Table of Contents
- 1. Qi4j
- 2. Introduction
- 3. Tutorials
- 3.1. Overview
- 3.2. Qi4j in 2 minutes
- 3.3. Qi4j in 10 minutes
- 3.4. Qi4j in 30 minutes
- 3.5. Qi4j in 2 hours
- 3.6. Depend on Qi4j in your build
- 3.7. Assemble an Application
- 3.8. Transient Composites Tutorial
- 3.9. Services Composites Tutorial
- 3.10. Use contextual fragments
- 3.11. Leverage Properties
- 3.12. Create a Constraint
- 3.13. Create a Concern
- 3.14. Create a SideEffect
- 3.15. Create an Entity
- 3.16. Configure a Service
- 3.17. Use I/O API
- 3.18. Build System
- 3.19. Writing Qi4j Documentation
- 4. Javadoc
- 5. Samples
- 6. Core
- 7. Libraries
- 7.1. Overview
- 7.2. Alarms
- 7.3. Caching
- 7.4. Circuit Breaker
- 7.5. Constraints
- 7.6. Conversion
- 7.7. CXF WebService
- 7.8. Event Sourcing
- 7.9. Event Sourcing - JDBM
- 7.10. Event Sourcing - ReST
- 7.11. FileConfig
- 7.12. HTTP
- 7.13. JMX
- 7.14. Locking
- 7.15. Logging
- 7.16. Neo4j
- 7.17. OSGi
- 7.18. RDF
- 7.19. ReST Client
- 7.20. ReST - HATEOAS Primer
- 7.21. ReST Common
- 7.22. ReST Server
- 7.23. Scheduler
- 7.24. Beanshell Scripting
- 7.25. Groovy Scripting
- 7.26. Javascript Scripting
- 7.27. JRuby Scripting
- 7.28. Scala Support
- 7.29. Servlet
- 7.30. Shiro Security
- 7.31. Shiro Web Security
- 7.32. Spring Integration
- 7.33. SQL
- 7.34. Struts - Code Behind
- 7.35. Struts - Convention
- 7.36. Struts - Plugin
- 7.37. UID
- 7.38. UoWFile
- 8. Extensions
- 8.1. Overview
- 8.2. org.json ValueSerialization
- 8.3. Jackson ValueSerialization
- 8.4. StAX ValueSerialization
- 8.5. Ehcache Cache
- 8.6. Memory EntityStore
- 8.7. File EntityStore
- 8.8. Google AppEngine EntityStore
- 8.9. Hazelcast EntityStore
- 8.10. JClouds EntityStore
- 8.11. JDBM EntityStore
- 8.12. LevelDB EntityStore
- 8.13. MongoDB EntityStore
- 8.14. Neo4j EntityStore
- 8.15. Preferences EntityStore
- 8.16. Redis EntityStore
- 8.17. Riak EntityStore
- 8.18. SQL EntityStore
- 8.19. Voldemort EntityStore
- 8.20. ElasticSearch Index/Query
- 8.21. OpenRDF Index/Query
- 8.22. Apache Solr Index/Query
- 8.23. SQL Index/Query
- 8.24. Yammer Metrics
- 8.25. Migration
- 8.26. Reindexer
- 9. Tools
- 10. Glossary
| Important | |
|---|---|
This is the documentation for Qi4j 2.0. Use the version switcher on the left to browse other versions documentation. |
The short answer is that Qi4j™ is a framework for domain centric application development, including evolved concepts from AOP, DI and DDD.
Qi4j™ is an implementation of Composite Oriented Programming, using the standard Java platform, without the use of any pre-processors or new language elements. Everything you know from Java still applies and you can leverage both your experience and toolkits to become more productive with Composite Oriented Programming today.
Moreover, Qi4j™ enables Composite Oriented Programming on the Java platform, including both Java and Scala as primary languages as well as many of the plethora of languages running on the JVM as bridged languages.

Qi4j™ is pronounced "chee for jay". This website is out of scope to explain the many facets and history of Qi, so we refer the interested to read the lengthy article at Wikipedia. For us, Qi is the force/energy within the body, in this case the Java platform. Something that makes Java so much better, if it is found and channeled into a greater good.
We strongly recommend the introduction section.
Composite Oriented Programming builds on some principles that are not addressed by Object Oriented Programming at all.
- Behavior depends on Context
- Decoupling is a virtue
- Business Rules matters more.
- Classes are dead, long live interfaces.
Many objects has life cycles that are more extensive than the simple model that Object Oriented Programming model wants us to believe. A few simple examples;
- An egg becomes a chicken which in turn becomes food.
- I am a programmer at work, a father+husband at home, a victim in a traffic accident and hunter and pray in the jungle.
But it is more to it than that. The composition of the object may change over time. My home now has a garage and my car have different kind of problems with their own state related to it.
In the programming world, we are constantly faced with change of requirements. These changes are often not related to any real world changes, but people coming to new insights of the problem domain. OOP makes those changes a big deal, and often we have to tear up large chunks of the model and redo the work.
But wait, there is more.
Some objects traverses different scope boundaries to the extreme. For instance, a Person will have its attributes changing slightly over time, new abilities be learnt and so forth, that is mentioned above. But the Person will eventually die, but that doesn’t mean that the Person object should be deleted from a system, since the "memory of" that Person may live on for a long time. In a OOP system, we would need to transfer some of the state from a LivingPerson class to a DeadPerson class. In Composite Oriented Programming, it is the same object with different behavior.
We think that one of the the main flaws in OOP is that it is not object oriented at all, but in fact class oriented. Class is the first class citizen that objects are derived from. Not objects being the first-class citizen to which one or many classes are assigned.
Decoupling is more important than developers in general think. If you could have every OOP class decoupled from all other classes, it is easy to re-use that class. But when that class references another class and the chain never ends, your chances of re-use diminishes quickly.
Object Oriented Programming is suffering a lot from this, and many mechanisms have been introduced over time to counter this problem. But in reality, the best we can manage is subsystems of functionality, which client code can re-use. And these subsystems tend to be infrastructure related, since domain models are less prone to be similar enough from one project to the next, and since OOP in reality constrains the the re-use of individual domain classes, we need to re-do the domain model from scratch ever time.
Smart developers often think that low-level, infrastructure and framework code is more important and more cool to work with, than the simple domain model. But in reality, it is the Domain Model that reflects the actual need and pays the bills. Infrastructure is just a necessary evil to get things done.
If most developers could focus on the Business Rules and Domain Model, and not having to worry about any infrastructure issues, such as persistence, transactions, security or the framework housing it all, the productivity would surge. Eric Evans has written an excellent book about Domain Driven Design, where he goes through the real process that makes the money for companies. However, it is very hard to follow that book, since one is constantly caught up in constraints irrelevant to the domain model, introduced by the underlying framework, from the so called smart developers.

Qi4j™ is trying to address the flaws of OOP and introduce Composite Oriented Programming to the world, without introducing new programming languages, or awkward constructs. Heck, we don’t even use any XML.
Qi4j™ is not a framework. It is a new way to write code. Other people might create frameworks using Qi4j™, or create a framework optimized for Qi4j™, but here at Qi4j™ we concentrate to make Qi4j™ behave well in existing frameworks, application servers, platforms and environments.
You are to embark on a new journey. Enjoy!
Qi4j is the first Composite Oriented Programming implementation leveraging the Java 5 platform, so that everything you know from Java 5 still applies. You can mix Qi4j with your ordinary Java code as much as you want. All your existing Java tools works just like before, and Qi4j does not introduce any new programming language, no special development tools needed and no XML is required.
Qi4j addresses the programming problems from the top-down, starting with the Domain Model and Business Rules needs, and let those requirements flow downwards in the software stack and dictate the requirements for underlying layers such as persistence, messaging, querying and more. This means that the business value developer is left to concentrate on the domain models and the actual application bringing the value, instead of creating massive amounts of glue code to tie underlying technologies together.
Qi4j didn’t appear out of the blue, when the founders of the project had nothing better to do. It is the result of observation of problems in real applications, and the experience from previous attempts to address or correct these problems, that has led to the Qi4j vision.
How can OOP be a problem? We and others have observed that there is a fundamental flaw in the OOP model. In fact, we would like to even state that OOP as it is commonly practiced today is not object oriented at all. The object is not the primary citizen, instead the class is the primary artifact. In most mainstream OOP languages, Objects are derived from classes, not that classes are assigned to created objects. Therefore, we think it should have been called Class Oriented Programming. We can also see this class focus in many of the technologies in Java today: in Spring you declare class names in application contexts, JSP uses class names to declare beans and so forth.
This in turn leads to that there is no good OOP solution for the problem we describe below.
Once you start thinking of "Behavior depends on Context", you have a hard time understanding how people for the last 20 years or so of Object Oriented Programming (OOP) has ignored this fact.
When I sitting in front of the computer, I am a software developer, but if I go out in the jungle, I am suddenly hunter-gatherer and prey. A large set of me is the same, but my interaction with the surroundings, i.e. the context, is very different. I need different interfaces, so to speak, in these two different contexts.
Now, the above example is perhaps a bit extreme, but we see it in everyday life of the developer. When an object is stored in the database it is of a different class, than when it is transported to the client and possibly when it is displayed in the GUI. We see the effect of this problem in many of the design patterns and so called "best practices" in Java EE development. Facades, delegation, data transport objects and many more.
The OOP proponents once proclaimed that classes can be re-used, since the code is encapsulated with the class, so the class is an independent unit which lends itself well to re-use. In reality, however, we have found that classes becomes tightly coupled with many other classes in their neighborhood, leading to impossibilities of single class re-use. Many tricks are introduced to minimize the "Coupling Hell", such as Inversion of Control and Dependency Injection. Although those tools are good, the underlying problem remains.
Why do we end up with large coupled class network graphs?
Essentially, it boils down to "scope". Classes are too large, their scope is too large, and for each small functional unit within the class, there will be additional coupling to other classes. And this often progresses to the full boundary of the entire domain the class remains in.
Almost all technologies used in modern software development, starts by looking at an infrastructural problem and try to solve that the best way. This is often done in a vacuum and layers on top will be struggling to map or translate the solution into the higher abstraction, and the higher up we get, the harder it becomes to ignore the assumptions, problems and limitations of the underlying technologies. It is also common that the underlying technologies "bleeds" through the layers all the way into the domain models. The "bleed" combined with the problem of using independently developed technologies, puts a large burden on the application developer, whose job it is to bring business value. And often, the most skilled developers end up doing the bottom layers, leaving the hardest job to the least suitable. Another interesting consequence is that each layer needs to anticipate every single use-case - real, potential or perceived - and deal with it in a specifiable and useful manner. This leads to overly complex solutions, compared to if the system is built from the top layer down, where each layer beneath knows exactly what is expected from it, and only needs to handle those use-cases.
To paraphrase a famous proverb about a hammer: "If all you have are objects, everything looks like a dependency." We think that increasing abstraction often also increases complexity, and that the abstraction benefits are somewhat linear whereas the complexity negatives are exponential. So, our conclusion is that by making no distinction between different kinds of objects, many sound technologies run into incredibly difficult problems. The implementation of the programming platform (e.g. Java) is of course easier to implement with a hefty amount of scope reduction into as few as possible abstractions. But that is not the situation for the user. The abstraction is then required to be reversed when the rubber hits the road, e.g. ORM mapping must be declared explicitly by the programmer, often using separate tools and languages.
