This document comprehensively describes the procedure of running a Pig job using Oozie. Its targeted audience is all forms of users who will install, use and operate Oozie.
Pig is a platform for analyzing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs. Refer to Pig documentation for information on Pig.
Although Pig jobs can be launched independently, there are obvious advantages on submitting them via Oozie such as:
An execution of a Pig job is referred as a Pig action in Oozie. A Pig action can be specified in the workflow definition (xml) file. The workflow job will wait until the Pig job completes before continuing to the next action.
The Pig action has to be configured with the Pig script and the necessary parameters and configuration to run the Pig job. A Pig script contains Pig Latin statements and Pig commands in a single file. For configuration related to job-tracker, name-node, job-xml etc., refer to section Configuring Actions in the Workflow
<workflow-app> ... <action name="[NODE-NAME]"> <pig> ... <script>[PIG-SCRIPT]</script> <argument>[ARGUMENT-VALUE]</argument> ... <argument>[ARGUMENT-VALUE]</argument> ... </pig> <ok to="[NODE-NAME]"/> <error to="[NODE-NAME]"/> </action> ... </workflow-app>
The "script" element contains the Pig script to execute.
The "argument" element, if present, contains arguments to be passed to the Pig script. This can be used for parameter substitution and other purposes.
As with Hadoop map-reduce jobs, it is possible to add files and archives to be available to the Pig job, refer to section Adding Files and Archives for your Job
Oozie allows the user to run a Pig job by specifying the Pig script and other necessary arguments. A command line way to launch a Pig job is:
pig -Dmapred.job.queue.name=myqueue -file script.pig
To accomplish the same using Oozie, the complete xml file for specifying the workflow is below:
<workflow-app name='pig-wf' xmlns="uri:oozie:workflow:0.3">
<start to='pig-node'/>
<action name='pig-node'>
<pig>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare> <delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/pig"/></prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<script>script.pig</script>
</pig>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Pig failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
Format: jobtracker_hostname:port_number
Example: localhost:9001, abc.xyz.yahoo.com:50300
Format: hdfs://namenode_hostname:port_number
Example: hdfs://localhost:9000, hdfs://abc.xyz.yahoo.com:8020
jobtracker and namenode need to be same as the ones defined in the hadoop configuration files. If they are different, they would need to be updated.
Many users want to create a template Pig script and run it with different parameters. This can be accomplished using the -param construct in Pig. For more information, refer to parameter substitution. A command line way to run a Pig job by using the -param construct is:
pig -file script.pig -param INPUT=inputdir -param OUTPUT=outputdir
In order to accomplish the same using Oozie, the <argument> element needs to be included inside the <pig> action.
A partial xml file for such a Pig action:
<script>script.pig</script> <argument>-param</argument> <argument>INPUT=inputdir</argument> <argument>-param</argument> <argument>OUTPUT=outputdir</argument>
A parameter file can also be used to pass parameters. It is primarily used when the number of parameters to be passed are high. A command line way to run a Pig job by using the -param_file construct to pass parameters through file is:
pig -file script.pig -param_file paramfile
The are multiple ways of running such a Pig job through Oozie.
Partial xml file for Pig action:
<script>script.pig</script> <argument>-param_file</argument> <argument>hdfs://localhost:9000/user/ninja/paramfile.txt</argument>
Pig expects the parameter file to be a local file. As Oozie runs on compute node, the location of the parameter file in hdfs should be specified.
The Pig action requires the Pig jar file in the hdfs. Such libraries which are used in the workflow can be stored in the lib directory. During runtime, the Oozie server picks up contents of this directory and deploys them on the actual compute node using Hadoop distributed cache. This lib directory has to be manually copied over to the HDFS before the workflow can run.
hadoop fs -put command can be used to copy the files to hdfs.
hadoop fs -ls command can be used to list the files in hdfs.
Layout of application directory in hdfs:
/user/ninja/examples/apps/pig/workflow.xml /user/ninja/examples/apps/pig/script.pig /user/ninja/paramfile.txt /user/ninja/examples/apps/pig/lib/pig-0.9.jar
The parameter file can be stored in the lib directory as contents of this directory are automatically added to the classpath by Oozie server.
