

SINGA uses the stochastic gradient descent (SGD) algorithm to train parameters of deep learning models. For each SGD iteration, there is a Worker computing gradients of parameters from the NeuralNet and a Updater updating parameter values based on gradients. Hence the model configuration mainly consists these three parts. We will introduce the NeuralNet, Worker and Updater in the following paragraphs and describe the configurations for them. All model configuration is specified in the model.conf file in the user provided workspace folder. E.g., the cifar10 example folder has a model.conf file.
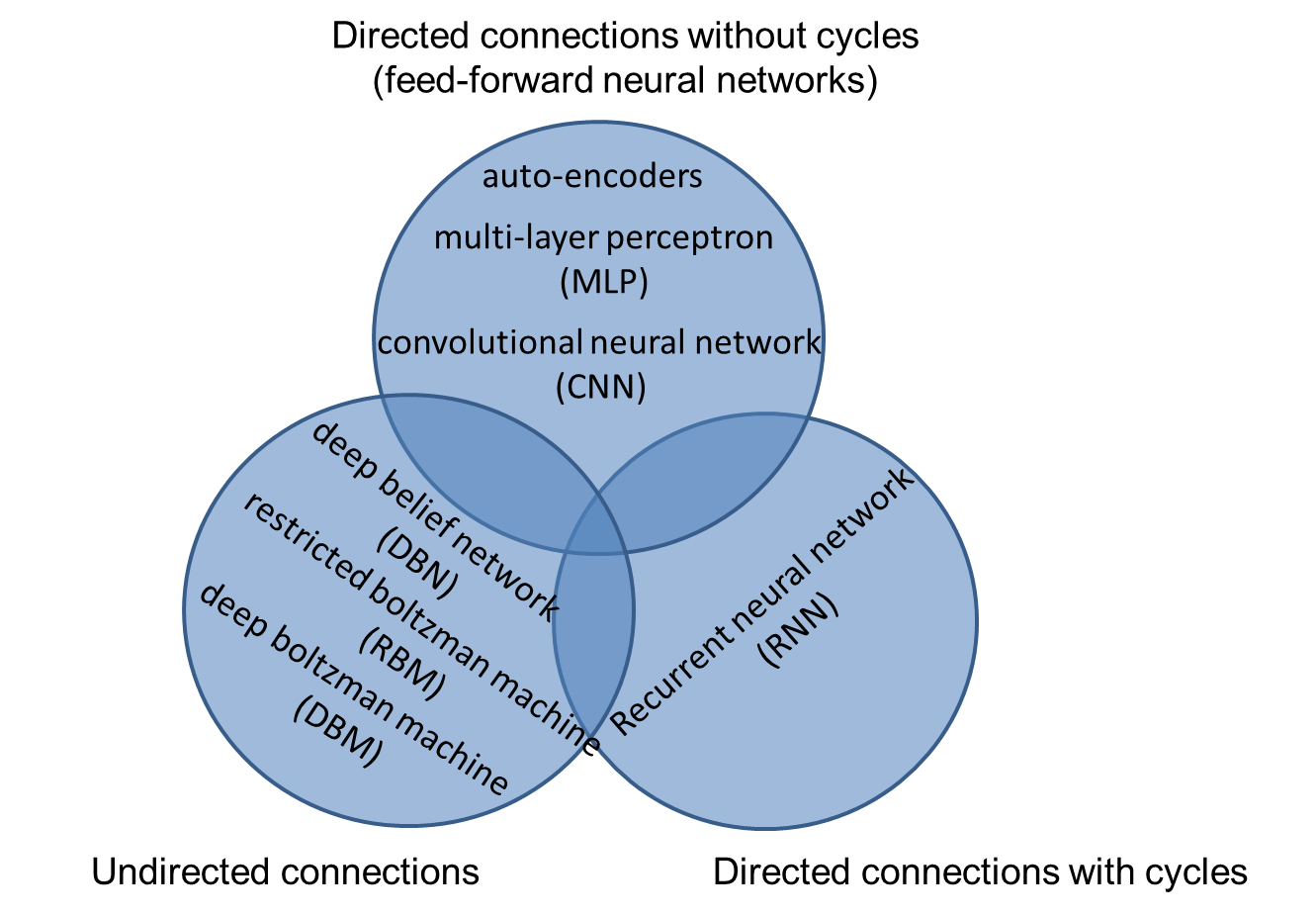 Fig. 1: Deep learning model categorization
Fig. 1: Deep learning model categorization
Many deep learning models have being proposed. Fig. 1 is a categorization of popular deep learning models based on the layer connections. The NeuralNet abstraction of SINGA consists of multiple directly connected layers. This abstraction is able to represent models from all the three categorizations.