We think the solution was expressed more than 2500 years ago, first by Indian scholars and slightly later by Leucippus and Democritus. We are of course talking about atoms, and by using really small building blocks, we can express arbitrarily complex structures. By reducing the classes into what we in Composite Oriented Programming call Fragments, we limit the coupling network graph substantially. Re-use of Fragments becomes a reality, and by combination of Fragments, we compose larger structures, the Composites.
Composite Oriented Programming also view the object, we call it the Composite instance, as the first class citizen. The Composite instance can be cast to any context, meaning a different behavior can be applied to the Composite instance, without affecting its underlying state. And back. This in turn means that we can for instance create a ServerContextualInvoiceEntity, transport that across to a client, cast it to a GuiContextualInvoiceEntity do the modifications to the underlying state, possibly using extra interfaces and methods for interacting with the GUI environment, and then transport the modified object back to the server, cast it back to the ServerContextualInvoiceEntity, and then persist the changes.
Composite Oriented Programming is heavily influenced by the book "Domain Driven Design" by Eric Evans. And we are trying to use his analysis of the problem to provide the mechanisms needed to get the job done quicker and more reliably. Mr Evans talks about Applications, Layers, Modules, Specifications, SideEffects and so forth, and all of these should be present in a Composite Oriented Programming implementation, and to a large extent it is in Qi4j.
We found this very well written blog entry on the Internet, which very well describes what Composite Oriented Programming really is.
The article uses C# and a "show by example" approach to explaining COP, and this shows clearly that COP is not Java specific, and although Qi4j was (to our knowledge) first to introduce the name, it applies across languages and potentially deserves one or more languages on its own.
The article is re-published here, as allowed by the Microsoft Permissive License , more recently known as Microsoft Public License. The content below is NOT under the usual Apache License.
We would like to thank Fredrik Kalseth for his explicit approval as well.
I’ve written a series of post on AOP lately (here, here and here), and in the last part I promised to tackle mixins and introductions in a future post. When I was doing my research for just that, I came cross a Java framework (just humor me :p) called Qi4j (that’s chee for jay), written by Swedish Richard Öberg, pioneering the idea of Composite Oriented Programming, which instantly put a spell on me. Essentially, it takes the concepts from Aspect Oriented Programming to the extreme, and for the past week I’ve dug into it with a passion. This post is the first fruits of my labor.
One of the things that Richard Öberg argues, is that OOP is not really object oriented at all, but rather class oriented. As the Qi4j website proclaims, "class is the first class citizen that objects are derived from. Not objects being the first-class citizen to which one or many classes are assigned". Composite oriented programming (COP) then, tries to work around this limitation by building on a set of core principles; that behavior depends on context, that decoupling is a virtue, and that business rules matter more. For a short and abstract explanation of COP, see this page. In the rest of this post I’ll try and explain some of its easily graspable benefits through a set of code examples, and then in a future post we’ll look at how I’ve morphed the AOP framework I started developing in the previous posts in this series into a lightweight COP framework that can actually make it compile and run.
Lets pause for a short aside: obviously the examples presented here are going to be architectured beyond any rational sense, but the interesting part lies in seeing the bigger picture; imagine the principles presented here applied on a much larger scale and I’m sure you can see the benefits quite clearly when we reach the end.
Imagine that we have a class Division, which knows how to divide one number by another:
public class Division
{
public Int64 Dividend { get; set; }
private long _divisor = 1;
public Int64 Divisor
{
get { return _divisor; }
set
{
if(value == 0)
{
throw new ArgumentException("Cannot set the divisor to 0; division by 0 is not allowed.");
}
_divisor = value;
}
}
public Int64 Calculate()
{
Trace.WriteLine("Calculating the division of " + this.Dividend + " by " + this.Divisor);
Int64 result = this.Dividend/this.Divisor;
Trace.WriteLine("Returning result: " + result);
return result;
}
}Consider the code presented above. Do you like it? If you’ve followed the discussion on AOP in the previous posts, then you should immediately be able to identify that there are several aspects tangled together in the above class. We’ve got data storage (the Dividend and Divisor properties), data validation (the argument check on the Divisor setter), business logic (the actual calculation in the Calculate method) and diagnostics (the Trace calls), all intertwined. To what extent is this class reusable if I wanted to implement addition, subtraction or multiplication calculations? Not very, at least not unless we refactored it. We could make the Calculate method and the properties virtual, and thus use inheritance to modify the logic of the calculation - and since this is a tiny example, it would probably look OK. But again, think bigger - how would this apply to a huge API? It would easily become quite difficult to manage as things got more and more complex.
With a COP framework, we can implement each aspect as a separate object and then treat them as mixins which blend together into a meaningful composite. Sounds confusing? Lets refactor the above example using an as of yet imaginary COP framework for .NET (which I’m currently developing and will post the source code for in a follow-up post), and it’ll all make sense (hopefully!).
Above, we identified the four different aspects in the Division class - so let’s implement each of them. First, we have the data storage:
public interface ICalculationDataAspect // aspect contract
{
long Number1 { get; set; }
long Number2 { get; set; }
}
public class CalculationDataAspect : ICalculationDataAspect // aspect implementation
{
public long Number1 { get; set; }
public long Number2 { get; set; }
}In this example, the data storage is super easy – we just provide a set of properties (using the C# 3.0 automatic properties notation) that can hold the values in-memory. The second aspect we found, was the business logic – the actual calculation:
public interface ICalculationLogicAspect
{
long Calculate();
}
public class DivisionLogicAspect : ICalculationLogicAspect
{
[AspectRef] ICalculationDataAspect _data;
public long Calculate()
{
return _data.Number1 / _data.Number2;
}
}Here we follow the same structure again, by defining the aspect as an interface and providing an implementation of it. In order to perform the calculation however, we need access to the data storage aspect so that we can read out the numbers we should perform the calculation on. Using attributes, we can tell the COP framework that we require this reference, and it will provide it for us at runtime using some dependency injection trickery behind the scenes. It is important to notice that we’ve now placed a constraint on any possible composition of these aspects – the DivisionLogicAspect now requires an ICalculationDataAspect to be present in any composition it is part of (our COP framework will be able to validate such constraints, and tell us up front should we break any). It is still loosely coupled however, because we only hold a constraint on the contract of that aspect, not any specific implementation of it. We’ll see the benefit of that distinction later.
The third aspect we have, is validation. We want to ensure that the divisor is never set to 0, because trying to divide by zero is not a pleasant experience. Validation is a type of advice, which was introduced at length earlier in my AOP series. We’ve seen it implemented using the IAdvice interface of my AOP framework, allowing us to dynamically hook up to a method invocation. However, the advice we’re implementing here is specific to the data aspect, so with our COP framework we can define it as concern for that particular aspect, which gives us a much nicer implementation than an AOP framework could - in particular because of its type safety. Just look at this:
public abstract class DivisionValidationConcern : ICalculationDataAspect
{
[ConcernFor] protected ICalculationDataAspect _proceed;
public abstract long Number1 { get; set; }
public long Number2
{
get { return _proceed.Number2; }
set
{
if (value == 0)
{
throw new ArgumentException("Cannot set the Divisor to 0 - division by zero not allowed.");
}
_proceed.Number2 = value; // here, we tell the framework to proceed with the call to the *real* Number2 property
}
}
}I just love that, it’s so friggin' elegant ;). Remember that an advice is allowed to control the actual method invocation by telling the target when to proceed – we’re doing the exact same thing above, only instead of dealing with a generic method invocation we’re actually using the interface of the aspect we’re advising to control the specific invocation directly. In our validation, we validate the value passed into the Divisor setter, and if we find it valid then we tell the target (represented by a field annotated with an attribute which tells the COP framework to inject the reference into it for us, much like we did with aspects earlier) to proceed with the invocation; otherwise we throw an exception. This particular concern is abstract, because we only wanted to advise a subset of the methods in the interface. That’s merely a convenience offered us by the framework - under the covers it will automatically complete our implementation of the members we left abstract.
Only one aspect remains now, and that is the logging:
public class LoggingAdvice : IAdvice
{
public object Execute(AdviceTarget target)
{
Trace.WriteLine("Invoking method " + target.TargetInfo.Name + " on " + target.TargetInfo.DeclaringType.FullName);
object retValue;
try
{
retValue = target.Proceed();
}
catch(Exception ex)
{
Trace.WriteLine("Method threw exception: " + ex.Message);
throw;
}
Trace.WriteLine("Method returned " + retValue);
return retValue;
}
}We’ve implement it as a regular advice, like we’ve seen earlier in AOP, because it lends itself to much wider reuse than the validation concern did.
Having defined all our aspects separately, it is now time to put them back together again into something that can actually do something. We call this the composite, and it is defined as follows:
[Mixin(typeof(ICalculationDataAspect), typeof(CalculationDataAspect))]
[Mixin(typeof(ICalculationLogicAspect), typeof(DivisionLogicAspect))]
[Concern(typeof(DivisionValidationConcern))]
[Concern(typeof(LoggingAdvice))]
public interface IDivision : ICalculationDataAspect, ICalculationLogicAspect
{ }Basically, we’ve just defined the implementation of an interface IDivision as a composition of the data and logic aspects, and sprinkled it with the two concerns (the validation concern and the logging advice). We can now use it to perform divisions:
IDivision division = Composer.Compose<IDivision>().Instantiate(); division.Number1 = 10; division.Number2 = 2; Int64 sum = division.Calculate();
That’s pretty cool, no? Take a moment to just think about what doors this opens. To what extent do you think our code is reusable now, if we wanted to implement addition, subtraction and so forth? That’s right – all we’d need to do is substitute the implementation of the calculation aspect with one that performs the required calculation instead of division, and we’re done. Let’s do subtraction, for example:
public class SubtractionLogicAspect : ICalculationLogicAspect
{
[AspectRef] ICalculationDataAspect _data;
public long Calculate()
{
return _data.Number1 - _data.Number2;
}
}That’s it! The rest we can reuse as is, building a new composite:
[Mixin(typeof(ICalculationDataAspect), typeof(CalculationDataAspect))]
[Mixin(typeof(ICalculationLogicAspect), typeof(SubtractionLogicAspect))]
[Pointcut(typeof(LoggingAdvice))]
public interface ISubtraction : ICalculationDataAspect, ICalculationLogicAspect
{ }Notice that we just left out the validation concern in this composite, as it is no longer needed. What if we wanted our subtraction to only ever return positive numbers? Easy! We’ll just implement an absolute number concern:
public class AbsoluteNumberConcern : ICalculationLogicAspect
{
[ConcernFor] protected ICalculationLogicAspect _proceed;
public long Calculate()
{
long result = _proceed.Calculate();
return Math.Abs(result);
}
}And then update the composition to include it:
[Mixin(typeof(ICalculationDataAspect), typeof(CalculationDataAspect))]
[Mixin(typeof(ICalculationLogicAspect), typeof(SubtractionLogicAspect))]
[Concern(typeof(AbsoluteNumberConcern))]
[Pointcut(typeof(LoggingAdvice))]
public interface ISubtraction : ICalculationDataAspect, ICalculationLogicAspect
{ }To Be Continued…
I hope this post has whet your appetite for more on this subject, as I will certainly pursue it further in future posts. I’ve already implemented a prototype framework that supports the above examples, which builds on my previously posted AOP framework, and I’ll post the source code for that soon. If you want to dig deeper right now (and don’t mind a bit of Java), then I suggest you head over to the Qi4j website and poke about there. Richard Öbergs blog also provides great insight.
