDF API can be used to extract the datatype of the literal. The value to applications of directly seeing the additional bNode triples, even in virtual triple form, is negligible and so this has been deliberately omitted from the reasoner.
[RDFS index] [main index]
RDFS configuration¶
The RDFSRuleReasoner can be configured to work at three different compliance levels:
- Full
- This implements all of the RDFS axioms and closure rules with the exception of bNode entailments and datatypes (rdfD 1). See above for comments on these. This is an expensive mode because all statements in the data graph need to be checked for possible use of container membership properties. It also generates type assertions for all resources and properties mentioned in the data (rdf1, rdfs4a, rdfs4b).
- Default
- This omits the expensive checks for container membership properties and
the "everything is a resource" and "everything used as a property
is one" rules (rdf1, rdfs4a, rdfs4b). The latter information is available
through the Jena API and creating virtual triples to this effect has little
practical value.
This mode does include all the axiomatic rules. Thus, for example, even querying an "empty" RDFS InfModel will return triples such as[rdf:type rdfs:range rdfs:Class]. - Simple
- This implements just the transitive closure of subPropertyOf and subClassOf relations, the domain and range entailments and the implications of subPropertyOf and subClassOf. It omits all of the axioms. This is probably the most useful mode but is not the default because it is a less complete implementation of the standard.
The level can be set using the setParameter call, e.g.
reasoner.setParameter(ReasonerVocabulary.PROPsetRDFSLevel, ReasonerVocabulary.RDFS_SIMPLE);
or by constructing an RDF configuration description and passing that to the RDFSRuleReasonerFactory e.g.
Resource config = ModelFactory.createDefaultModel() .createResource() .addProperty(ReasonerVocabulary.PROPsetRDFSLevel, "simple"); Reasoner reasoner = RDFSRuleReasonerFactory.theInstance()Create(config);
Summary of parameters¶
| Parameter | Values | Description |
|
PROPsetRDFSLevel
|
"full", "default", "simple" |
Sets the RDFS processing level as described above.
|
|
PROPenableCMPScan
|
Boolean |
If true forces a preprocessing pass which finds all usages
of rdf:_n properties and declares them as ContainerMembershipProperties.
This is implied by setting the level parameter to "full" and
is not normally used directly.
|
|
PROPtraceOn
|
Boolean |
If true switches on exhaustive tracing of rule executions
to the log4j info appender.
|
|
PROPderivationLogging
|
Boolean |
If true causes derivation routes to be recorded internally
so that future getDerivation calls can return useful information.
|
[RDFS index] [main index]
RDFS Example¶
As a complete worked example let us create a simple RDFS schema, some instance data and use an instance of the RDFS reasoner to query the two.
We shall use a trivial schema:
<rdf:Description rdf:about="&eg;mum"> <rdfs:subPropertyOf rdf:resource="&eg;parent"/> </rdf:Description> <rdf:Description rdf:about="&eg;parent"> <rdfs:range rdf:resource="&eg;Person"/> <rdfs:domain rdf:resource="&eg;Person"/> </rdf:Description> <rdf:Description rdf:about="&eg;age"> <rdfs:range rdf:resource="&xsd;integer" /> </rdf:Description>
This defines a property parent from Person to Person,
a sub-property mum of parent and an integer-valued
property age.
We shall also use the even simpler instance file:
<Teenager rdf:about="&eg;colin"> <mum rdf:resource="&eg;rosy" /> <age>13</age> </Teenager>
Which defines a Teenager called colin who has a mum
rosy and an age of 13.
Then the following code fragment can be used to read files containing these
definitions, create an inference model and query it for information on the rdf:type
of colin and the rdf:type of Person:
Model schema = FileManager.get().loadModel("file:data/rdfsDemoSchema.rdf"); Model data = FileManager.get().loadModel("file:data/rdfsDemoData.rdf"); InfModel infmodel = ModelFactory.createRDFSModel(schema, data); Resource colin = infmodel.getResource("urn:x-hp:eg/colin"); System.out.println("colin has types:"); printStatements(infmodel, colin, RDF.type, null); Resource Person = infmodel.getResource("urn:x-hp:eg/Person"); System.out.println("\nPerson has types:"); printStatements(infmodel, Person, RDF.type, null);
This produces the output:
colin has types: - (eg:colin rdf:type eg:Teenager) - (eg:colin rdf:type rdfs:Resource) - (eg:colin rdf:type eg:Person) Person has types: - (eg:Person rdf:type rdfs:Class) - (eg:Person rdf:type rdfs:Resource)
This says that colin is both a Teenager (by direct
definition), a Person (because he has a mum which
means he has a parent and the domain of parent is
Person) and an rdfs:Resource. It also says that Person
is an rdfs:Class, even though that wasn't explicitly in the schema,
because it is used as object of range and domain statements.
If we add the additional code:
ValidityReport validity = infmodel.validate();
if (validity.isValid()) {
System.out.println("\nOK");
} else {
System.out.println("\nConflicts");
for (Iterator i = validity.getReports(); i.hasNext(); ) {
ValidityReport.Report report = (ValidityReport.Report)i.next();
System.out.println(" - " + report);
}
}
Then we get the additional output:
Conflicts - Error (dtRange): Property urn:x-hp:eg/age has a typed range Datatype[http://www.w3.org/2001/XMLSchema#integer -> class java.math.BigInteger] that is not compatible with 13
because the age was given using an RDF plain litera where as the schema requires it to be a datatyped literal which is compatible with xsd:integer.
[RDFS index] [main index]
RDFS implementation and performance notes¶
The RDFSRuleReasoner is a hybrid implementation. The subproperty and subclass
lattices are eagerly computed and stored in a compact in-memory form using the
TransitiveReasoner (see below). The identification of which container membership
properties (properties like rdf:_1) are present is implemented using a preprocessing
hook. The rest of the RDFS operations are implemented by explicit rule sets
executed by the general hybrid rule reasoner. The three different processing
levels correspond to different rule sets. These rule sets are located by looking
for files "etc/*.rules" on the classpath and so could,
in principle, be overridden by applications wishing to modify the rules.
Performance for in-memory queries appears to be good. Using a synthetic dataset we obtain the following times to determine the extension of a class from a class hierarchy:
| Set | #concepts | total instances | #instances of concept | JenaRDFS | XSB |
| 1 | 155 | 1550 | 310 | 0.07 | 0.16 |
| 2 | 780 | 7800 | 1560 | 0.25 | 0.47 |
| 3 | 3905 | 39050 | 7810 | 1.16 | 2.11 |
The times are in seconds, normalized to a 1.1GHz Pentium processor. The XSB figures are taken from a pre-published paper and may not be directly comparable (for example they do not include any rule compilation time) - they are just offered to illustrate that the RDFSRuleReasoner has broadly similar scaling and performance to other rule-based implementations.