Partial xml file for Pig action:
<script>script.pig</script> <argument>-param_file</argument> <argument>paramfile.txt</argument>
Layout of application directory in hdfs:
/user/ninja/examples/apps/pig/workflow.xml /user/ninja/examples/apps/pig/script.pig /user/ninja/examples/apps/pig/lib/pig-0.9.jar /user/ninja/examples/apps/pig/lib/paramfile.txt
Partial xml file for Pig action
<script>script.pig</script> <argument>-param_file</argument> <argument>symlink.txt</argument> <file>/user/ninja/param/paramfile.txt#symlink.txt</file>
The files under the <file> element are added to the distributed cache. To force a symlink for a file, '#' is used followed by the symlink name. Hence, the file /user/ninja/param/paramfile.txt can be accessed locally using the symbolic name symlink.txt. For detailed usage of symbolic link in <file> and <archive>, refer to Adding Files and Archives for the Job (put link)
Layout of application directory in hdfs
/user/ninja/examples/apps/pig/workflow.xml /user/ninja/examples/apps/pig/script.pig /user/ninja/param/paramfile.txt /user/ninja/examples/apps/pig/lib/pig-0.9.jar
Pig provides support for user-defined functions (UDFs) as a way to specify custom processing. Refer to Pig UDF for information on Pig User Defined Functions (UDF)
Following is an example script file using UDF
REGISTER udfjar/tutorial.jar
A = load '$INPUT/student_data' using PigStorage('\t') as (name: chararray, age: int, gpa: float);
B = foreach A generate org.apache.pig.tutorial.UPPER(name); store B into '$OUTPUT' USING PigStorage();
A command line way to run this Pig job is:
pig -file script.pig -param INPUT=inputdir -param OUTPUT=outputdir
While running through Oozie, the UDF binary has to reside on the compute node.
There are multiple ways of specifying Pig UDF:
Specify the name of the customized jar under the <archive> element and use 'REGISTER' in pig script.
Partial xml file using the <archive> element:
<script>script.pig</script> <argument>-param</argument> <argument>INPUT=inputdir </argument> <argument>-param</argument> <argument>OUTPUT=outputdir </argument> <archive>archive/tutorial.jar#udfjar</archive>
The archive tutorial.jar will be placed into a directory by the name udfjar in the current working directory of the tasks. Hence the jar file in the distributed cache will be available locally to the Pig job.
Layout of application directory in hdfs:
/examples/apps/pig/workflow.xml /examples/apps/pig/script.pig /examples/apps/pig/lib/pig-0.9.jar /examples/apps/pig/archive/tutorial.jar
Specify the name of the customized jar under the <file> element and use 'REGISTER' in Pig script.
Following is an example script file
REGISTER udfjar.jar
A = load '$INPUT/student_data' using PigStorage('\t') as (name: chararray, age: int, gpa: float);
B = foreach A generate org.apache.pig.tutorial.UPPER(name); store B into '$OUTPUT' USING PigStorage();
Partial xml file using the <file> element
<script>script.pig</script> <argument>-param</argument> <argument>INPUT=inputdir </argument> <argument>-param</argument> <argument>OUTPUT=outputdir </argument> <file>archive/tutorial.jar#udfjar.jar</file>
The files under the <file> element are added to the distributed cache. To force a symlink for a file, '#' is used followed by the symlink name. Hence, the file archive/tutorial.jar can be accessed locally using the symbolic name udfjar.jar. For detailed usage of symbolic link in <file> and <archive>, refer to Adding Files and Archives for the Job (put link)
Layout of application directory in hdfs
/examples/apps/pig/workflow.xml /examples/apps/pig/script.pig /examples/apps/pig/lib/pig-0.9.jar /examples/apps/pig/archive/tutorial.jar
Jars in the lib directory are automatically added to the classpath by Oozie server. So, if the customized jar (tutorial.jar) is in lib directory, then the jar file should not be in <archive> and hence, "REGISTER" should be removed from Pig script.
Partial xml file:
<script>script.pig</script> <argument>-param</argument> <argument>INPUT=inputdir </argument> <argument>-param</argument> <argument>OUTPUT=outputdir </argument>
Layout of application directory in hdfs.