In OOP the main idea is that we should model our reality by creating Objects. Objects have state, and they have methods. Methods in an object are used to operate on the internal state and understands the domain that is being modeled.
By contrast, in procedural programming the focus is on algorithms, which can use several data structures to perform some task. The focus is on what is going on, rather than the "objects" involved.
With OOP it becomes more difficult to "read" algorithms, as they are spread out in many objects that interact. With procedural programming it becomes difficult to encapsulate and reuse functionality. Both represent extremes, neither of which is "correct". The tendency to create anemic domain models is an indication that we have lost the algorithmic view in OOP, and there is a need for it.
The main flaw of OOP, which COP addresses, is the answer to the fundamental question "What methods should an object have?". In traditional OOP, which really should be called "class oriented programming", the classes tend to have a rather narcissistic point of view. Classes are allowed to dictate what methods are in there - regardless of the algorithms which they are part of - and algorithms then need to be aware of these classes when object instances collaborate in an algorithm. Why? This seems like complete madness to me!! Keep in mind that if there were no algorithms, there would be no need for methods at all!! Algorithms, then, are primary, and objects are what we use as helper structures. In philosophical terms, if there is noone around to observe the universe, there would be no need for the universe itself!
In COP the responsibility for defining the methods is reversed: algorithms which implement interactions between objects get to declare what roles it needs the objects to implement, and the composites can then implement these. For each role there will be an interface, and for each composite wanting to implement a role there will be a mixin in that composite. This mixin can be specific for that composite implementation, or it can be generic and reused. The key point is that it is the OBSERVER of the object, meaning, the algorithm, that gets to decide what the object should be able to do.
This is the same in real life. I don’t get to decide how I communicate with you. I have to use english, and I have to use email, and I have to send it to a specific mailing list. It is the algorithm of the interaction between us, the Qi4j dev mailing list, that has set these rules, not I as a participant in this interaction. The same should, obviously, be the case for objects.
So, with the understanding that algorithms should define roles for collaborating objects, and objects should then implement these in order to participate in these algorithms, it should be trivial to realize that what has passed for OOP so far, in terms of "class oriented programming", where this role-focus of objects is difficult to achieve, if not even impossible, is just plain wrong. I mean seriously, catastrophically, terminally wrong.
Let that sink in.
The method that has been used so far to get around this has been the composite pattern, where one object has been designated as "coordinator", which then delegates to a number of other objects in order to implement the various roles. This "solution", which is caused by this fundamental flaw in "class oriented programming", is essentially a hack, and causes a number of other problems, such as the "self schizophrenia" problem, whereby there is no way to tell where the object really is. There is no "this" pointer that has any relevant meaning.
The Composite pattern, as implemented in COP and Qi4j, gets around this by simply saying that the composite, as a whole, is an object. Tada, we now have a "this" pointer, and a coherent way to deal with the object graph as though it was a single object. We are now able to get back to the strengths of the procedural approach, which allows the implementer of the algorithm to define the roles needed for the algorithm. The roles can either be specific to an algorithm, or they can be shared between a number of algorithms if there is a generic way for them to be expressed.
Goodness!
The question now becomes: how can we use this insight to structure our composites, so that what is part of the algorithm is not too tightly encoded in the composites, thereby making the algorithms more reusable, and making it less necessary to read composite code when trying to understand algorithms. The assumption here is that we are going to write more algorithms than composites, therefore it has to be easy to ready algorithms, and only when necessary dive down into composite code.
When talking about Composites as Objects in Qi4j it is most relevant to look at Entities, since these represent physical objects in a model, rather than algorithms or services, or other non-instance-oriented things.
If Entities should implement roles, via mixins, in order to interact with each other through algorithms, then the majority of their behaviour should be put into those role-mixins. These are exposed publically for clients to use. However, the state that is required to implement these roles should not be exposed publically, as they represent implementation details that may change over time, may be different depending on role implementation, and usually has a lot of rules regarding how it may be changed. In short, the state needs to be private to the composite.
This leads us to this typical implementation of an Entity
@Mixins(SomeMixin.class)
interface MyEntity
extends Some, Other, EntityComposite
{}
where Some and Other are role interfaces defined by one or more algorithms. SomeMixin is the implementation of the Some interface. There is NO interface that is defined by the author of MyEntity. Algorithms first, objects second!
The state needed for these mixins would then be put into separate interfaces, referred to by using the @This injection in the mixins.
interface SomeState
{
Property<String> someProperty();
}
These interfaces will pretty much ONLY contain state declarations. There might be some methods in there, but I can’t see right now what they would be.
In order to be able to get an overview of all the state being implemented by the Entity we introduce a "superstate" interface:
interface MyState
extends SomeState, OtherState //, ...
{}
This lets us see the totality of all the state that the Entity has, and can be used in the builder phase:
EntityBuilder<MyEntity> builder = uow.newEntityBuilder(MyEntity.class); MyState state = builder.instanceFor(MyState.class); //... init state ... MyEntity instance = builder.newInstance();
This lets us divide our Entity into two parts: the internal state and the external roles of the domain that the object takes part in. Due to the support for private mixins the state is not unnecessarily exposed, and the mixin support in general allow our role-oriented approach to modeling. The role interfaces are strongly reusable, the mixins are generally reusable, and the state interfaces are usually reusable. This minimizes the need for us to go into the mixin code and read it. If we have read the mixin code once, and the same mixin is reused between objects, then this makes it easier for us to understand it the next time we see it being used in another algorithm.
To summarize thus far, we have looked at why OOP so far has not worked out, why this is the case, and how COP deals with it, and how we can implement a better solution of Entities using Qi4j. All is well!
The next step is to start using these Entities in algorithms. Algorithms are usually stateless, or at least they don’t have any state that survives the execution of the algorithm. There is input, some calculation, and then output. In other words, our notion of services fit perfectly here!
Algorithms, then, should(/could?) be modeled using services. If an algorithm needs other algorithms to compute something, that is, if a service needs another service to do something, we can accomplish this using dependency injection, so that the user of the initial algorithm does not have to know about this implementation detail.
In a "Getting Things Done" domain model, with Projects and Actions, you might then have an algorithm like so for task delegation:
void delegate(TaskExecutor from, Completable completable, TaskExecutor to)
{
to.inbox().createTask( createDelegatedTask( completable ) );
completable.complete(); // Delegated task is considered done
from.inbox().createTask( createWaitingTask( completable ) );
}In the above I don’t know if "from" and "to" are human users or systems that automatically execute tasks. I also don’t know if Completable is an entire Project or a single Action. From the point of view of the algorithm I don’t need to know! All the algorithm cares about is that the roles it needs are fulfilled somehow. This means that I will be able to extend my domain model later on, and have it be a part of these kinds of algorithms, without having to change my algorithms. And as long as my composites implement the role interfaces, such as TaskExecutor and Completable, they can participate in many different algorithms that use these as a way to interact with the domain objects.
This shows the place of services, as points of contact between objects in a domain model, or more generally, "interactions". These will change often, and will increase in number as the system grows, so it is important that they are easy to read, and that they are easy to participate in. With a focus on roles, rather than classes, this becomes much easier to accomplish!
With the responsibilities of entities, as objects, and services, as algorithms, more clearly defined, the last part to deal with is how these are put together. The services, with the methods now being role-oriented, can obviously be applied to a wide variety of entities, but we now go from general to specific. In our software each general algorithm is typically applied to specific objects in specific use-cases.
How is this done?
This is done by implementing context objects, which pick specific objects and pass them into algorithms. This is typically a UI-centric thing, and as such is difficult to encapsulate into a single method. With the previous example we would need to get the three objects involved, and cast them to the specific roles we are interested in. The "TaskExecutor from" could be the user running the application, the "Completable completable" could be the currently selected item in a list, and "TaskExecutor to" could be a user designated from a popup dialog. These three are then taken by the context and used to execute the "delegate" interaction, which performs all the steps necessary.
The interaction method "delegate" is testable, both with mocks of the input, and with specific instances of the various roles. The implementations are also testable, and if the same mixin is used over and over for the implementation, then only one set of tests is needed for each role interface.
To summarize we have in COP/Qi4j a way to get the best from procedural and object-oriented programming. As we have seen the functionality falls into three categories, the entities implementing objects, the services implementing interactions, and the user interface implementing the context. This also maps well to the ideas of ModelViewController, which in turn maps well to the new ideas from Mr Reenskaug (inventor of MVC) called DCI: Data-Context-Interaction. As a side-effect of this discussion we have therefore also seen how COP/Qi4j can be used to implement DCI, which is an important next step in understanding objects and their interactions, the fundamentals of which (I believe) are captured on this page.
That’s it. Well done if you’ve read this far :-)
Comments and thoughts to qi4j-dev forum at Google Groups on this are highly appreciated. This is very very important topics, and crucial to understanding/explaining why COP/Qi4j is so great! :-)
(From Rickard Oberg’s blog, http://www.jroller.com/rickard/entry/qi4j_and_state_modeling, 2009-02-19)
In the Qi4j project we strive to being able to express our domain as directly as possible, with as little translation as possible between how we think about a domain and how it is actually coded. This then affects our entire view of how application frameworks should be constructed, and what we consider good and bad ways of implementing certain features.
One part which is a good example of this is persistent state modeling. In other approaches and frameworks one would typically use POJOs for the objects, and then plain class fields for references, collections and properties. But during modeling these are not the words we use. If POJOs are used for both Entities and Values, which have radically different semantics, we have to always translate in our heads when talking about them, always keeping mind what the POJO is doing in any particular context. In Domain Driven Design terms, POJOs are not in our Ubiquitous Language.
From a DDD perspective we want to talk about Entities and Values, Properties and Associations. If our code does not reflect this, then there is translation going on, and translation inevitably leads to information loss. In Qi4j, where Composites and not Objects, are the basic construct, we have created specialized forms to model these concepts more explicitly. We have EntityComposites and ValueComposites, each with different ways of creating them and managing them. Both EntityComposites and ValueComposites can then have Properties, as first-class objects, but Properties in ValueComposites are always immutable.
Here’s an example of how you could define an EntityComposite:
interface PersonEntity
extends EntityComposite
{
Property<String> givenName();
Property<String> surName();
}
With these few lines you have done what would have taken a whole lot more effort using POJOs, and what you want to express is very explicit. To define a property you would have had to write a field and two accessors, and if you use interfaces then those accessors would have to be duplicated.
The EntityComposite base interface also includes an identity property for you, as that’s an intrinsic feature of Entities, so that’s all taken care of. So if you speak about Entities in your domain discussions, each having Properties, then you can put that down in code pretty much as-is. This is, to me, a huge advantage over other ways of doing it, including POJO modeling (which lose clarity), UML modeling (which has roundtrip problems), DSL modeling (which lose tools support), and whatnot.
If you want to get picky about it, the above example is probably not how you would model Person. Having a name is just one role that a Person has to play, and since Composite Oriented Programming is all about using roles and context instead of classes you would probably do something like this instead:
interface Nameable
{
@UseDefaults Property<String> givenName();
@UseDefaults @Optional Property<String> surName();
}
interface PersonEntity
extends Nameable, EntityComposite
{}
I’ve extracted the ability to be Named to its own interface, and let my domain Entity extend it. This way client code can check for "x instanceof Nameable" rather than "x instanceof PersonEntity", and then do something intelligent with it. By doing this, not only has Nameable become a reusable interface, but the client code that understands it has also become reusable for all domain objects in your model that uses it!