The Jena RDFS implementation has not been tested and evaluated over database models. The Jena architecture makes it easy to construct such models but in the absence of caching we would expect the performance to be poor. Future work on adapting the rule engines to exploit the capabilities of the more sophisticated database backends will be considered.
[RDFS index] [main index]
The OWL reasoner¶
The second major set of reasoners supplied with Jena is a rule-based implementation of the OWL/lite subset of OWL/full.
The current release includes a default OWL reasoner and two small/faster configurations. Each of the configurations is intended to be a sound implementation of a subset of OWL/full semantics but none of them is complete (in the technical sense). For complete OWL DL reasoning use an external DL reasoner such as Pellet, Racer or FaCT. Performance (especially memory use) of the fuller reasoner configuration still leaves something to be desired and will the subject of future work - time permitting.
See also subsection 5 for notes on more specific limitations of the current implementation.
OWL coverage¶
The Jena OWL reasoners could be described as instance-based reasoners. That is, they work by using rules to propagate the if- and only-if- implications of the OWL constructs on instance data. Reasoning about classes is done indirectly - for each declared class a prototypical instance is created and elaborated. If the prototype for a class A can be deduced as being a member of class B then we conclude that A is a subClassOf B. This approach is in contrast to more sophisticated Description Logic reasoners which work with class expressions and can be less efficient when handling instance data but more efficient with complex class expressions and able to provide complete reasoning.
We thus anticipate that the OWL rule reasoner will be most suited to applications involving primarily instance reasoning with relatively simple, regular ontologies and least suited to applications involving large rich ontologies. A better characterisation of the tradeoffs involved would be useful and will be sought.
We intend that the OWL reasoners should be smooth extensions of the RDFS reasoner described above. That is all RDFS entailments found by the RDFS reasoner will also be found by the OWL reasoners and scaling on RDFS schemas should be similar (though there are some costs, see later). The instance-based implementation technique is in keeping with this "RDFS plus a bit" approach.
Another reason for choosing this inference approach is that it makes it possible to experiment with support for different constructs, including constructs that go beyond OWL, by modification of the rule set. In particular, some applications of interest to ourselves involve ontology transformation which very often implies the need to support property composition. This is something straightforward to express in rule-based form and harder to express in standard Description Logics.
Since RDFS is not a subset of the OWL/Lite or OWL/DL languages the Jena implementation
is an incomplete implementation of OWL/full. We provide three implementations
a default ("full" one), a slightly cut down "mini" and a
rather smaller/faster "micro". The default OWL rule reasoner (ReasonerRegistry.getOWLReasoner())
supports the constructs as listed below. The OWLMini reasoner is nearly the
same but omits the forward entailments from minCardinality/someValuesFrom restrictions
- that is it avoids introducing bNodes which avoids some infinite expansions
and enables it to meet the Jena API contract more precisely. The OWLMicro reasoner
just supports RDFS plus the various property axioms, intersectionOf, unionOf
(partial) and hasValue. It omits the cardinality restrictions and equality axioms,
which enables it to achieve much higher performance.
| Constructs | Supported by | Notes |
|
rdfs:subClassOf, rdfs:subPropertyOf, rdf:type
|
all |
Normal RDFS semantics supported including meta use (e.g.
taking the subPropertyOf subClassOf).
|
|
rdfs:domain, rdfs:range
|
all |
Stronger if-and-only-if semantics supported
|
|
owl:intersectionOf
|
all | |
|
owl:unionOf
|
all |
Partial support. If C=unionOf(A,B) then will infer that
A,B are subclasses of C, and thus that instances of A or B are instances
of C. Does not handle the reverse (that an instance of C must be either
an instance of A or an instance of B).
|
|
owl:equivalentClass
|
all | |
|
owl:disjointWith
|
full, mini | |
|
owl:sameAs, owl:differentFrom, owl:distinctMembers
|
full, mini |
owl:distinctMembers is currently translated into a quadratic
set of owl:differentFrom assertions.
|
|
Owl:Thing
|
all | |
|
owl:equivalentProperty, owl:inverseOf
|
all | |
|
owl:FunctionalProperty, owl:InverseFunctionalProperty
|
all | |
|
owl:SymmeticProperty, owl:TransitiveProperty
|
all | |
|
owl:someValuesFrom
|
full, (mini) |
Full supports both directions (existence of a value implies membership
of someValuesFrom restriction, membership of someValuesFrom implies
the existence of a bNode representing the value). |
|
owl:allValuesFrom
|
full, mini |
Partial support, forward direction only (member of a allValuesFrom(p,
C) implies that all p values are of type C). Does handle cases where the
reverse direction is trivially true (e.g. by virtue of a global rdfs:range
axiom).
|
|
owl:minCardinality, owl:maxCardinality, owl:cardinality
|
full, (mini) |
Restricted to cardinalities of 0 or 1, though higher cardinalities
are partially supported in validation for the case of literal-valued
properties. |
|
owl:hasValue
|
all |
The critical constructs which go beyond OWL/lite and are not supported in the Jena OWL reasoner are complementOf and oneOf. As noted above the support for unionOf is partial (due to limitations of the rule based approach) but is useful for traversing class hierarchies.
Even within these constructs rule based implementations are limited in the extent to which they can handle equality reasoning - propositions provable by reasoning over concrete and introduced instances are covered but reasoning by cases is not supported.
Nevertheless, the full reasoner passes the normative OWL working group positive and negative entailment tests for the supported constructs, though some tests need modification for the comprehension axioms (see below).
The OWL rule set does include incomplete support for validation of datasets using the above constructs. Specifically, it tests for:
- Illegal existence of a property restricted by a maxCardinality(0) restriction.
- Two individuals both sameAs and differentFrom each other.
- Two classes declared as disjoint but where one subsumes the other (currently reported as a violation concerning the class prototypes, error message to be improved).
- Range or a allValuesFrom violations for DatatypeProperties.
- Too many literal-values for a DatatypeProperty restricted by a maxCardinality(N) restriction.
[OWL index] [main index]
OWL Configuration¶
This reasoner is accessed using ModelFactory.createOntologyModel
with the prebuilt OntModelSpec
OWL_MEM_RULE_INF or manually via ReasonerRegistery.getOWLReasoner().
There are no OWL-specific configuration parameters though the reasoner supports the standard control parameters:
| Parameter | Values | Description |
|
PROPtraceOn
|
boolean |
If true switches on exhaustive tracing of rule executions
to the log4j info appender.
|
|
PROPderivationLogging
|
Boolean |
If true causes derivation routes to be recorded internally
so that future getDerivation calls can return useful information.
|
As we gain experience with the ways in which OWL is used and the capabilities of the rule-based approach we imagine useful subsets of functionality emerging - like that supported by the RDFS reasoner in the form of the level settings.