For the feed-forward models, their connections are already directed.
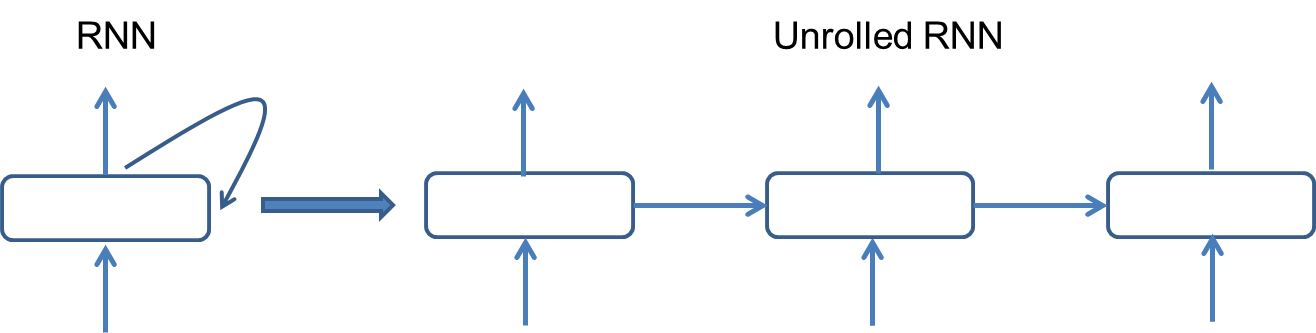
For the RNN models, we unroll them into directed connections, as shown in Fig. 2.
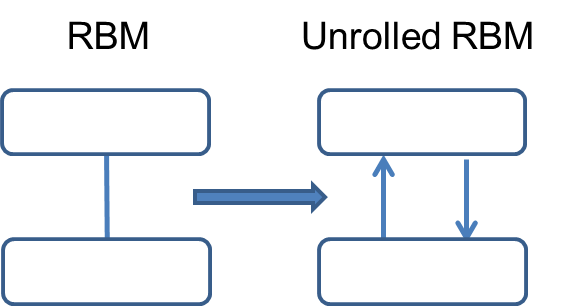
For the undirected connections in RBM, DBM, etc., we replace each undirected connection with two directed connection, as shown in Fig. 3.
In specific, the NeuralNet class is defined in neuralnet.h :
... vector<Layer*> layers_; ...
The Layer class is defined in base_layer.h:
vector<Layer*> srclayers_, dstlayers_; LayerProto layer_proto_; // layer configuration, including meta info, e.g., name ...
The connection with other layers are kept in the srclayers_ and dstlayers_. Since there are many different feature transformations, there are many different Layer implementations correspondingly. For layers that have parameters in their feature transformation functions, they would have Param instances in the layer class, e.g.,
Param weight;
To train a deep learning model, the first step is to write the configurations for the model structure, i.e., the layers and connections for the NeuralNet. Like Caffe, we use the Google Protocol Buffer to define the configuration protocol. The NetProto specifies the configuration fields for a NeuralNet instance,
message NetProto { repeated LayerProto layer = 1; … }
The configuration is then
layer {
// layer configuration
}
layer {
// layer configuration
}
...
To configure the model structure, we just configure each layer involved in the model.
message LayerProto {
// the layer name used for identification
required string name = 1;
// source layer names
repeated string srclayers = 3;
// parameters, e.g., weight matrix or bias vector
repeated ParamProto param = 12;
// the layer type from the enum above
required LayerType type = 20;
// configuration for convolution layer
optional ConvolutionProto convolution_conf = 30;
// configuration for concatenation layer
optional ConcateProto concate_conf = 31;
// configuration for dropout layer
optional DropoutProto dropout_conf = 33;
...
}
A sample configuration for a feed-forward model is like
layer {
name : "input"
type : kRecordInput
}
layer {
name : "conv"
type : kInnerProduct
srclayers : "input"
param {
// configuration for parameter
}
innerproduct_conf {
// configuration for this specific layer
}
...
}
The layer type list is defined in LayerType. One type (kFoo) corresponds to one child class of Layer (FooLayer) and one configuration field (foo_conf). All built-in layers are introduced in the layer page.