I’ve also marked both properties as @UseDefaults. What does this do? Well, if you have string properties they have the annoying property of being null to begin with, compared to ints and longs which default to 0. We figured that this was such a useful thing that we wanted to be able to mark our properties as being able to have their initial values be set to a default, for the type. For Strings this is the empty string, for primitives they are what you would expect. For Collections they are set to empty collections of the type indicated. "@UseDefaults Property<List<String>> addresses();" would be initialized to an empty ArrayList, for example.
In addition I have set surName() to be @Optional. In Qi4j we have defined all properties to be not-null as the default, and the same goes for all parameters in method invocations. If you explicitly want to allow properties to be null, so that for example "Madonna" would be an acceptable name, then you can mark it as @Optional. We prefer @Optional to @Nullable since it better expresses the intent from a domain perspective. Avoiding technical terms as much as possible is a another goal (which is damn hard to reach!).
If you want to get really picky about it, not even the above would be a real example. You may want to encapsulate the two properties into one value instead, so that you can more easily perform validation checks when they are updated. What you want are ValueComposites:
interface NameValue
extends ValueComposite
{
@UseDefaults Property<String> givenName();
@UseDefaults @Optional Property<String> surName();
}
interface Nameable
{
Property<NameValue> name();
}
Normally if you want a property to be immutable, meaning, you can set an initial value but not change it later, you would have to mark the Property as @Immutable. But since NameValue extends ValueComposite, which itself is marked with @Immutable, this is implicit for all subtypes of ValueComposite, and there’s no way to "opt out" of it.
By introducing one more level in the state model you have created an easy way to access the name as a whole and hand it around the system, instead of as two separate properties. Since it is immutable you are also ensured that noone can change it without going through the Entity, and you can also share instances of the name without having to worry about thread-safety.
The above is already a great step ahead in terms of how you can model your state more easily than having to use POJOs to sort of "fake" the features I’m describing above, and there’s also a ton of cool features and consequences of the whole thing I’m skipping here, for brevity. One of the problems with POJO models that usually come up is that your getters and setters get exposed to clients, and so functionality tend to not be put in the Entities, but rather in services and helper code, thereby scattering the Entity into a bunch of places. What should have been a neat and tidy little package is instead a anorectic little thing whose guts lay splashed around your code, looking all soggy and unappetizing.
What to do about this? One of the great inventions of Qi4j, I believe, is the notion of private mixins. That we can have mixins in an object which are explicitly HIDDEN from usage outside of it. How can we use this for state modeling? What you’d want to do is to model the state of an Entity as a private mixin, which is hidden from clients, and then you write role mixins which map domain methods to that internal state. Here’s an example:
@Mixins(ListablePersonMixin.class)
interface PersonEntity
extends Listable, EntityComposite {}
interface PersonState
extends Nameable {}
public class ListablePersonMixin
implements Listable
{
@This PersonState person;
@Override
public String listName()
{
String fullName = person.name().get().givenName().get();
String sn = person.name().get().surName().get();
if (sn != null) fullName += " "+sn;
return fullName;
}
}
interface Listable
{
public String listName();
}
Neat huh? @This is a dependency injection annotation, but rather than the usual generic annotations like "@Inject" and friends, this one actually has a meaningful scope, that is, it requires that "this Entity" implements PersonState. The reference, as it is not extended by PersonEntity, is not visible to clients of the Entity and is hence a private mixin. Furthermore, all of a sudden your client code doesn’t even care if your domain object is Nameable, but rather if it is Listable. Cool! So you can make a UI widget for listing "stuff" that only requires that your thingie is Listable, rather than being a PersonEntity or Nameable.
For extra credit you could move the construction of "fullName" into a method on the NameValue, so that the value is not only a dumb data container, but can also perform useful operations on itself. And for the performance aware, don’t worry, the mixin is lazy-loaded, so if the particular usecase handling the Entity doesn’t need the "Listable" interface the mixin will never be instantiated.
And so much more…
The above is just a small taste of what you can do with state modeling in Qi4j. There is also support for associations and many-associations, the notion of aggregates, and a complete pluggable system for persistence and indexing/querying of data. To end with, here’s a sample of how some other state modeling concepts can be expressed in Qi4j:
interface PersonEntity
extends EntityComposite
{
Association<PersonEntity> father();
@Optional Association<PersonEntity> spouse();
ManyAssociation<PersonEntity> children();
@Aggregated ManyAssociation<BookNoteEntity> favouriteBooks();
}
interface BookNoteEntity
extends EntityComposite
{
Property<String> note();
Association<BookEntity> book();
}
I hope they are self-explanatory.
My hope is that with Composite Oriented Programming and Qi4j we can come one step closer to being able to express our domain as clearly as possible in code.
Qi4j addresses a wide range of concepts, the related publications and projects you’ll find in this section span accross all theses concepts. Please note that this is not an exhaustive list but only some pointers to help you understand which principles Qi4j is based on.
In chronological order, related publications:
Object-oriented Software Construction
by Bertrand Meyer - 1988
"The comprehensive reference on all aspects of object technology, from design principles to O-O techniques, Design by Contract, O-O analysis, concurrency, persistence, abstract data types and many more. Written by a pioneer in the field, contains an in-depth analysis of both methodological and technical issues."
http://se.ethz.ch/~meyer/publications/index_kind.html#POOSC2
Object-Oriented Programming: An Objective Sense of Style
by K. Lieberherr, I. IIolland, A. Riel - 1988
"The "Law of Demeter" (or LoD) as it is commonly called, is really more precisely the "Law of Demeter for Functions/Methods" (LoD-F). It is a design-style rule for object-oriented programs. Its essence is the "principle of least knowledge" regarding the object instances used within a method."
http://www.ccs.neu.edu/research/demeter/papers/law-of-demeter/oopsla88-law-of-demeter.pdf
Designing Reusable Classes
by Ralph E. Johnson & Brian Foote - 1988
"Object-oriented programming is as much a different way of designing programs as it is a different way of designing programming languages. […] In particular, since a major motivation for object-oriented programming is software reuse, this paper describes how classes are developed so that they will be reusable."
The Open/Closed Principle
by Robert C. Martin - 1996
"As Ivar Jacobson said: “All systems change during their life cycles. This must be borne in mind when developing systems expected to last longer than the first version.” How can we create designs that are stable in the face of change and that will last longer than the first version?"
The Liskov Substitution Principle
by Robert C. Martin - 1996
"Substitutability is a principle in object-oriented programming. It states that, in a computer program, if S is a subtype of T, then objects of type T may be replaced with objects of type S (i.e., objects of type S may be substituted for objects of type T) without altering any of the desirable properties of that program (correctness, task performed, etc.).."
The Dependency Inversion Principle
by Robert C. Martin - 1996
"In this column, we discuss the structural implications of the Open-Closed and the Liskov Substitution principles. The structure that results from rigorous use of these principles can be generalized into a principle all by itself. I call it “The Dependency Inversion Principle” (DIP)."
Aspect-Oriented Programming
by Kiczales, Gregor; John Lamping, Anurag Mendhekar, Chris Maeda, Cristina Lopes, Jean-Marc Loingtier, and John Irwin - 1997
"We have found many programming problems for which neither procedural nor object-oriented programming techniques are sufficient to clearly capture some of the important design decisions the program must implement. This forces the implementation of those design decisions to be scattered throughout the code, resulting in “tangled” code that is excessively difficult to develop and maintain. We present an analysis of why certain design decisions have been so difficult to clearly capture in actual code. We call the properties these decisions address aspects, and show that the reason they have been hard to capture is that they crosscut the system’s basic functionality. We present the basis for a new programming technique, called aspect-oriented programming, that makes it possible to clearly express programs involving such aspects, including appropriate isolation, composition and reuse of the aspect code. The discussion is rooted in systems we have built using aspect-oriented programming."
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.115.8660
Domain-Driven Design: Tackling Complexity in the Heart of Software
by Eric Evans - 2003
"This book provides a broad framework for making design decisions and a technical vocabulary for discussing domain design. It is a synthesis of widely accepted best practices along with the author’s own insights and experiences. Projects facing complex domains can use this framework to approach domain-driven design systematically. Many people have employed domain-driven design in some form, but it will be made more effective with a systematic approach and a shared vocabulary."
Tell, Don’t Ask
by Andy Hunt and the Pragmatic Programmers - 2003
"Procedural code gets information then makes decisions. Object-oriented code tells objects to do things. - Alec Sharp"
Inversion of Control Containers and the Dependency Injection pattern
by Martin Fowler - 2004
"In the Java community there’s been a rush of lightweight containers that help to assemble components from different projects into a cohesive application. Underlying these containers is a common pattern to how they perform the wiring, a concept they refer under the very generic name of "Inversion of Control". In this article I dig into how this pattern works, under the more specific name of "Dependency Injection", and contrast it with the Service Locator alternative. The choice between them is less important than the principle of separating configuration from use."
Inversion of Control
by Martin Fowler - 2005
"Inversion of Control is a key part of what makes a framework different to a library."
Applying Domain-Driven Design and Patterns
by Jimmy Nilsson - 2006
"While Eric’s book is the definitive treatment of DDD, this book by Jimmy Nilsson takes a fresh approach to this difficult topic. Pragmatic and full of examples, this book digs into the nitty-gritty of applying DDD."
Domain-Driven Design Quickly
by Abel Avram & Floyd Marinescu - 2007
"Domain-Driven Design Quickly, is a 104 page condensed explanation of the basic principles of DDD, drawing heavily on the content of Evans and Nilsson."
Putting model to work
by Eric Evans - 2007
"This talk will outline some of the foundations of domain-driven design: How models are chosen and evaluated; How multiple models coexist; How the patterns help avoid the common pitfalls, such as overly interconnected models; How developers and domain experts together in a DDD team engage in deeper exploration of their problem domain and make that understanding tangible as a practical software design."
Strategic design
by Eric Evans - 2007
"This talk introduces two broad principles for strategic design. Context mapping addresses the fact that different groups model differently. Core domain distills a shared vision of the system’s "core domain" and provides a systematic guide to when "good enough" is good enough versus when to push for excellence."
Clarified CQRS
by Udi Dahan - 2009
"After listening how the community has interpreted Command-Query Responsibility Segregation I think that the time has come for some clarification. Some have been tying it together to Event Sourcing. Most have been overlaying their previous layered architecture assumptions on it. Here I hope to identify CQRS itself, and describe in which places it can connect to other patterns."
The DCI Architecture: A New Vision of Object-Oriented Programming
by Trygve Reenskaug and James O. Coplien - 2009
"Object-oriented programming was supposed to unify the perspectives of the programmer and the end user in computer code: a boon both to usability and program comprehension. While objects capture structure well, they fail to capture system action. DCI is a vision to capture the end user cognitive model of roles and interactions between them."
Command and Query Responsibility Segregation
by Greg Young - 2010
"Command and Query Responsibility Segregation uses the same definition of Commands and Queries that Meyer used and maintains the viewpoint that they should be pure. The fundamental difference is that in CQRS objects are split into two objects, one containing the Commands one containing the Queries."
Polyglot Persistence
by Martin Fowler - 2011
"If you’re working in the enterprise application world, now is the time to start familiarizing yourself with alternative data storage options. This won’t be a fast revolution, but I do believe the next decade will see the database thaw progress rapidly."
CQRS
by Martin Fowler - 2011
"CQRS stands for Command Query Responsibility Segregation. It’s a pattern that I first heard described by Greg Young. At its heart is a simple notion that you can use a different model to update information than the model you use to read information. This simple notion leads to some profound consequences for the design of information systems."