[OWL index] [main index]
OWL Example¶
As an example of using the OWL inference support, consider the sample schema and data file in the data directory - owlDemoSchema.xml and owlDemoData.xml.
The schema file shows a simple, artificial ontology concerning computers which defines a GamingComputer as a Computer which includes at least one bundle of type GameBundle and a component with the value gamingGraphics.
The data file shows information on several hypothetical computer configurations
including two different descriptions of the configurations "whiteBoxZX"
and "bigName42".
We can create an instance of the OWL reasoner, specialized to the demo schema and then apply that to the demo data to obtain an inference model, as follows:
Model schema = FileManager.get().loadModel("file:data/owlDemoSchema.owl"); Model data = FileManager.get().loadModel("file:data/owlDemoData.rdf"); Reasoner reasoner = ReasonerRegistry.getOWLReasoner(); reasoner = reasoner.bindSchema(schema); InfModel infmodel = ModelFactory.createInfModel(reasoner, data);
A typical example operation on such a model would be to find out all we know
about a specific instance, for example the nForce mother board.
This can be done using:
Resource nForce = infmodel.getResource("urn:x-hp:eg/nForce"); System.out.println("nForce *:"); printStatements(infmodel, nForce, null, null);
where printStatements is defined by:
public void printStatements(Model m, Resource s, Property p, Resource o) { for (StmtIterator i = m.listStatements(s,p,o); i.hasNext(); ) { Statement stmt = i.nextStatement(); System.out.println(" - " + PrintUtil.print(stmt)); } }
This produces the output:
nForce *: - (eg:nForce rdf:type owl:Thing) - (eg:nForce owl:sameAs eg:unknownMB) - (eg:nForce owl:sameAs eg:nForce) - (eg:nForce rdf:type eg:MotherBoard) - (eg:nForce rdf:type rdfs:Resource) - (eg:nForce rdf:type a3b24:f7822755ad:-7ffd) - (eg:nForce eg:hasGraphics eg:gamingGraphics) - (eg:nForce eg:hasComponent eg:gamingGraphics)
Note that this includes inferences based on subClass inheritance (being an
eg:MotherBoard implies it is an owl:Thing and an rdfs:Resource),
property inheritance (eg:hasComponent eg:gameGraphics derives from
hasGraphics being a subProperty of hasComponent) and
cardinality reasoning (it is the sameAs eg:unknownMB because computers
are defined to have only one motherboard and the two different descriptions
of whileBoxZX use these two different terms for the mother board).
The anonymous rdf:type statement references the "hasValue(eg:hasComponent,
eg:gamingGraphics)" restriction mentioned in the definition of GamingComputer.
A second, typical operation is instance recognition. Testing if an individual
is an instance of a class expression. In this case the whileBoxZX
is identifiable as a GamingComputer because it is a Computer,
is explicitly declared as having an appropriate bundle and can be inferred to
have a gamingGraphics component from the combination of the nForce
inferences we've already seen and the transitivity of hasComponent.
We can test this using:
Resource gamingComputer = infmodel.getResource("urn:x-hp:eg/GamingComputer"); Resource whiteBox = infmodel.getResource("urn:x-hp:eg/whiteBoxZX"); if (infmodel.contains(whiteBox, RDF.type, gamingComputer)) { System.out.println("White box recognized as gaming computer"); } else { System.out.println("Failed to recognize white box correctly"); }
Which generates the output:
White box recognized as gaming computer
Finally, we can check for inconsistencies within the data by using the validation interface:
ValidityReport validity = infmodel.validate(); if (validity.isValid()) { System.out.println("OK"); } else { System.out.println("Conflicts"); for (Iterator i = validity.getReports(); i.hasNext(); ) { ValidityReport.Report report = (ValidityReport.Report)i.next(); System.out.println(" - " + report); } }
Which generates the output:
Conflicts - Error (conflict): Two individuals both same and different, may be due to disjoint classes or functional properties Culprit = eg:nForce2 Implicated node: eg:bigNameSpecialMB ... + 3 other similar reports
This is due to the two records for the bigName42 configuration
referencing two motherboards which are explicitly defined to be different resources
and thus violate the FunctionProperty nature of hasMotherBoard.
[OWL index] [main index]
OWL notes and limitations¶
Comprehension axioms¶
A critical implication of our variant of the instance-based approach is that the reasoner does not directly answer queries relating to dynamically introduced class expressions.
For example, given a model containing the RDF assertions corresponding to the two OWL axioms:
class A = intersectionOf (minCardinality(P, 1), maxCardinality(P,1)) class B = cardinality(P,1)
Then the reasoner can demonstrate that classes A and B are equivalent, in particular that any instance of A is an instance of B and vice versa. However, given a model just containing the first set of assertions you cannot directly query the inference model for the individual triples that make up cardinality(P,1). If the relevant class expressions are not already present in your model then you need to use the list-with-posits mechanism described above, though be warned that such posits start inference afresh each time and can be expensive.
Actually, it would be possible to introduce comprehension axioms for simple cases like this example. We have, so far, chosen not to do so. First, since the OWL/full closure is generally infinite, some limitation on comprehension inferences seems to be useful. Secondly, the typical queries that Jena applications expect to be able to issue would suddenly jump in size and cost - causing a support nightmare. For example, queries such as (a, rdf:type, *) would become near-unusable.
Approximately, 10 of the OWL working group tests for the supported OWL subset
currently rely on such comprehension inferences. The shipping version of the
Jena rule reasoner passes these tests only after they have been rewritten to
avoid the comprehension requirements.
Prototypes¶
As noted above the current OWL rule set introduces prototypical instances for each defined class. These prototypical instances used to be visible to queries. From release 2.1 they are used internally but should not longer be visible.
Direct/indirect¶
We noted above that the Jena reasoners support a separation of direct and indirect relations for transitive properties such as subClassOf. The current implementation of the full and mini OWL reasoner fails to do this and the direct forms of the queries will fail. The OWL Micro reasoner, which is but a small extension of RDFS, does support the direct queries.
This does not affect querying though the Ontology API, which works around this limitation. It only affects direct RDF accesses to the inference model.
Performance¶
The OWL reasoners use the rule engines for all inference. The full and mini configurations omit some of the performance tricks employed by the RDFS reasoner (notably the use of the custom transitive reasoner) making those OWL reasoner configurations slower than the RDFS reasoner on pure RDFS data (typically around x3-4 slow down). The OWL Micro reasoner is intended to be as close to RDFS performance while also supporting the core OWL constructs as described earlier.
Once the owl constructs are used then substantial reasoning can be required. The most expensive aspect of the supported constructs is the equality reasoning implied by use of cardinality restrictions and FunctionalProperties. The current rule set implements equality reasoning by identifying all sameAs deductions during the initial forward "prepare" phase. This may require the entire instance dataset to be touched several times searching for occurrences of FunctionalProperties.