/examples/apps/pig/workflow.xml /examples/apps/pig/script.pig /examples/apps/pig/lib/pig-0.9.jar /examples/apps/pig/lib/tutorial.jar
Oozie web-console provides a way to view all the submitted workflow and coordinator jobs in a browser. Each job could be examined in detail to reveal its job configuration, workflow definition and all the actions defined for it. It can be accessed by visiting the url used to submit the job, for eg: http://localhost:4080/oozie.
Note: Please note that the web-console is read-only user interface and it cannot be used to submit a job or modify its status.
Below are some screenshots describing how a job could be drilled down for further details using the web-console.
All the jobs are listed in the grid with filters available above to view the desired job.
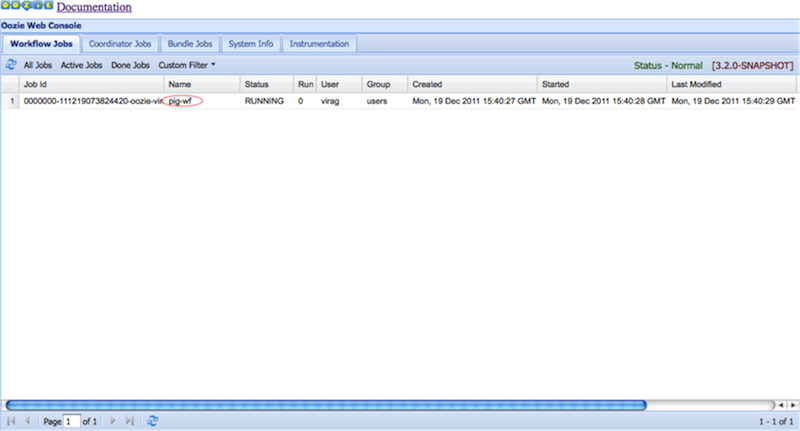
Clicking a job displays the job details and all actions defined under it.
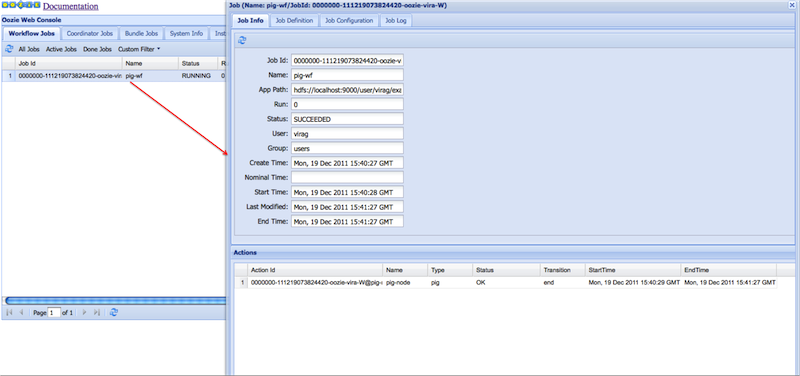
Each action could be further drilled down by clicking on the browse icon beside the Console URL field.