Domain Event
by Martin Fowler - WIP
"Captures the memory of something interesting which affects the domain."
Event Sourcing
by Martin Fowler - WIP
"Capture all changes to an application state as a sequence of events."
Event Collaboration
by Martin Fowler - WIP
"Multiple components work together by communicating with each other by sending events when their internal state changes."
Pêle-mêle, inspiring, inspired, alternatives or simply related:
AspectJ
"An aspect-oriented extension to the Java programming language."
Spring Framework
"The Spring Framework is an application framework and Inversion of Control container for the Java platform."
Google Guice
"Guice alleviates the need for factories and the use of new in your Java code"
Java Enterprise Edition (EJBs, CDI)
"Java EE provides component development, web services, management, and communications APIs."
Chaplin ACT
"Chaplin ACT is a Java class transformer which modifies classes in such a way that their instances can form composites at runtime."
JavATE
"JavATE, the Java Domain Driven Design Framework, is a set of open source Java libraries that enables application development using a domain driven approach."
Bastion Framework
"Bastion is a Java framework for implementing Domain-Driven Designed (DDD) applications."
Axon Framework
"The axon framework is focussed on making life easier for developers that want to create a java application based on the CQRS principles."
Jdon Framework
"Jdon Framework is a DDD( Domain-Driven Design ) + DCI + Domain Events(Event Sourcing/CQRS) framework for java."
- 3.1. Overview
- 3.2. Qi4j in 2 minutes
- 3.3. Qi4j in 10 minutes
- 3.4. Qi4j in 30 minutes
- 3.5. Qi4j in 2 hours
- 3.6. Depend on Qi4j in your build
- 3.7. Assemble an Application
- 3.8. Transient Composites Tutorial
- 3.9. Services Composites Tutorial
- 3.10. Use contextual fragments
- 3.11. Leverage Properties
- 3.12. Create a Constraint
- 3.13. Create a Concern
- 3.14. Create a SideEffect
- 3.15. Create an Entity
- 3.16. Configure a Service
- 3.17. Use I/O API
- 3.18. Build System
- 3.19. Writing Qi4j Documentation
| Tip | |
|---|---|
Theses tutorials are based on actual code found in the |
In this section you will find a comprehensive set of tutorials about Composite Oriented Programming using Qi4j.
This quite long introduction to Qi4j will start by brushing up an overview of the problems Qi4j solve, teach you what Composite Oriented Programming is and guide you through the process of writing a complete Application around an adapted Hello World example.
Throughout this set of tutorials it will be shown how to depend on Qi4j in your build, how to assemble a complete application, how to create and work with Composites and Services, how to use contextual fragments and leverage properties.
In this other set of tutorials it will be shown how to achieve tasks that frequently arise during the development of a typical application.
This last set of tutorials you’ll learn how to build the Qi4j SDK from sources including this very documentation website , the Qi4j manual, binaries and sources distributions.
| Tip | |
|---|---|
Theses tutorials are based on actual code found in the |
To show that Qi4j is not necessarily complex, not hard to get going with and easy to deploy, we are first showing the classic HelloWorld, as small as it can get and still be Composite Oriented Programming and not only standard OOP.
If you want to reproduce what’s explained in this tutorial, remember to depend on the Core Runtime artifact that depends on Core API, Core SPI, Core Bootstrap and Core Functional & I/O APIs:
See the Depend on Qi4j in your build tutorial for details.
Ready, Set, Go!
Let’s say we want to do the common HelloWorld example, but with a more domain-oriented setting.
We have a Speaker interface that does the talking.
But we also need an implementation for Speaker, which we declare here via the @Mixins( SpeakerMixin.class ).
@Mixins( SpeakerMixin.class )
public interface Speaker
{
String sayHello();
}
And of course, the simple implementation of the Speaker interface. In this case, return a String with the content "Hello, World!".
public class SpeakerMixin
implements Speaker
{
@Override
public String sayHello()
{
return "Hello, World!";
}
}
So far so good. We now need to make this into something that can run. This can be done like this;
public class Main
{
public static void main( String[] args )
throws Exception
{
SingletonAssembler assembler = new SingletonAssembler() // <1>
{
@Override
public void assemble( ModuleAssembly assembly )
throws AssemblyException
{
assembly.transients( Speaker.class ); // <2>
}
};
Speaker speaker = assembler.module().newTransient( Speaker.class ); // <3>
System.out.println( speaker.sayHello() );
}
}
- The SingletonAssembler is a convenience class that creates a Qi4j Runtime instance and an application with one layer and one module in it.
-
We declare a TransientComposite of type
Speaker. - We create the Composite instance from the Module.
Done!
| Tip | |
|---|---|
Theses tutorials are based on actual code found in the |
- Qi4j does not introduce any new programming language, no additional compilers needed and all your existing tools work just like before. It is pure Java.
- Qi4j works with Composites.
- The equivalent of an Object instance in OOP, is a Composite instance in Qi4j.
- Composites are constructed from Fragments.
- Fragments are Mixins, Concerns, Constraints and SideEffects.
- Only Mixins carry Composite state. The others are shared between Composite instances.
If you want to reproduce what’s explained in this tutorial, remember to depend on the Core Runtime artifact that depends on Core API, Core SPI, Core Bootstrap and Core Functional & I/O APIs:
Moreover, you’ll need an EntityStore for persistence and an Indexing engine for querying. Choose among the available implementations listed in the Extensions section.
See the Depend on Qi4j in your build tutorial for details.
Composition is done with Java interfaces and Annotations. Example;
@Concerns( { PurchaseLimitConcern.class, InventoryConcern.class } )
public interface OrderEntity
extends Order, Confirmable,
HasSequenceNumber, HasCustomer, HasLineItems,
EntityComposite
{
}
This Composite is potentially complete. The Composite interface has a Mixin declared which is always present, the PropertyMixin, which will handle all properties we use. The two Concerns are interceptors that are placed on the methods that they declare, for instance;
public class InventoryConcern extends ConcernOf<Order>
implements Order
{
@Service
private InventoryService inventory;
@Override
public void addLineItem( LineItem item )
{
String productCode = item.productCode().get();
int quantity = item.quantity().get();
inventory.remove( productCode, quantity );
next.addLineItem( item );
}
@Override
public void removeLineItem( LineItem item )
{
String productCode = item.productCode().get();
int quantity = item.quantity().get();
inventory.add( productCode, quantity );
next.removeLineItem( item );
}
}
Extending the ConcernOf is a convenience mechanism, instead of an explicit @ConcernFor annotation on a private field,
which can be used in rare occasions when you are not able to extend. This base class defines the next field, which is
set up by the Qi4j runtime and points to the next fragment in the call stack.
We can also see that the InventoryService is provided to the concern, which is done with dependency injection. Qi4j also supports dependency injection via constructors and methods.
The above example is obviously doing persistence, and we have no code handling this. But Qi4j supports persistence directly in its Core, and it is taken care of by Qi4j, since it is declared as an EntityComposite. Nothing else is needed, provided that the Qi4j Runtime has been setup with one or more persisted EntityStores. But we have a naming convention that EntityComposites have "Entity" as the suffix in its name.
There are other built-in Composite subtypes as well, such as ValueComposite and ServiceComposite. This distinction helps both to communicate intent as well as having more precisely defined functionality.
Now, let’s say that we want to send a mail to sales@mycompany.com when the order is confirmed. This is a SideEffect, and will execute after the Constraints, Concerns and Mixins. We add the SideEffect to the OrderEntity;
@SideEffects( MailNotifySideEffect.class )
@Concerns( { PurchaseLimitConcern.class, InventoryConcern.class } )
public interface OrderEntity
extends Order, Confirmable,
HasSequenceNumber, HasCustomer, HasLineItems,
EntityComposite
{
The SideEffect implementation is fairly simple.
public abstract class MailNotifySideEffect extends SideEffectOf<Confirmable>
implements Confirmable
{
@Service
private MailService mailer;
@This
private HasLineItems hasItems;
@This
private HasCustomer hasCustomer;
@Override
public void confirm()
{
StringBuilder builder = new StringBuilder();
builder.append( "An Order has been made.\n\n\n" );
builder.append( "Customer:" );
builder.append( hasCustomer.name().get() );
builder.append( "\n\nItems ordered:\n" );
for( LineItem item : hasItems.lineItems().get() )
{
builder.append( item.name().get() );
builder.append( " : " );
builder.append( item.quantity().get() );
builder.append( "\n" );
}
mailer.send( "sales@mycompany.com", builder.toString() );
}
}
The MailService is dependency injected, as we have seen before.
@This is telling Qi4j that the SideEffect needs a reference to the Composite instance that it belongs to.
By asking for both the HasCustomer and the HasLineItems types, we get type-safety and don’t need to bother with casts.
In fact, Qi4j will ensure that you can’t even cast the hasCustomer instance to the HasLineItems type.
By not referencing the aggregated interface OrderEntity, we reduce the coupling of this SideEffect and it can be used in any other Composite where the HasCustomer and HasLineItems combination is used, for instance in an InvoiceEntity.
So, build the report, send it via the MailService.
In this short introduction, we have covered the essence of Qi4j. We have looked at what is a Composite, seen some of the Fragments in action, and how simple it is to turn a Composite into a persisted Composite, known as an EntityComposite.
| Tip | |
|---|---|
Theses tutorials are based on actual code found in the |
This introduction will deepen your understanding of Qi4j, as we touches on a couple of the common features of Qi4j. It is expected that you have gone through and understood the "Qi4j in 10 minutes" introduction.
If you want to reproduce what’s explained in this tutorial, remember to depend on the Core Runtime artifact that depends on Core API, Core SPI, Core Bootstrap and Core Functional & I/O APIs:
Moreover, you’ll need an EntityStore for persistence and an Indexing engine for querying. Choose among the available implementations listed in the Extensions section.
See the Depend on Qi4j in your build tutorial for details.
We will go back to the OrderEntity example;
@Concerns( { PurchaseLimitConcern.class, InventoryConcern.class } )
public interface OrderEntity
extends Order, Confirmable,
HasSequenceNumber, HasCustomer, HasLineItems,
EntityComposite
{
}
Let’s say that this is an existing Composite, perhaps found in a library or used in a previous object, but we want to add that it tracks all the changes to the order and the confirmation of such order.
First we need to create (or also find in a library) the mechanics of the audit trail. It could be something like this;
public interface HasAuditTrail<M>
{
AuditTrail<M> auditTrail();
}
public interface AuditTrail<M> extends Property<List<Action<M>>>
{}
public interface Action<T> extends ValueComposite // [2][3]
{
enum Type { added, removed, completed };
@Optional Property<T> item(); // [1]
Property<Type> action(); // [1]
}
public interface Trailable<M>
{
void itemAdded( M item );
void itemRemoved( M item );
void completed();
}
public class TrailableMixin<M>
implements Trailable<M>
{
private @This HasAuditTrail<M> hasTrail;
@Override
public void itemAdded( M item )
{
addAction( item, Action.Type.added );
}
@Override
public void itemRemoved( M item )
{
addAction( item, Action.Type.removed );
}
@Override
public void completed()
{
addAction( null, Action.Type.completed );
}
private Action<M> addAction( M item, Action.Type type )
{
ValueBuilder<Action> builder =
module.newValueBuilder(Action.class); // [4]
Action<M> prototype = builder.prototypeFor( Action.class );
prototype.item().set( item );
prototype.action().set( type );
Action instance = builder.newInstance();
hasTrail.auditTrail().get().add( instance );
return instance;
}
}
Quite a lot of Qi4j features are leveraged above; [1] Property is a first class citizen in Qi4j, instead of getters/setters naming convention to declare properties. [2] ValueComposite for Action means that it is among other things Immutable. [3] The Action extends a Property. We call that Property subtyping and highly recommended. [4] The CompositeBuilder creates Immutable Action instances.