Beyond this the rules implementing the OWL constructs can interact in complex ways leading to serious performance overheads for complex ontologies. Characterising the sorts of ontologies and inference problems that are well tackled by this sort of implementation and those best handled by plugging a Description Logic engine, or a saturation theorem prover, into Jena is a topic for future work.
One random hint: explicitly importing the owl.owl definitions causes much duplication of rule use and a substantial slow down - the OWL axioms that the reasoner can handle are already built in and don't need to be redeclared.
Incompleteness¶
The rule based approach cannot offer a complete solution for OWL/Lite, let alone the OWL/Full fragment corresponding to the OWL/Lite constructs. In addition the current implementation is still under development and may well have ommissions and oversights. We intend that the reasoner should be sound (all inferred triples should be valid) but not complete.
[OWL index] [main index]
The transitive reasoner¶
The TransitiveReasoner provides support for storing and traversing class and
property lattices. This implements just the transitive and symmetric
properties of rdfs:subPropertyOf and rdfs:subClassOf.
It is not all that exciting on its own but is one of the building blocks used
for the more complex reasoners. It is a hardwired Java implementation that stores
the class and property lattices as graph structures. It is slightly higher performance,
and somewhat more space efficient, than the alternative of using the pure rule
engines to performance transitive closure but its main advantage is that it
implements the direct/minimal version of those relations as well as the transitively
closed version.
The GenericRuleReasoner (see below) can optionally use an instance
of the transitive reasoner for handling these two properties. This is the approach
used in the default RDFS reasoner.
It has no configuration options.
[Index]
The general purpose rule engine¶
- Overview of the rule engine(s)
- Rule syntax and structure
- Forward chaining engine
- Backward chaining engine
- Hybrid engine
- GenericRuleReasoner configuration
- Builtin primitives
- Example
- Combining RDFS/OWL with custom rules
- Notes
- Extensions
Overview of the rule engine(s)¶
Jena includes a general purpose rule-based reasoner which is used to implement both the RDFS and OWL reasoners but is also available for general use. This reasoner supports rule-based inference over RDF graphs and provides forward chaining, backward chaining and a hybrid execution model. To be more exact, there are two internal rule engines one forward chaining RETE engine and one tabled datalog engine - they can be run separately or the forward engine can be used to prime the backward engine which in turn will be used to answer queries.
The various engine configurations are all accessible through a single parameterized
reasoner GenericRuleReasoner.
At a minimum a GenericRuleReasoner requires a ruleset to define
its behaviour. A GenericRuleReasoner instance with a ruleset can
be used like any of the other reasoners described above - that is it can be
bound to a data model and used to answer queries to the resulting inference
model.
The rule reasoner can also be extended by registering new procedural primitives. The current release includes a starting set of primitives which are sufficient for the RDFS and OWL implementations but is easily extensible.
[rule index] [main index]
Rule syntax and structure¶
A rule for the rule-based reasoner is defined by a Java Rule
object with a list of body terms (premises), a list of head terms (conclusions)
and an optional name and optional direction. Each term or ClauseEntry
is either a triple pattern, an extended triple pattern or a call to a builtin
primitive. A rule set is simply a List of Rules.
For convenience a rather simple parser is included with Rule which allows rules to be specified in reasonably compact form in text source files. However, it would be perfectly possible to define alternative parsers which handle rules encoded using, say, XML or RDF and generate Rule objects as output. It would also be possible to build a real parser for the current text file syntax which offered better error recovery and diagnostics.
An informal description of the simplified text rule syntax is:
Rule := bare-rule .
or [ bare-rule ]
or [ ruleName : bare-rule ]
bare-rule := term, ... term -> hterm, ... hterm // forward rule
or bhterm <- term, ... term // backward rule
hterm := term
or [ bare-rule ]
term := (node, node, node) // triple pattern
or (node, node, functor) // extended triple pattern
or builtin(node, ... node) // invoke procedural primitive
bhterm := (node, node, node) // triple pattern
functor := functorName(node, ... node) // structured literal
node := uri-ref // e.g. http://foo.com/eg
or prefix:localname // e.g. rdf:type
or <uri-ref> // e.g. <myscheme:myuri>
or ?varname // variable
or 'a literal' // a plain string literal
or 'lex'^^typeURI // a typed literal, xsd:* type names supported
or number // e.g. 42 or 25.5
The "," separators are optional.
The difference between the forward and backward rule syntax is only relevant for the hybrid execution strategy, see below.
The functor in an extended triple pattern is used to create and access structured literal values. The functorName can be any simple identifier and is not related to the execution of builtin procedural primitives, it is just a datastructure. It is useful when a single semantic structure is defined across multiple triples and allows a rule to collect those triples together in one place.
To keep rules readable qname syntax is supported for URI refs. The set of known
prefixes is those registered with the PrintUtil
object. This initially knows about rdf, rdfs, owl, xsd and a test namespace
eg, but more mappings can be registered in java code. In addition it is possible to
define additional prefix mappings in the rule file, see below.
Here are some example rules which illustrate most of these constructs:
[allID: (?C rdf:type owl:Restriction), (?C owl:onProperty ?P),
(?C owl:allValuesFrom ?D) -> (?C owl:equivalentClass all(?P, ?D)) ]
[all2: (?C rdfs:subClassOf all(?P, ?D)) -> print('Rule for ', ?C)
[all1b: (?Y rdf:type ?D) <- (?X ?P ?Y), (?X rdf:type ?C) ] ]
[max1: (?A rdf:type max(?P, 1)), (?A ?P ?B), (?A ?P ?C)
-> (?B owl:sameAs ?C) ]
Rule allID illustrates the functor use for collecting the components
of an OWL restriction into a single datastructure which can then fire further
rules. Rule all2 illustrates a forward rule which creates a new
backward rule and also calls the print procedural primitive. Rule
max1 illustrates use of numeric literals.
Rule files may be loaded and parsed using:
List rules = Rule.rulesFromURL("file:myfile.rules");
or
BufferedReader br = / open reader / ; List rules = Rule.parseRules( Rule.rulesParserFromReader(br) );or
String ruleSrc = / list of rules in line / List rules = Rule.parseRules( rulesSrc );In the first two cases (reading from a URL or a BufferedReader) the rule file is preprocessed by a simple processor which strips comments and supports some additional macro commands:
# ...- A comment line.
// ...- A comment line.
@prefix pre: <http://domain/url#>.- Defines a prefix
prewhich can be used in the rules. The prefix is local to the rule file. @include <urlToRuleFile>.- Includes the rules defined in the given file in this file. The included rules
will appear before the user defined rules, irrespective of where in the file
the @include directive appears. A set of special cases is supported to allow
a rule file to include the predefined rules for RDFS and OWL - in place of a real
URL for a rule file use one of the keywords
RDFSOWLOWLMicroOWLMini(case insensitive).