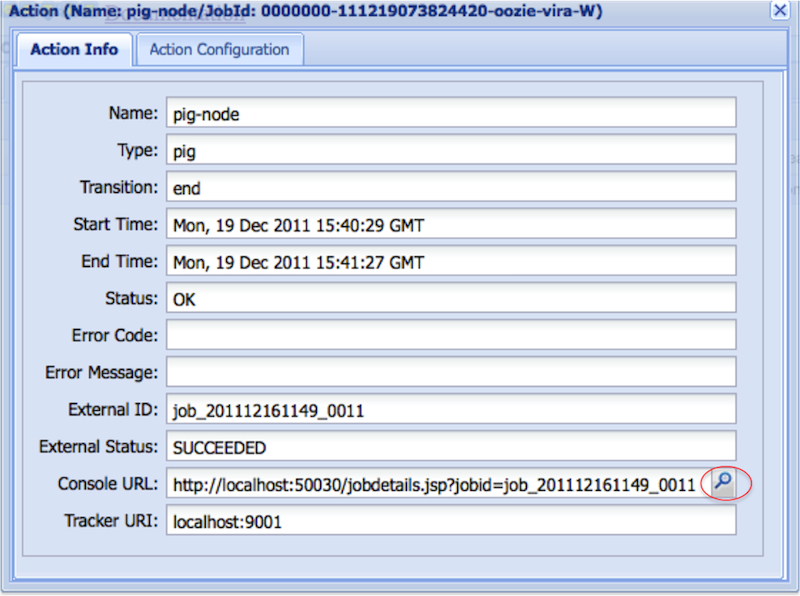
Hadoop job logs can be viewed
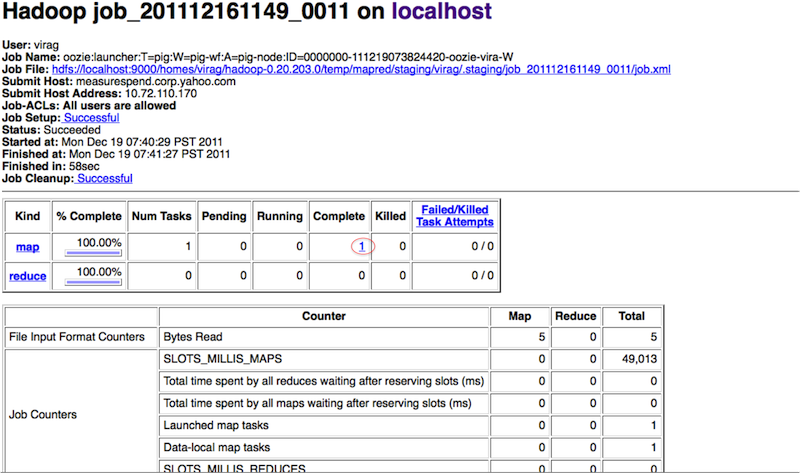
The map task of the launcher job can be accessed by clicking around
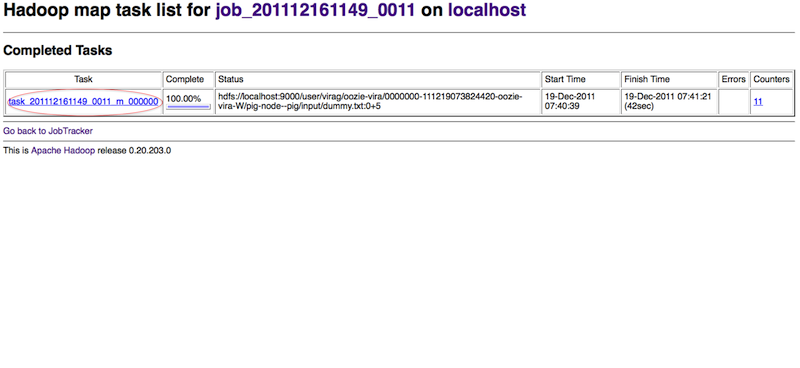
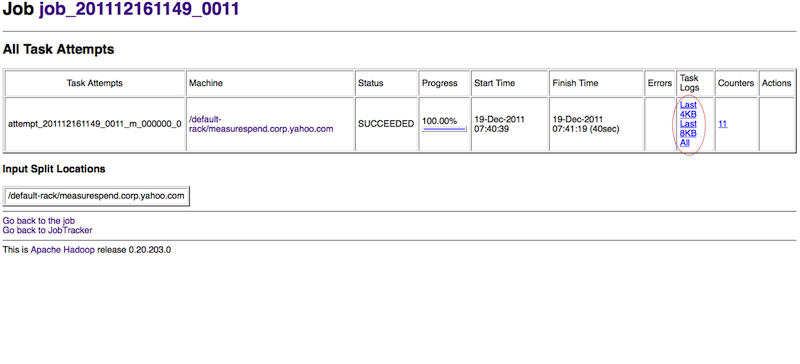
Pig produces a sequence of Map-Reduce programs. The details of all these Map-Reduce jobs can be obtained through the task log files.
Question: How can one increase the memory for the PIG launcher job?
Answer: You can define a property (oozie.launcher.*) in your action:
<property>
<name>oozie.launcher.mapred.child.java.opts</name>
<value>-server -Xmx1G -Djava.net.preferIPv4Stack=true</value>
<description>setting memory usage to 1024MB</description>
</property>