We also need a Concern to hang into the methods of the Order interface.
public abstract class OrderAuditTrailConcern
extends ConcernOf<Order>
implements Order
{
@This Trailable<LineItem> trail;
@Override
public void addLineItem( LineItem item )
{
next.addLineItem( item );
trail.itemAdded( item );
}
@Override
public void removeLineItem( LineItem item )
{
next.removeLineItem( item );
trail.itemRemoved( item );
}
@Override
public void completed()
{
next.completed();
trail.completed();
}
}
In this case, we have chosen to make an Order specific Concern for the more generic AuditTrail subsystem, and would belong in the client (Order) code and not with the library (AuditTrail). Pay attention to the @This annotation for a type that is not present in the Composite type interface. This is called a private Mixin, meaning the Mixin is only reachable from Fragments within the same Composite instance.
But the AuditTrail subsystem could provide a Generic Concern, that operates on a naming pattern (for instance). In this case, we would move the coding of the concern from the application developer to the library developer, again increasing the re-use value. It could look like this;
public class AuditTrailConcern
extends ConcernOf<InvocationHandler>
implements InvocationHandler
{
@This Trailable trail;
@Override
public Object invoke( Object proxy, Method m, Object[] args )
throws Throwable
{
Object retValue = next.invoke(proxy, m, args);
String methodName = m.getName();
if( methodName.startsWith( "add" ) )
{
trail.itemAdded( args[0] );
}
else if( methodName.startsWith( "remove" ) )
{
trail.itemRemoved( args[0] );
}
else if( methodName.startsWith( "complete" ) ||
methodName.startsWith( "commit" ) )
{
trail.completed();
}
return retValue;
}
}
The above construct is called a Generic Concern, since it implements java.lang.reflect.InvocationHandler instead of the interface of the domain model. The ConcernOf baseclass will also need to be of InvocationHandler type, and the Qi4j Runtime will handle the chaining between domain model style and this generic style of interceptor call chain.
Finally, we need to declare the Concern in the OrderEntity;
@Concerns({
AuditTrailConcern.class,
PurchaseLimitConcern.class,
InventoryConcern.class
})
@Mixins( TrailableMixin.class )
public interface OrderEntity
extends Order, Confirmable,
HasSequenceNumber, HasCustomer, HasLineItems,
EntityComposite
{
}
We also place it first, so that the AuditTrailConcern will be the first Concern in the interceptor chain (a.k.a InvocationStack), so that in case any of the other Concerns throws an Exception, the AuditTrail is not updated (In fact, the AuditTrail should perhaps be a SideEffect rather than a Concern. It is largely depending on how we define SideEffect, since the side effect in this case is within the composite instance it is a border case.).
So let’s move on to something more complicated. As we have mentioned, EntityComposite is automatically persisted to an underlying store (provided the Runtime is setup with one at bootstrap initialization), but how do I locate an Order?
Glad you asked. It is done via the Query API. It is important to understand that Indexing and Query are separated from the persistence concern of storage and retrieval. This enables many performance optimization opportunities as well as a more flexible Indexing strategy. The other thing to understand is that the Query API is using the domain model, in Java, and not some String based query language. We have made this choice to ensure refactoring safety. In rare cases, the Query API is not capable enough, in which case Qi4j still provides the ability to look up and execute native queries.
Let’s say that we want to find a particular Order from its SequenceNumber.
import static org.qi4j.api.query.QueryExpressions.eq;
import static org.qi4j.api.query.QueryExpressions.gt;
import static org.qi4j.api.query.QueryExpressions.templateFor;
import org.qi4j.api.query.QueryBuilder;
[...snip...]
@Structure private UnitOfWorkFactory uowFactory; //Injected
[...snip...]
UnitOfWork uow = uowFactory.currentUnitOfWork();
QueryBuilder<Order> builder = module.newQueryBuilder( Order.class );
String orderNumber = "12345";
HasSequenceNumber template = templateFor( HasSequenceNumber.class );
builder.where( eq( template.number(), orderNumber ) );
Query<Order> query = uow.newQuery( builder);
Iterator<Order> result = query.iterator();
if( result.hasNext() )
{
Order order = result.next();
}
else
{
// Deal with it wasn't found.
}
The important bits are;
- The QueryExpressions.templateFor() method is used to define the template used in the query upon execution. In this case, we choose to template only the HasSequenceNumber, an interface used in OrderEntity, but is not part of Order (may or may not be a good design choice).
- The where() clause, which has a statically imported method eq(), which builds up the expression logic, and will be translated into the underlying query language upon execution, which happens in the iterator() method.
Another example,
QueryBuilder<Order> builder = module.newQueryBuilder( Order.class );
Calendar cal = Calendar.getInstance();
cal.setTime( new Date() );
cal.roll( Calendar.DAY_OF_MONTH, -90 );
Date last90days = cal.getTime();
Order template = templateFor( Order.class );
builder.where( gt( template.createdDate(), last90days ) );
Query<Order> query = uow.newQuery(builder);
for( Order order : query )
{
report.addOrderToReport( order );
}
In the above case, we find the Orders that has been created in the last 90 days, and add them to a report to be generated. This example assumes that the Order type has a Property<Date> createdDate() method.
Now, Orders has a relation to the CustomerComposite which is also an Entity. Let’s create a query for all customers that has made an Order in the last 30 days;
QueryBuilder<HasCustomer> builder = module.newQueryBuilder( HasCustomer.class );
Calendar cal = Calendar.getInstance();
cal.setTime( new Date() );
cal.roll( Calendar.MONTH, -1 );
Date lastMonth = cal.getTime();
Order template1 = templateFor( Order.class );
builder.where( gt( template1.createdDate(), lastMonth ) );
Query<HasCustomer> query = uow.newQuery(builder);
for( HasCustomer hasCustomer : query )
{
report.addCustomerToReport( hasCustomer.name().get() );
}
This covers the most basic Query capabilities and how to use it. For Querying to work, an Indexing subsystem must be assembled during bootstrap. At the time of this writing, only an RDF indexing subsystem exist, and is added most easily by assembly.addAssembler( new RdfNativeSesameStoreAssembler() ).
It can be a bit confusing to see Qi4j use Java itself as a Query language, but since we have practically killed the classes and only operate with interfaces, it is possible to do a lot of seemingly magic stuff. Just keep in mind that it is pure Java, albeit heavy use of dynamic proxies to capture the intent of the query.
We have now explored a couple more intricate features of Qi4j, hopefully without being overwhelmed with details on how to create applications from scratch, how to structure applications, and how the entire Qi4j Extension system works. We have looked at how to add a Concern that uses a private Mixin, we have touched a bit on Generic Concerns, and finally a short introduction to the Query API.
| Note | |
|---|---|
This tutorial is not written yet. Learn how to contribute in Writing Documentation. |
This introduction assumes that the "Qi4j in 10 minutes" and "Qi4j in 30 minutes" introductions has been read and understood.
In this introduction we will touch on the core concepts of UnitOfWork, Application structure and Bootstrap API.
- Persistence and UnitOfWork -
We have previously seen that it is easy to declare that a Composite should be persisted, but not touched on how to interact with the underlying persistence system. This is done via EntitySessions.
Application Structure -
- There are one Application per Qi4j instance.
- An Application consists of one or more Layers.
- Each Layer consist of one or more Modules.
- Layers are organized in a top-down manner, lower Layers on top of higher Layers.
- One must declare which Composites that each Module is responsible for.
- A Composite can either be private or public in the Module.
- A private Composite can only be reached from within the same Module.
- A public Composite can be reached from other Modules in the same Layer.
- A public Composite can be declared to be public in the Layer.
- A Composite that is declared public in the Layer can be reached from the Layers directly on top (not transitive to Layers higher up).
- The Application can also declare public Composites (later for SCA).
For simpler Applications it is possible (quite easily) to create a single Layer with a single Module, but for more complex Applications we strongly recommend the partitioned approach.
Bootstrap API
— to be continued
| Note | |
|---|---|
Some of the Libraries and Extensions depend on artifacts that are not deployed in central, you’ll need to add other repositories to your build scripts accordingly. |
Release artifacts, including sources and javadoc, are deployed to
https://repository-qi4j.forge.cloudbees.com/release/.
Snapshot artifacts, including sources and javadoc, are built against the develop branch and deployed weekly to
https://repository-qi4j.forge.cloudbees.com/snapshot/.
As they are not deployed to central you need to add the repositories to your build scripts.
If you don’t rely on your build scripts dependency resolution mechanism you should download the SDK distribution.
First you need to register the Qi4j repositories:
<!-- ... -->
<repositories>
<!-- ... -->
<repository>
<id>qi4j-releases</id>
<url>https://repository-qi4j.forge.cloudbees.com/release/</url>
</repository>
<repository>
<id>qi4j-snapshots</id>
<url>https://repository-qi4j.forge.cloudbees.com/snapshot/</url>
<releases><enabled>false</enabled></releases>
<snapshots><enabled>true</enabled></snapshots>
</repository>
<!-- ... -->
</repositories>
<!-- ... -->After that you can declare dependencies on Qi4j artifacts:
<!-- ... -->
<dependencies>
<!-- ... -->
<dependency>
<groupId>org.qi4j.core</groupId>
<artifactId>org.qi4j.core.bootstrap</artifactId>
<version>QI4J_VERSION</version>
</dependency>
<dependency>
<groupId>org.qi4j.core</groupId>
<artifactId>org.qi4j.core.runtime</artifactId>
<version>QI4J_VERSION</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.qi4j.core</groupId>
<artifactId>org.qi4j.core.testsupport</artifactId>
<version>QI4J_VERSION</version>
<scope>test</scope>
</dependency>
<!-- ... -->
</dependencies>
<!-- ... -->Where QI4J_VERSION is the Qi4j version you want to use.
First you need to register the Qi4j repositories:
// ...
repositories {
// ...
mavenRepo name: 'qi4j-releases', url: "https://repository-qi4j.forge.cloudbees.com/release/"
mavenRepo name: 'qi4j-snapshots', url: "https://repository-qi4j.forge.cloudbees.com/snapshot/"
// ...
}
// ...After that you can declare dependencies on Qi4j artifacts:
// ...
dependencies {
// ...
compile "org.qi4j.core:org.qi4j.core.bootstrap:QI4J_VERSION"
runtime "org.qi4j.core:org.qi4j.core.runtime:QI4J_VERSION"
test "org.qi4j.core:org.qi4j.core.testsupport:QI4J_VERSION"
// ...
}
// ...Where QI4J_VERSION is the Qi4j version you want to use.
First you need to register the Qi4j repositories:
# ... repositories.remote << 'https://repository-qi4j.forge.cloudbees.com/release/' repositories.remote << 'https://repository-qi4j.forge.cloudbees.com/snapshot/' # ...
After that you can declare dependencies on Qi4j artifacts:
# ... compile.with 'org.qi4j.core:org.qi4j.core.bootstrap:QI4J_VERSION' package(:war).with :libs => 'org.qi4j.core:org.qi4j.core.runtime:QI4J_VERSION' test.with 'org.qi4j.core:org.qi4j.core.testsupport:QI4J_VERSION' # ...