So an example complete rule file which includes the RDFS rules and defines a single extra rule is: # Example rule file @prefix pre: <http://jena.hpl.hp.com/prefix#>. @include <RDFS>. [rule1: (?f pre:father ?a) (?u pre:brother ?f) -> (?u pre:uncle ?a)]
[Rule index] [main index]
Forward chaining engine¶
If the rule reasoner is configured to run in forward mode then only the forward
chaining engine will be used. The first time the inference Model is queried
(or when an explicit prepare() call is made, see above)
then all of the relevant data in the model will be submitted to the rule engine.
Any rules which fire that create additional triples do so in an internal deductions
graph and can in turn trigger additional rules. There is a remove primitive
that can be used to remove triples and such removals can also trigger rules
to fire in removal mode. This cascade of rule firings continues until no more
rules can fire. It is perfectly possible, though not a good idea, to write rules
that will loop infinitely at this point.
Once the preparation phase is complete the inference graph will act as if it were the union of all the statements in the original model together with all the statements in the internal deductions graph generated by the rule firings. All queries will see all of these statements and will be of similar speed to normal model accesses. It is possible to separately access the original raw data and the set of deduced statements if required, see above.
If the inference model is changed by adding or removing statements through the normal API then this will trigger further rule firings. The forward rules work incrementally and only the consequences of the added or removed triples will be explored. The default rule engine is based on the standard RETE algorithm (C.L Forgy, RETE: A fast algorithm for the many pattern/many object pattern match problem, Artificial Intelligence 1982) which is optimized for such incremental changes.
When run in forward mode all rules are treated as forward even if they were written in backward ("<-") syntax. This allows the same rule set to be used in different modes to explore the performance tradeoffs.
There is no guarantee of the order in which matching rules will fire or the order in which body terms will be tested, however once a rule fires its head-terms will be executed in left-to-right sequence.
In forward mode then head-terms which assert backward rules (such as all1b
above) are ignored.
There are in fact two forward engines included within the Jena code base, an earlier non-RETE implementation is retained for now because it can be more efficient in some circumstances but has identical external semantics. This alternative engine is likely to be eliminated in a future release once more tuning has been done to the default RETE engine.
[Rule index] [main index]
Backward chaining engine¶
If the rule reasoner is run in backward chaining mode it uses a logic programming (LP) engine with a similar execution strategy to Prolog engines. When the inference Model is queried then the query is translated into a goal and the engine attempts to satisfy that goal by matching to any stored triples and by goal resolution against the backward chaining rules.
Except as noted below rules will be executed in top-to-bottom, left-to-right order with backtracking, as in SLD resolution. In fact, the rule language is essentially datalog rather than full prolog, whilst the functor syntax within rules does allow some creation of nested data structures they are flat (not recursive) and so can be regarded a syntactic sugar for datalog.
As a datalog language the rule syntax is a little surprising because it restricts all properties to be binary (as in RDF) and allows variables in any position including the property position. In effect, rules of the form:
(s, p, o), (s1, p1, o1) ... <- (sb1, pb1, ob1), ....
Can be thought of as being translated to datalog rules of the form:
triple(s, p, o) :- triple(sb1, pb1, ob1), ... triple(s1, p1, o1) :- triple(sb1, pb1, ob1), ... ...
where "triple/3" is a hidden implicit predicate. Internally, this transformation is not actually used, instead the rules are implemented directly.
In addition, all the data in the raw model supplied to the engine is treated
as if it were a set of triple(s,p,o) facts which are prepended to
the front of the rule set. Again, the implementation does not actually work
that way but consults the source graph, with all its storage and indexing capabilities,
directly.
Because the order of triples in a Model is not defined then this is one violation to strict top-to-bottom execution. Essentially all ground facts are consulted before all rule clauses but the ordering of ground facts is arbitrary.
Tabling¶
The LP engine supports tabling. When a goal is tabled then all previously computed matches to that goal are recorded (memoized) and used when satisfying future similar goals. When such a tabled goal is called and all known answers have been consumed then the goal will suspend until some other execution branch has generated new results and then be resumed. This allows one to successfully run recursive rules such as transitive closure which would be infinite loops in normal SLD prolog. This execution strategy, SLG, is essentially the same as that used in the well known XSB system.
In the Jena rule engine the goals to be tabled are identified by the property
field of the triple. One can request that all goals be tabled by calling the
tableAll() primitive or that all goals involving a given property
P be tabled by calling table(P). Note that if any
property is tabled then goals such as (A, ?P, ?X) will all be tabled
because the property variable might match one of the tabled properties.
Thus the rule set:
-> table(rdfs:subClassOf). [r1: (?A rdfs:subClassOf ?C) <- (?A rdfs:subClassOf ?B) (?B rdfs:subClassOf ?C)]
will successfully compute the transitive closure of the subClassOf relation. Any query of the form (, rdfs:subClassOf, ) will be satisfied by a mixture of ground facts and resolution of rule r1. Without the first line this rule would be an infinite loop.
The tabled results of each query are kept indefinitely. This means that queries
can exploit all of the results of the subgoals involved in previous queries.
In essence we build up a closure of the data set in response to successive queries.
The reset() operation on the inference model will force these tabled
results to be discarded, thus saving memory and the expense of response time
for future queries.
When the inference Model is updated by adding or removing statements all tabled
results are discarded by an internal reset() and the next query
will rebuild the tabled results from scratch.
Note that backward rules can only have one consequent so that if writing rules that might be run in either backward or forward mode then they should be limited to a single consequent each.
[Rule index] [main index]
Hybrid rule engine¶
The rule reasoner has the option of employing both of the individual rule engines in conjunction. When run in this hybrid mode the data flows look something like this:
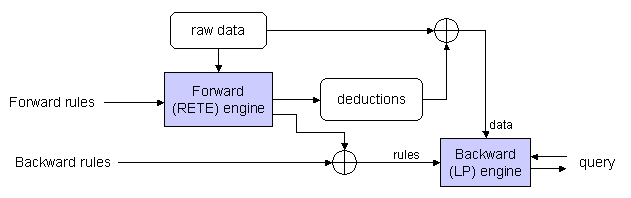
The forward engine runs, as described above, and maintains a set of inferred statements in the deductions store. Any forward rules which assert new backward rules will instantiate those rules according to the forward variable bindings and pass the instantiated rules on to the backward engine.
Queries are answered by using the backward chaining LP engine, employing the merge of the supplied and generated rules applied to the merge of the raw and deduced data.