At the beginning, the Work will initialize the values of Param instances of each layer either randomly (according to user configured distribution) or loading from a checkpoint file. For each training iteration, the worker visits layers of the neural network to compute gradients of Param instances of each layer. Corresponding to the three categories of models, there are three different algorithm to compute the gradients of a neural network.
SINGA has provided these three algorithms as three Worker implementations. Users only need to configure in the model.conf file to specify which algorithm should be used. The configuration protocol is
message ModelProto {
...
enum GradCalcAlg {
// BP algorithm for feed-forward models, e.g., CNN, MLP, RNN
kBP = 1;
// BPTT for recurrent neural networks
kBPTT = 2;
// CD algorithm for RBM, DBM etc., models
kCd = 3;
}
// gradient calculation algorithm
required GradCalcAlg alg = 8 [default = kBackPropagation];
...
}
These algorithms override the TrainOneBatch function of the Worker. E.g., the BPWorker implements it as
void BPWorker::TrainOneBatch(int step, Metric* perf) {
Forward(step, kTrain, train_net_, perf);
Backward(step, train_net_);
}
The Forward function passes the raw input features of one mini-batch through all layers, and the Backward function visits the layers in reverse order to compute the gradients of the loss w.r.t each layer’s feature and each layer’s Param objects. Different algorithms would visit the layers in different orders. Some may traverses the neural network multiple times, e.g., the CDWorker’s TrainOneBatch function is:
void CDWorker::TrainOneBatch(int step, Metric* perf) {
PostivePhase(step, kTrain, train_net_, perf);
NegativePhase(step, kTran, train_net_, perf);
GradientPhase(step, train_net_);
}
Each *Phase function would visit all layers one or multiple times. All algorithms will finally call two functions of the Layer class:
/** * Transform features from connected layers into features of this layer. * * @param phase kTrain, kTest, kPositive, etc. */ virtual void ComputeFeature(Phase phase, Metric* perf) = 0; /** * Compute gradients for parameters (and connected layers). * * @param phase kTrain, kTest, kPositive, etc. */ virtual void ComputeGradient(Phase phase) = 0;
All Layer implementations must implement the above two functions.
Once the gradients of parameters are computed, the Updater will update parameter values. There are many SGD variants for updating parameters, like AdaDelta, AdaGrad, RMSProp, Nesterov and SGD with momentum. The core functions of the Updater is
/** * Update parameter values based on gradients * @param step training step * @param param pointer to the Param object * @param grad_scale scaling factor for the gradients */ void Update(int step, Param* param, float grad_scale=1.0f); /** * @param step training step * @return the learning rate for this step */ float GetLearningRate(int step);
SINGA provides several built-in updaters and learning rate change methods. Users can configure them according to the UpdaterProto
message UpdaterProto {
enum UpdaterType{
// noraml SGD with momentum and weight decay
kSGD = 1;
// adaptive subgradient, http://www.magicbroom.info/Papers/DuchiHaSi10.pdf
kAdaGrad = 2;
// http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf
kRMSProp = 3;
// Nesterov first optimal gradient method
kNesterov = 4;
}
// updater type
required UpdaterType type = 1 [default=kSGD];
// configuration for RMSProp algorithm
optional RMSPropProto rmsprop_conf = 50;
enum ChangeMethod {
kFixed = 0;
kInverseT = 1;
kInverse = 2;
kExponential = 3;
kLinear = 4;
kStep = 5;
kFixedStep = 6;
}
// change method for learning rate
required ChangeMethod lr_change= 2 [default = kFixed];
optional FixedStepProto fixedstep_conf=40;
...
optional float momentum = 31 [default = 0];
optional float weight_decay = 32 [default = 0];
// base learning rate
optional float base_lr = 34 [default = 0];
}
Some other important configuration fields for training a deep learning model is listed:
// model name, e.g., "cifar10-dcnn", "mnist-mlp" string name; // displaying training info for every this number of iterations, default is 0 int32 display_freq; // total num of steps/iterations for training int32 train_steps; // do test for every this number of training iterations, default is 0 int32 test_freq; // run test for this number of steps/iterations, default is 0. // The test dataset has test_steps * batchsize instances. int32 test_steps; // do checkpoint for every this number of training steps, default is 0 int32 checkpoint_freq;
The pages of checkpoint and restore has details on checkpoint related fields.