Where QI4J_VERSION is the Qi4j version you want to use.
First you need to register the Qi4j repositories:
// ... resolvers += "qi4j-releases" at "https://repository-qi4j.forge.cloudbees.com/release/" resolvers += "qi4j-snapshots" at "https://repository-qi4j.forge.cloudbees.com/snapshot/" // ...
After that you can declare dependencies on Qi4j artifacts:
// ...
libraryDependencies += \
"org.qi4j.core" % "org.qi4j.core.bootstrap" % "QI4J_VERSION" \
withSources() withJavadoc()
libraryDependencies += \
"org.qi4j.core" % "org.qi4j.core.runtime" % "QI4J_VERSION" % "runtime" \
withSources() withJavadoc()
libraryDependencies += \
"org.qi4j.core" % "org.qi4j.core.testsupport" % "QI4J_VERSION" % "test" \
withSources() withJavadoc()
// ...Where QI4J_VERSION is the Qi4j version you want to use.
First you need to register the Qi4j repositories in a ivysettings.xml file:
<ivysettings>
<settings defaultResolver="chain"/>
<resolvers>
<chain name="chain">
<!-- ... -->
<ibiblio name="qi4j-releases" m2compatible="true"
root="https://repository-qi4j.forge.cloudbees.com/release/"/>
<ibiblio name="qi4j-snapshots" m2compatible="true"
root="https://repository-qi4j.forge.cloudbees.com/snapshot/"/>
<!-- ... -->
</chain>
</resolvers>
</ivysettings>After that you can declare dependencies on Qi4j artifacts:
<ivy-module>
<!-- ... -->
<dependencies>
<!-- ... -->
<dependency org="org.qi4j.core" name="org.qi4j.core.bootstrap"
rev="QI4J_VERSION" conf="default" />
<dependency org="org.qi4j.core" name="org.qi4j.core.runtime"
rev="QI4J_VERSION" conf="runtime" />
<dependency org="org.qi4j.core" name="org.qi4j.core.testsupport"
rev="QI4J_VERSION" conf="test" />
<!-- ... -->
</dependencies>
<!-- ... -->
</ivy-module>Where QI4J_VERSION is the Qi4j version you want to use.
We receive a lot of questions about how applications should be assembled, and since we don’t have any XML to "fill in" and everything is to be done programmatically, it escalates the need to provide more hands-on explanation of how this is done.
If you want to reproduce what’s explained in this tutorial, remember to depend on the Core Bootstrap artifact:
At runtime you will need the Core Runtime artifact too. See the Depend on Qi4j in your build tutorial for details.
First let’s recap the structural requirements of Qi4j;
- There is one and only one Application instance per Qi4j Runtime.
- Every Application must contain one or more Layers.
- All Composites must be declared in one or more Modules.
- Each Module belong to a Layer.
- Layers are ordered in hierarchies, from simple to complex.
- Access to Composites are limited by visibility rules.
Ok, that was quite a handful. Let’s look at them one by one.
The first one means that for each Qi4j Runtime you start, there will be exactly one application. As far as we know, Qi4j is fully isolated, meaning there are no static members being populated and such.
Layers are the super-structures of an application. We have been talking about them for decades, drawn them on paper and whiteboards (or even black boards for those old enough), and sometimes organized the codebases along such boundaries. But, there has been little effort to enforce the Layer mechanism in code, although it is an extremely powerful construct. First of all it implies directional dependency and a high degree of order, spagetti code is reduced if successfully implemented. For Qi4j, it means that we can restrict access to Composite and Object declarations, so that higher layers can not reach them incidentally. You can enforce architecture to a high degree. You can require all creation of composites to go through an exposed Factory, which doesn’t require the Composite to be public. And so on. Layers have hierarchy, i.e. one layer is top of one or more layers, and is below one or more layers, except for the layers at the top and bottom. You could have disjoint layers, which can’t access each other, meaning a couple of layers that are both the top and bottom.
The Module concept has also been around forever. And in Qi4j we also makes the Modules explicit. Each Module belong to a Layer, and for each Module you declare the Composite and Object types for that Module, together with a Visibility rule, one of; application, layer, module.
The Visibility rules are perhaps the most powerful aspect of the above. Visibility is a mechanism that kicks in whenever a Composite type need to be looked up. It defines both the scoping rules of the client as well as the provider. A lookup is either a direct reference, such as
UnitOfWork unitOfWork = module.currentUnitOfWork(); PersonEntity person = unitOfWork.newEntity( PersonEntity.class );
or an indirect lookup, such as
UnitOfWork unitOfWork = module.currentUnitOfWork(); Person person = unitOfWork.newEntity( Person.class );
where it will first map the Person to a reachable PersonEntity. The algorithm is as follows;
- Look in the callers Module, if there is one and only one Composite type matching, use it. If there are two or more Composite types matching, then throw an ambiguity exception. If there are zero, proceed to the next step.
- Look in all Modules in the callers Layer. If there is one and only one Composite type that matches and is either Visibility.layer, then use it. If there are two or more Composite types matching, then throw an ambiguity exception. If there are zero, proceed to the next step.
- Look in all Layers that caller’s Layer uses. If there is one and only one Composite type that matches and is either Visibility.application, then use it. If there are two or more Composite types matching, then throw an ambiguity exception. If there are zero, proceed to the next step.
- Throw a CompositeNotFoundException.
The underlying principle comes down to Rickard’s "Speaker Analogy", you can hear him (and not the other speakers at the conference) because you are in the same room. I.e. if something is really close by, it is very likely that this is what we want to use, and then the search expands outwards.
Ok, that was a whole lot of theory and probably take you more than one read-through to fully get into your veins (slow acting addiction). How to structure your code is beyond the scope of this section. If you are an experienced designer, you will have done that before, and you may have started out with good intentions at times only to find yourself in a spaghetti swamp later, or perhaps in the also famous "Clear as Clay" or "Ball (bowl?) of Mud". Either way, you need to draw on your experience and come up with good structure that Qi4j lets you enforce.
So, for the sake of education, we are going to look at an application that consists of many layers, each with a few modules. See picture below.
Image of Example of Layers
Figure 1. Example of Layers
So, lets see how we code up this bit in the actual code first.
public class Main
{
private static Energy4Java qi4j;
private static Application application;
public static void main( String[] args )
throws Exception
{
// Bootstrap Qi4j Runtime
// Create a Qi4j Runtime
qi4j = new Energy4Java();
// Instantiate the Application Model.
application = qi4j.newApplication( new ApplicationAssembler()
{
public ApplicationAssembly assemble(
ApplicationAssemblyFactory factory )
throws AssemblyException
{
ApplicationAssembly assembly =
factory.newApplicationAssembly();
LayerAssembly runtime = createRuntimeLayer( assembly );
LayerAssembly designer = createDesignerLayer( assembly );
LayerAssembly domain = createDomainLayer( assembly );
LayerAssembly messaging= createMessagingLayer( assembly );
LayerAssembly persistence = createPersistenceLayer( assembly );
// declare structure between layers
domain.uses( messaging );
domain.uses( persistence );
designer.uses( persistence );
designer.uses( domain );
runtime.uses( domain );
return assembly;
}
} );
// We need to handle shutdown.
installShutdownHook();
// Activate the Application Runtime.
application.activate();
}
[...snip...]
}
The above is the basic setup on how to structure a real-world applicaton, unless you intend to mess with the implementations of various Qi4j systems (yes there are hooks for that too), but that is definitely beyond the scope of this tutorial.
Now, the createXyzLayer() methods were excluded to keep the sample crisp and easy to follow. Let’s take a look at what it could be to create the Domain Layer.
private static LayerAssembly createDomainLayer( ApplicationAssembly app )
{
LayerAssembly layer = app.layer("domain-layer");
createAccountModule( layer );
createInventoryModule( layer );
createReceivablesModule( layer );
createPayablesModule( layer );
return layer;
}
We just call the layerAssembly() method, which will return either an existing Layer with that name or create a new one if one doesn’t already exist, and then delegate to methods for creating the ModuleAssembly instances. In those method we need to declare which Composites, Entities, Services and Objects that is in each Module.
private static void createAccountModule( LayerAssembly layer )
{
ModuleAssembly module = layer.module("account-module");
module.entities(AccountEntity.class, EntryEntity.class);
module.addServices(
AccountRepositoryService.class,
AccountFactoryService.class,
EntryFactoryService.class,
EntryRepositoryService.class
).visibleIn( Visibility.layer );
}
We also need to handle the shutdown case, so in the main() method we have a installShutdownHook() method call. It is actually very, very simple;
private static void installShutdownHook()
{
Runtime.getRuntime().addShutdownHook( new Thread( new Runnable()
{
public void run()
{
if( application != null )
{
try
{
application.passivate();
}
catch( Exception e )
{
e.printStackTrace();
}
}
}
}) );
}
This concludes this tutorial. We have looked how to get the initial Qi4j runtime going, how to declare the assembly for application model creation and finally the activation of the model itself.
| Tip | |
|---|---|
Theses tutorials are based on actual code found in the |
Throughout this set of tutorials it will be shown how to create and work with Composites, which is the basic element in Qi4j. We will refactor one HelloWorld class to take advantage of the various features in Qi4j. These refactorings will make it easier to reuse parts of the class, and introduce new features without having to change existing code. We will also look at some of the existing classes, or Fragments, available in Qi4j that you can reuse so that you don’t have to write everything yourself.
Each tutorial step in this series starts with the result from the previous tutorial, so you can always look at the next tutorial step for guidance on what to do.
At the bottom of each tutorial step, the is Solutions section, which list the files you should have come to if you have followed the instructions.
If you want to reproduce what’s explained in this tutorial, remember to depend on the Core Runtime artifact that depends on Core API, Core SPI, Core Bootstrap and Core Functional & I/O APIs:
See the Depend on Qi4j in your build tutorial for details.
This whole tutorial describes how to step-by-step modify a typical HelloWorld "application" into a full-fledged Qi4j Composite Oriented application. Here is the initial code of HelloWorld.
/**
* Initial HelloWorld implementation. Everything is mixed up
* into one class, and no interface is used.
*/
public class HelloWorld
{
String phrase;
String name;
public String getPhrase()
{
return phrase;
}
public void setPhrase( String phrase )
throws IllegalArgumentException
{
if( phrase == null )
{
throw new IllegalArgumentException( "Phrase may not be null " );
}
this.phrase = phrase;
}
public String getName()
{
return name;
}
public void setName( String name )
throws IllegalArgumentException
{
if( name == null )
{
throw new IllegalArgumentException( "Name may not be null " );
}
this.name = name;
}
public String say()
{
return phrase + " " + name;
}
}
In this step we start with a basic Java class, which when invoked will concatenate the two properties "phrase" and "name". If invoked with the properties set to "Hello" and "World" respectively it will hence return "Hello World".
Qi4j relies heavily on the use of interfaces. This makes it possible for an object to externally implement a number of interfaces which internally is backed by a number of Mixins, some of which you may have written yourself, and some of which may have been reused. This also makes it easy to introduce Modifiers (aka "interceptors", aka "advice"), which are Fragments which execute before and/or after the method on the Mixin is invoked.
The first task is therefore to refactor the code so that the method is implemented from an interface instead. We should then also separate the state into one interface and the behaviour into another. This will make things easier for us later when state and behaviour becomes implemented by separate Mixins.
Steps for this tutorial:
- Refactor the class into interface and implementation.