This split allows the ruleset developer to achieve greater performance by only including backward rules which are relevant to the dataset at hand. In particular, we can use the forward rules to compile a set of backward rules from the ontology information in the dataset. As a simple example consider trying to implement the RDFS subPropertyOf entailments using a rule engine. A simple approach would involve rules like:
(?a ?q ?b) <- (?p rdfs:subPropertyOf ?q), (?a ?p ?b) .
Such a rule would work but every goal would match the head of this rule and so every query would invoke a dynamic test for whether there was a subProperty of the property being queried for. Instead the hybrid rule:
(?p rdfs:subPropertyOf ?q), notEqual(?p,?q) -> [ (?a ?q ?b) <- (?a ?p ?b) ] .
would precompile all the declared subPropertyOf relationships into simple chain rules which would only fire if the query goal references a property which actually has a sub property. If there are no subPropertyOf relationships then there will be no overhead at query time for such a rule.
Note that there are no loops in the above data flows. The backward rules are not employed when searching for matches to forward rule terms. This two-phase execution is simple to understand and keeps the semantics of the rule engines straightforward. However, it does mean that care needs to be take when formulating rules. If in the above example there were ways that the subPropertyOf relation could be derived from some other relations then that derivation would have to be accessible to the forward rules for the above to be complete.
Updates to an inference Model working in hybrid mode will discard all the tabled LP results, as they do in the pure backward case. However, the forward rules still work incrementally, including incrementally asserting or removing backward rules in response to the data changes.
[Rule index] [main index]
GenericRuleReasoner configuration¶
As with the other reasoners there are a set of parameters, identified by RDF
properties, to control behaviour of the GenericRuleReasoner. These
parameters can be set using the Reasoner.setParameter call or passed
into the Reasoner factory in an RDF Model.
The primary parameter required to instantiate a useful GenericRuleReasoner
is a rule set which can be passed into the constructor, for example:
String ruleSrc = "[rule1: (?a eg:p ?b) (?b eg:p ?c) -> (?a eg:p ?c)]"; List rules = Rule.parseRules(ruleSrc); ... Reasoner reasoner = new GenericRuleReasoner(rules);
A short cut, useful when the rules are defined in local text files using the
syntax described earlier, is the ruleSet parameter which gives
a file name which should be loadable from either the classpath or relative to
the current working directory.
Summary of parameters¶
| Parameter | Values | Description |
|
PROPruleMode
|
"forward", "forwardRETE", "backward", "hybrid" |
Sets the rule direction mode as discussed above. Default
is "hybrid".
|
|
PROPruleSet
|
filename-string |
The name of a rule text file which can be found on the
classpath or from the current directory.
|
|
PROPenableTGCCaching
|
Boolean |
If true, causes an instance of the TransitiveReasoner
to be inserted in the forward dataflow to cache the transitive closure
of the subProperty and subClass lattices.
|
|
PROPenableFunctorFiltering
|
Boolean |
If set to true, this causes the structured literals (functors)
generated by rules to be filtered out of any final queries. This allows
them to be used for storing intermediate results hidden from the view
of the InfModel's clients.
|
|
PROPenableOWLTranslation
|
Boolean |
If set to true this causes a procedural preprocessing
step to be inserted in the dataflow which supports the OWL reasoner (it
translates intersectionOf clauses into groups of backward rules in a way
that is clumsy to express in pure rule form).
|
|
PROPtraceOn
|
Boolean |
If true, switches on exhaustive tracing of rule executions
to the log4j info appender.
|
|
PROPderivationLogging
|
Boolean |
If true, causes derivation routes to be recorded internally
so that future getDerivation calls can return useful information.
|
[Rule index] [main index]
Builtin primitives¶
The procedural primitives which can be called by the rules are each implemented by a Java object stored in a registry. Additional primitives can be created and registered - see below for more details.
Each primitive can optionally be used in either the rule body, the rule head or both. If used in the rule body then as well as binding variables (and any procedural side-effects like printing) the primitive can act as a test - if it returns false the rule will not match. Primitives using in the rule head are only used for their side effects.
The set of builtin primitives available at the time writing are:
| Builtin | Operations |
|
isLiteral(?x) notLiteral(?x) |
Test whether the single argument is or is not a literal,
a functor-valued literal or a blank-node, respectively.
|
| bound(?x...) unbound(?x..) |
Test if all of the arguments are bound (not bound) variables
|
| equal(?x,?y) notEqual(?x,?y) |
Test if x=y (or x != y). The equality test is semantic
equality so that, for example, the xsd:int 1 and the xsd:decimal 1 would
test equal.
|
|
lessThan(?x, ?y), greaterThan(?x, ?y) |
Test if x is <, >, <= or >= y. Only passes
if both x and y are numbers or time instants (can be integer or
floating point or XSDDateTime).
|
|
sum(?a, ?b, ?c) |
Sets c to be (a+b), (a+1) (a-b), min(a,b), max(a,b), (ab), (a/b). Note that these
do not run backwards, if in
sum a and c are bound and b is
unbound then the test will fail rather than bind b to (c-a). This could
be fixed. |
|
strConcat(?a1, .. ?an, ?t) |
Concatenates the lexical form of all the arguments except
the last, then binds the last argument to a plain literal (strConcat) or a
URI node (uriConcat) with that lexical form. In both cases if an argument
node is a URI node the URI will be used as the lexical form.
|
|
regex(?t, ?p) |
Matches the lexical form of a literal (?t) against
a regular expression pattern given by another literal (?p).
If the match succeeds, and if there are any additional arguments then
it will bind the first n capture groups to the arguments ?m1 to ?mn.
The regular expression pattern syntax is that provided by java.util.regex.
Note that the capture groups are numbered from 1 and the first capture group
will be bound to ?m1, we ignore the implicit capture group 0 which corresponds to
the entire matched string. So for example
regexp('foo bar', '(.) (.)', ?m1, ?m2)
will bind m1 to "foo" and m2 to "bar". |
| now(?x) |
Binds ?x to an xsd:dateTime value corresponding to the current time.
|
| makeTemp(?x) |
Binds ?x to a newly created blank node.
|
| makeInstance(?x, ?p, ?v) makeInstance(?x, ?p, ?t, ?v) |
Binds ?v to be a blank node which is asserted as the value
of the ?p property on resource ?x and optionally has type ?t. Multiple
calls with the same arguments will return the same blank node each time
- thus allowing this call to be used in backward rules.
|
| makeSkolem(?x, ?v1, ... ?vn) |
Binds ?x to be a blank node. The blank node is generated
based on the values of the remain ?vi arguments, so the same combination of
arguments will generate the same bNode.
|
| noValue(?x, ?p) noValue(?x ?p ?v) |
True if there is no known triple (x, p, ) or (x, p, v)
in the model or the explicit forward deductions so far.
|
| remove(n, ...) drop(n, ...) |
Remove the statement (triple) which caused the n'th body
term of this (forward-only) rule to match. Remove will propagate the
change to other consequent rules including the firing rule (which must
thus be guarded by some other clauses).
