Software Stack¶
SINGA’s software stack includes three major components, namely, core, IO and model. Figure 1 illustrates these components together with the hardware. The core component provides memory management and tensor operations; IO has classes for reading (and writing) data from (to) disk and network; The model component provides data structures and algorithms for machine learning models, e.g., layers for neural network models, optimizers/initializer/metric/loss for general machine learning models.
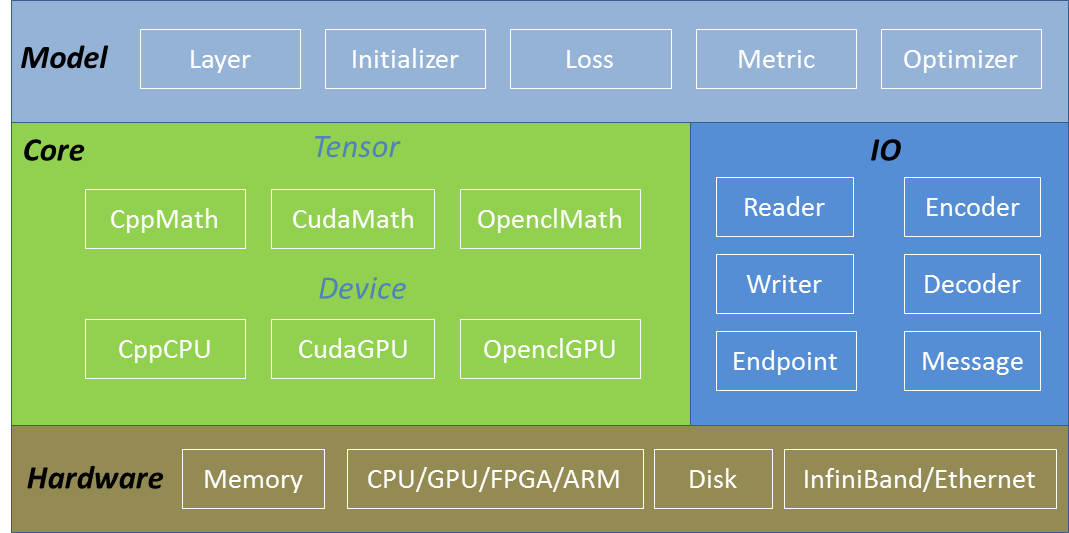
Figure 1 - SINGA V1 software stack.
Core¶
Tensor and Device are two core abstractions in SINGA. Tensor class represents a multi-dimensional array, which stores model variables and provides linear algebra operations for machine learning algorithms, including matrix multiplication and random functions. Each tensor instance (i.e. a tensor) is allocated on a Device instance. Each Device instance (i.e. a device) is created against one hardware device, e.g. a GPU card or a CPU core. Devices manage the memory of tensors and execute tensor operations on its execution units, e.g. CPU threads or CUDA streams.
Depending on the hardware and the programming language, SINGA have implemented the following specific device classes:
CudaGPU represents an Nvidia GPU card. The execution units are the CUDA streams.
CppCPU represents a normal CPU. The execution units are the CPU threads.
OpenclGPU represents normal GPU card from both Nvidia and AMD. The execution units are the CommandQueues. Given that OpenCL is compatible with many hardware devices, e.g. FPGA and ARM, the OpenclGPU has the potential to be extended for other devices.
Different types of devices use different programming languages to write the kernel functions for tensor operations,
CppMath (tensor_math_cpp.h) implements the tensor operations using Cpp for CppCPU
CudaMath (tensor_math_cuda.h) implements the tensor operations using CUDA for CudaGPU
OpenclMath (tensor_math_opencl.h) implements the tensor operations using OpenCL for OpenclGPU
In addition, different types of data, such as float32 and float16, could be supported by adding the corresponding tensor functions.
Typically, users would create a device instance and pass it to create multiple tensor instances. When users call the Tensor functions, these function would invoke the corresponding implementation (CppMath/CudaMath/OpenclMath) automatically. In other words, the implementation of Tensor operations is transparent to users.
Most machine learning algorithms could be expressed using (dense or sparse) tensors. Therefore, with the Tensor abstraction, SINGA would be able to run a wide range of models, including deep learning models and other traditional machine learning models.
The Tensor and Device abstractions are extensible to support a wide range of hardware device using different programming languages. A new hardware device would be supported by adding a new Device subclass and the corresponding implementation of the Tensor operations (xxxMath).
Optimizations in terms of speed and memory could be implemented by Device, which manages both operation execution and memory malloc/free. More optimization details would be described in the Device page.
Model¶
On top of the Tensor and Device abstractions, SINGA provides some higher level classes for machine learning modules.
Layer and its subclasses are specific for neural networks. Every layer provides functions for forward propagating features and backward propagating gradients w.r.t the training loss functions. They wraps the complex layer operations so that users can easily create neural nets by connecting a set of layers.
Initializer and its subclasses provide variant methods of initializing model parameters (stored in Tensor instances), following Uniform, Gaussian, etc.
Loss and its subclasses defines the training objective loss functions. Both functions of computing the loss values and computing the gradient of the prediction w.r.t the objective loss are implemented. Example loss functions include squared error and cross entropy.
Metric and its subclasses provide the function to measure the performance of the model, e.g., the accuracy.
Optimizer and its subclasses implement the methods for updating model parameter values using parameter gradients, including SGD, AdaGrad, RMSProp etc.
IO¶
The IO module consists of classes for data loading, data preprocessing and message passing.
Reader and its subclasses load string records from disk files
Writer and its subclasses write string records to disk files
Encoder and its subclasses encode Tensor instances into string records
Decoder and its subclasses decodes string records into Tensor instances
Endpoint represents a communication endpoint which provides functions for passing messages to each other.
Message represents communication messages between Endpoint instances. It carries both meta data and payload.