In particular, if the removed statement (triple) appears in the body of
a rule that has already fired, the consequences of such rule are
retracted from the deducted model.
Drop will silently remove the
triple(s) from the graph but not fire any rules as a consequence.
These are clearly non-monotonic operations and, in particular, the
behaviour of a rule set in which different rules both drop and create the
same triple(s) is undefined.
|
| isDType(?l, ?t) notDType(?l, ?t) |
Tests if literal ?l is (or is not) an instance of the
datatype defined by resource ?t.
|
| print(?x, ...) |
Print (to standard out) a representation of each argument.
This is useful for debugging rather than serious IO work.
|
| listContains(?l, ?x) listNotContains(?l, ?x) |
Passes if ?l is a list which contains (does not contain) the element ?x,
both arguments must be ground, can not be used as a generator.
|
| listEntry(?list, ?index, ?val) |
Binds ?val to the ?index'th entry
in the RDF list ?list. If there is no such entry the variable will be unbound
and the call will fail. Only usable in rule bodies.
|
| listLength(?l, ?len) |
Binds ?len to the length of the list ?l.
|
| listEqual(?la, ?lb) listNotEqual(?la, ?lb) |
listEqual tests if the two arguments are both lists and contain
the same elements. The equality test is semantic equality on literals (sameValueAs) but
will not take into account owl:sameAs aliases. listNotEqual is the negation of this (passes if listEqual fails).
|
| listMapAsObject(?s, ?p ?l) listMapAsSubject(?l, ?p, ?o) |
These can only be used as actions in the head of a rule.
They deduce a set of triples derived from the list argument ?l : listMapAsObject asserts
triples (?s ?p ?x) for each ?x in the list ?l, listMapAsSubject asserts triples (?x ?p ?o).
|
| table(?p) tableAll() |
Declare that all goals involving property ?p (or all goals)
should be tabled by the backward engine.
|
| hide(p) |
Declares that statements involving the predicate p should be hidden.
Queries to the model will not report such statements. This is useful to enable non-monotonic
forward rules to define flag predicates which are only used for inference control and
do not "pollute" the inference results.
|
[Rule index] [main index]
Example¶
As a simple illustration suppose we wish to create a simple ontology language in which we can declare one property as being the concatenation of two others and to build a rule reasoner to implement this.
As a simple design we define two properties eg:concatFirst, eg:concatSecond which declare the first and second properties in a concatenation. Thus the triples:
eg:r eg:concatFirst eg:p . eg:r eg:concatSecond eg:q .
mean that the property r = p o q.
Suppose we have a Jena Model rawModel which contains the above assertions together with the additional facts:
eg:A eg:p eg:B . eg:B eg:q eg:C .
Then we want to be able to conclude that A is related to C through the composite relation r. The following code fragment constructs and runs a rule reasoner instance to implement this:
String rules =
"[r1: (?c eg:concatFirst ?p), (?c eg:concatSecond ?q) -> " +
" [r1b: (?x ?c ?y) <- (?x ?p ?z) (?z ?q ?y)] ]";
Reasoner reasoner = new GenericRuleReasoner(Rule.parseRules(rules));
InfModel inf = ModelFactory.createInfModel(reasoner, rawData);
System.out.println("A * =>");
Iterator list = inf.listStatements(A, null, (RDFNode)null);
while (list.hasNext()) {
System.out.println(" - " + list.next());
}
When run on a rawData model contain the above four triples this generates the (correct) output:
A * => - [urn:x-hp:eg/A, urn:x-hp:eg/p, urn:x-hp:eg/B] - [urn:x-hp:eg/A, urn:x-hp:eg/r, urn:x-hp:eg/C]
Example 2¶
As a second example, we'll look at ways to define a property as being both symmetric and transitive. Of course, this can be done directly in OWL but there are times when one might wish to do this outside of the full OWL rule set and, in any case, it makes for a compact illustration.
This time we'll put the rules in a separate file to simplify editing them and we'll use the machinery for configuring a reasoner using an RDF specification. The code then looks something like this:
// Register a namespace for use in the demo
String demoURI = "http://jena.hpl.hp.com/demo#";
PrintUtil.registerPrefix("demo", demoURI);
// Create an (RDF) specification of a hybrid reasoner which
// loads its data from an external file.
Model m = ModelFactory.createDefaultModel();
Resource configuration = m.createResource();
configuration.addProperty(ReasonerVocabulary.PROPruleMode, "hybrid");
configuration.addProperty(ReasonerVocabulary.PROPruleSet, "data/demo.rules");
// Create an instance of such a reasoner
Reasoner reasoner = GenericRuleReasonerFactory.theInstance().create(configuration);
// Load test data
Model data = FileManager.get().loadModel("file:data/demoData.rdf");
InfModel infmodel = ModelFactory.createInfModel(reasoner, data);
// Query for all things related to "a" by "p"
Property p = data.getProperty(demoURI, "p");
Resource a = data.getResource(demoURI + "a");
StmtIterator i = infmodel.listStatements(a, p, (RDFNode)null);
while (i.hasNext()) {
System.out.println(" - " + PrintUtil.print(i.nextStatement()));
}
Here is file data/demo.rules which defines property demo:p
as being both symmetric and transitive using pure forward rules:
[transitiveRule: (?A demo:p ?B), (?B demo:p ?C) -> (?A > demo:p ?C) ] [symmetricRule: (?Y demo:p ?X) -> (?X demo:p ?Y) ]
Running this on data/demoData.rdf gives the correct output:
- (demo:a demo:p demo:c) - (demo:a demo:p demo:a) - (demo:a demo:p demo:d) - (demo:a demo:p demo:b)
However, those example rules are overly specialized. It would be better to
define a new class of property to indicate symmetric-transitive properties and
and make demo:p a member of that class. We can generalize the rules
to support this:
[transitiveRule: (?P rdf:type demo:TransProp)(?A ?P ?B), (?B ?P ?C)
-> (?A ?P ?C) ]
[symmetricRule: (?P rdf:type demo:TransProp)(?Y ?P ?X)
-> (?X ?P ?Y) ]
These rules work but they compute the complete symmetric-transitive closure
of p when the graph is first prepared. Suppose we have a lot of p values but
only want to query some of them it would be better to compute the closure on
demand using backward rules. We could do this using the same rules run in pure
backward mode but then the rules would fire lots of times as they checked every
property at query time to see if it has been declared as a demo:TransProp.
The hybrid rule system allows us to get round this by using forward rules to
recognize any demo:TransProp declarations once and to generate
the appropriate backward rules:
-> tableAll().[rule1: (?P rdf:type demo:TransProp) -> [ (?X ?P ?Y) <- (?Y ?P ?X) ] [ (?A ?P ?C) <- (?A ?P ?B), (?B ?P ?C) ] ]
[rule index] [main index]
Combining RDFS/OWL with custom rules¶
Sometimes one wishes to write generic inference rules but combine them with some RDFS or OWL inference. With the current Jena architecture limited forms of this is possible but you need to be aware of the limitations.
There are two ways of achieving this sort of configuration within Jena (not counting using an external engine that already supports such a combination).
Firstly, it is possible to cascade reasoners, i.e. to construct one InfModel using another InfModel as the base data. The strength of this approach is that the two inference processes are separate and so can be of different sorts. For example one could create a GenericRuleReasoner whose base model is an external OWL reasoner. The chief weakness of the approach is that it is "layered" - the outer InfModel can see the results of the inner InfModel but not vice versa. For some applications that layering is fine and it is clear which way the inference should be layered, for some it is not. A second possible weakness is performance. A query to an InfModel is generally expensive and involves lots of queries to the data. The outer InfModel in our layered case will typically issue a lot of queries to the inner model, each of which may trigger more inference. If the inner model caches all of its inferences (e.g. a forward rule engine) then there may not be very much redundancy there but if not then performance can suffer dramatically.
Secondly, one can create a single GenericRuleReasoner whose rules combine rules for RDFS or OWL and custom rules. At first glance this looks like it gets round the layering limitation. However, the default Jena RDFS and OWL rulesets use the Hybrid rule engine. The hybrid engine is itself layered, forward rules do not see the results of any backward rules. Thus layering is still present though you have finer grain control - all your inferences you want the RDFS/OWL rules to see should be forward, all the inferences which need all of the results of the RDFS/OWL rules should be backward. Note that the RDFS and OWL rulesets assume certain settings for the GenericRuleReasoner so a typical configuration is:
Model data = FileManager.get().loadModel("file:data.n3"); List rules = Rule.rulesFromURL("myrules.rules"); GenericRuleReasoner reasoner = new GenericRuleReasoner(rules); reasoner.setOWLTranslation(true); // not needed in RDFS case reasoner.setTransitiveClosureCaching(true); InfModel inf = ModelFactory.createInfModel(reasoner, data);
Where the myrules.rules file will use @include to include
one of the RDFS or OWL rule sets.
One useful variant on this option, at least in simple cases, is to manually include a pure (non-hybrid) ruleset for the RDFS/OWL fragment you want so that there is no layering problem. [The reason the default rulesets use the hybrid mode is a performance tradeoff - trying to balance the better performance of forward reasoning with the cost of computing all possible answers when an application might only want a few.]
A simple example of this is that the interesting bits of RDFS can be captured by enabled TransitiveClosureCaching and including just the four core rules:
[rdfs2: (?x ?p ?y), (?p rdfs:domain ?c) -> (?x rdf:type ?c)] [rdfs3: (?x ?p ?y), (?p rdfs:range ?c) -> (?y rdf:type ?c)] [rdfs6: (?a ?p ?b), (?p rdfs:subPropertyOf ?q) -> (?a ?q ?b)] [rdfs9: (?x rdfs:subClassOf ?y), (?a rdf:type ?x) -> (?a rdf:type ?y)]
[rule index] [main index]
Notes¶
One final aspect of the general rule engine to mention is that of validation
rules. We described earlier how reasoners can implement a validate
call which returns a set of error reports and warnings about inconsistencies
in a dataset. Some reasoners (e.g. the RDFS reasoner) implement this feature
through procedural code. Others (e.g. the OWL reasoner) does so using yet more
rules.
Validation rules take the general form:
(?v rb:validation on()) ... ->
[ (?X rb:violation error('summary', 'description', args)) <- ...) ] .
First the validate call with "switch on" validation by insert an additional triple into the graph of the form:
_:anon rb:validation on() .
This makes it possible to build rules, such as the template above, which are ignored unless validation has been switched on - thus avoiding potential overhead in normal operation. This is optional and the "validation on()" guard can be omitted.
Then the validate call queries the inference graph for all triples of the form:
?x rb:violation f(summary, description, args) .
The subject resource is the "prime suspect" implicated in the inconsistency,
the relation rb:violation is a reserved property used to communicate
validation reports from the rules to the reasoner, the object is a structured
(functor-valued) literal. The name of the functor indicates the type of violation
and is normally error or warning, the first argument
is a short form summary of the type of problem, the second is a descriptive
text and the remaining arguments are other resources involved in the inconsistency.
Future extensions will improve the formatting capabilities and flexibility of this mechanism.
[Rule index] [main index]
Extensions¶
There are several places at which the rule system can be extended by application code.
Rule syntax¶
First, as mentioned earlier, the rule engines themselves only see rules in terms of the Rule Java object. Thus applications are free to define an alternative rule syntax so long as it can be compiled into Rule objects.
Builtins¶
Second, the set of procedural builtins can be extended. A builtin should implement
the Builtin
interface. The easiest way to achieve this is by subclassing BaseBuiltin
and defining a name (getName), the number of arguments expected
(getArgLength) and one or both of bodyCall and headAction.
The bodyCall method is used when the builtin is invoked in the
body of a rule clause and should return true or false according to whether the
test passes. In both cases the arguments may be variables or bound values and
the supplied RuleContext
object can be used to dereference bound variables and to bind new variables.
Once the Builtin has been defined then an instance of it needs to be registered
with BuiltinRegistry
for it to be seen by the rule parser and interpreters.
The easiest way to experiment with this is to look at the examples in the builtins directory.
Preprocessing hooks¶
The rule reasoner can optionally run a sequence of procedural preprocessing
hooks over the data at the time the inference graph is prepared. These
procedural hooks can be used to perform tests or translations which are slow
or inconvenient to express in rule form. See GenericRuleReasoner.addPreprocessingHook
and the RulePreprocessHook
class for more details.
[Index]
Extending the inference support¶
Apart from the extension points in the rule reasoner discussed above, the intention
is that it should be possible to plug external inference engines into Jena.
The core interfaces of InfGraph and Reasoner are kept
as simple and generic as we can to make this possible and the ReasonerRegistry
provides a means for mapping from reasoner ids (URIs) to reasoner instances
at run time.
In a future Jena release we plan to provide at least one adapter to an example, freely available, reasoner to both validate the machinery and to provide an example of how this extension can be done.
[Index]
Futures¶
Contributions for the following areas would be very welcome:
- Develop a custom equality reasoner which can handle the "owl:sameAs" and related processing more efficiently that the plain rules engine.
- Tune the RETE engine to perform better with highly non-ground patterns.
- Tune the LP engine to further reduce memory usage (in particular explore subsumption tabling rather than the current variant tabling).
- Investigate routes to better integrating the rule reasoner with underlying database engines. This is a rather larger and longer term task than the others above and is the least likely to happen in the near future.
[Index]