- Refactor the interface so that it extends one interface called HelloWorldBehaviour with behaviour and one called HelloWorldState with state (get/set methods).
If you have successfully completed the task, you should end up with the following artifacts;
HelloWorld.java
/**
* This interface aggregates the behaviour and state
* of the HelloWorld sub-interfaces. To a client
* this is the same as before though, since it only
* has to deal with this interface instead of the
* two sub-interfaces.
*/
public interface HelloWorld
extends HelloWorldBehaviour, HelloWorldState
{
}
HelloWorldState.java
/**
* This interface contains only the state
* of the HelloWorld object.
* The exceptions will be thrown by Qi4j automatically if
* null is sent in as values. The parameters would have to be declared
* as @Optional if null is allowed.
*/
public interface HelloWorldState
{
void setPhrase( String phrase )
throws IllegalArgumentException;
String getPhrase();
void setName( String name )
throws IllegalArgumentException;
String getName();
}
HelloWorldBehaviour.java
/**
* This interface contains only the behaviour
* of the HelloWorld object.
*/
public interface HelloWorldBehaviour
{
String say();
}
HelloWorldMixin.java
/**
* This is the implementation of the HelloWorld
* interface. The behaviour and state is mixed.
*/
public class HelloWorldMixin
implements HelloWorld
{
String phrase;
String name;
@Override
public String say()
{
return getPhrase() + " " + getName();
}
@Override
public void setPhrase( String phrase )
throws IllegalArgumentException
{
if( phrase == null )
{
throw new IllegalArgumentException( "Phrase may not be null" );
}
this.phrase = phrase;
}
@Override
public String getPhrase()
{
return phrase;
}
@Override
public void setName( String name )
throws IllegalArgumentException
{
if( name == null )
{
throw new IllegalArgumentException( "Name may not be null" );
}
this.name = name;
}
@Override
public String getName()
{
return name;
}
}
Next step is Step 2 - Creating a Transient Composite
Previous step was Step 1 - Interface Refactoring.
In this step we will create a TransientComposite interface that ties all pieces together. The TransientComposite interface is a regular Java interface which extends the interfaces you want to expose from your domain model, and which uses various annotations to declare what Fragments to include. Fragments include Mixins, Concerns, SideEffects and Constraints. In this tutorial we will only use Mixins. When a TransientComposite is instantiated at runtime the framework will inspect the interface to determine what the TransientComposite instance should look like in terms of used Fragments.
In Qi4j all method parameters are considered mandatory unless marked as @Optional. Therefore you can remove the null checks in the Mixin. If a null value is passed in an exception will be thrown by Qi4j.
Steps for this tutorial:
- Create an interface that extends the domain interface HelloWorld and org.qi4j.api.composite.TransientComposite.
- Add a @Mixins annotation to it with the name of the Mixin as argument.
These ones remain unchanged:
-
HelloWorld.java -
HelloWorldBehaviour.java -
HelloWorldState.java
HelloWorldComposite.java
/**
* This Composite interface declares all the Fragments
* of the HelloWorld composite.
* <p/>
* Currently it only declares one Mixin.
*/
@Mixins( HelloWorldMixin.class )
public interface HelloWorldComposite
extends HelloWorld, TransientComposite
{
}
HelloWorldMixin.java
/**
* This is the implementation of the HelloWorld
* interface. The behaviour and state is mixed.
*/
public class HelloWorldMixin
implements HelloWorld
{
String phrase;
String name;
@Override
public String say()
{
return getPhrase() + " " + getName();
}
@Override
public void setPhrase( String phrase )
throws IllegalArgumentException
{
if( phrase == null )
{
throw new IllegalArgumentException( "Phrase may not be null" );
}
this.phrase = phrase;
}
@Override
public String getPhrase()
{
return phrase;
}
@Override
public void setName( String name )
throws IllegalArgumentException
{
if( name == null )
{
throw new IllegalArgumentException( "Name may not be null" );
}
this.name = name;
}
@Override
public String getName()
{
return name;
}
}
Next step is Step 3 - Mixins
Previous step was Step 2 - Creating a Transient Composite.
In this step we refactor the Mixin from the previous steps into two, one which serves the behaviour interface and one which serves the state interface. This makes it possible to reuse the interfaces independently and also makes it easier to exchange one interface implementation with another. This also allows us to specify the new Mixins as default implementations of the interfaces by adding @Mixins annotations on them.
Steps for this tutorial:
- Refactor the Mixin into one which implement the behaviour interface and one which implements the state interface. Use the @This injection annotation to allow the behaviour to access the state.
- Add a @Mixins annotations on the behaviour and state interfaces which declare the Mixins as default implementations.
- Remove the @Mixins annotation from the TransientComposite interface.
Only HelloWorld.java remains unchanged.
HelloWorldComposite.java
/**
* This Composite interface declares all the Fragments
* of the HelloWorld composite.
* <p/>
* The Mixins annotation has been moved to the respective sub-interfaces.
* The sub-interfaces therefore declare themselves what mixin implementation
* is preferred. This interface could still have its own Mixins annotation
* with overrides of those defaults however.
*/
public interface HelloWorldComposite
extends HelloWorld, TransientComposite
{
}
HelloWorldBehaviour.java
/**
* This interface contains only the behaviour
* of the HelloWorld object.
* <p/>
* It declares what Mixin to use as default implementation.
*/
@Mixins( HelloWorldBehaviourMixin.class )
public interface HelloWorldBehaviour
{
String say();
}
HelloWorldBehaviourMixin.java
/**
* This is the implementation of the HelloWorld
* behaviour interface.
* <p/>
* It uses a @This Dependency Injection
* annotation to access the state of the Composite. The field
* will be automatically injected when the Composite
* is instantiated. Injections of resources or references
* can be provided either to fields, constructor parameters or method parameters.
*/
public class HelloWorldBehaviourMixin
implements HelloWorldBehaviour
{
@This
HelloWorldState state;
@Override
public String say()
{
return state.getPhrase() + " " + state.getName();
}
}
HelloWorldState.java
/**
* This interface contains only the state
* of the HelloWorld object.
* The exceptions will be thrown by Qi4j automatically if
* null is sent in as values. The parameters would have to be declared
* as @Optional if null is allowed.
*/
@Mixins( HelloWorldStateMixin.class )
public interface HelloWorldState
{
void setPhrase( String phrase )
throws IllegalArgumentException;
String getPhrase();
void setName( String name )
throws IllegalArgumentException;
String getName();
}
HelloWorldStateMixin.java
/**
* This is the implementation of the HelloWorld
* state interface.
*/
public class HelloWorldStateMixin
implements HelloWorldState
{
String phrase;
String name;
@Override
public String getPhrase()
{
return phrase;
}
@Override
public void setPhrase( String phrase )
{
this.phrase = phrase;
}
@Override
public String getName()
{
return name;
}
@Override
public void setName( String name )
{
this.name = name;
}
}
Next step is Step 4 - Concerns
Previous step was Step 3 - Mixins.
In this step we refactor the mixin from the previous steps so that the result of the say() method is modified to be prefixed with "Simon says:". To do this we need to implement a Concern for the say() method. Concerns are a type of Modifier which modify the behaviour of the methods in Mixins. They do this by intercepting the invocation of the TransientComposite. This allows them to change the invocation parameters, return their own values or throw their own exceptions, and do other things which directly affect the invocation of the method.
Concerns should not perform any side-effects, such as updating state in another TransientComposite, Mixin or similar. Any side-effects are done in SideEffects, which is another type of Modifier, which are allowed to perform side-effects but, in contrast to Concerns, cannot change the parameters or in any other way change the result of the invocation.
Concerns are implemented in one of two ways: either create a class which directly implements the interface whose methods should be modified, or create a generic Modifier by implementing the InvocationHandler interface (or subclass GenericConcern which does this for you). Add an @ConcernFor dependency injection, as a field, constructor parameter or method parameter, which has the same type as the interface the Concern implements. When the TransientComposite is invoked the Concern will be called, allowing it to perform it’s work. If the call should proceed, then invoke the method again on the injected object. The preferred way to do all of this is to subclass ConcernOf which does all of this for you.
Concerns are applied by adding an @Concerns annotation on the TransientComposite, the domain interface, or the Mixin implementation. Any of these works, and where to put it is a matter of design choice.
Steps for this tutorial:
- Create a typed concern, implement the HelloWorldBehaviour and let it modify the result of the base method by prefix the result with "Simon says:".
- Add an @Concerns annotation on the HelloWorldBehaviourMixin which references the Concern class.
If you have successfully completed the task, you should end up with the following artifacts;
These ones remain unchanged:
-
HelloWorld.java -
HelloWorldBehavior.java -
HelloWorldComposite.java -
HelloWorldState.java -
HelloWorldStateMixin.java
HelloWorldBehaviourMixin.java
/**
* This is the implementation of the HelloWorld
* behaviour interface.
* <p/>
* It uses a @This Dependency Injection
* annotation to access the state of the Composite. The field
* will be automatically injected when the Composite
* is instantiated. Injections of resources or references
* can be provided either to fields, constructor parameters or method parameters.
*/
@Concerns( HelloWorldBehaviourConcern.class )
public class HelloWorldBehaviourMixin
implements HelloWorldBehaviour
{
@This
HelloWorldState state;
@Override
public String say()
{
return state.getPhrase() + " " + state.getName();
}
}
HelloWorldBehaviourConcern.java
/**
* This is a concern that modifies the mixin behaviour.
*/
public class HelloWorldBehaviourConcern
extends ConcernOf<HelloWorldBehaviour>
implements HelloWorldBehaviour
{
@Override
public String say()
{
return "Simon says:" + next.say();
}
}
Next step is Step 5 - Constraints
Previous step was Step 4 - Concerns.
In this step we will look at how to use Constraints. When we pass parameters to methods in regular Java code the only restriction we can make is to denote a type. Any other constraints on the input value, such as whether the parameter is optional, integer ranges, string regular expressions, and so on, cannot be expressed, and so we have to put this into Javadoc, and then manually add these checks in the implementation class.
In Qi4j there is the option to use Constraints, which are further restrictions on the parameters. This is implemented by having an annotation that describes what the Constraint does, and then an implementation class that checks whether a specific value fulfills the Constraint or not.
| Note | |
|---|---|
The previous steps had a dependency to the Core API only. The constraints you’ve used in this step, introduce a new dependency to the Constraints Library, where all the constraint related classes reside. So update your classpath settings accordingly. |
There are a number of pre-written constraints in Qi4j which you can use. The null check of the original HelloWorld version is already handled by default since Qi4j considers method parameters to be mandatory if not explicitly marked with the @Optional annotation. So, instead of doing that check we will add other checks that are useful to make, such as ensuring that the passed in string is not empty.
The only thing you have to do is add the annotation @NotEmpty to the method parameters you want to constrain in this way. The annotation has a default implementation declared in it by using the @Constraints annotation. You can either just use this, which is the common case, or override it by declaring your own @Constraints annotation in the TransientComposite type.
You can add as many Constraint annotations you want to a parameter. All of them will be checked whenever a method is called.
Steps for this tutorial:
- Add @NotEmpty to the state parameters.
If you have successfully completed the task, you should end up with the following artifacts;
These ones remain unchanged:
-
HelloWorld.java -
HelloWorldComposite.java -
HelloWorldStateMixin.java
HelloWorldBehaviour.java
/**
* This interface contains only the behaviour
* of the HelloWorld object.
* <p/>
* It declares what Mixin to use as default implementation, and also the extra
* concern to be applied.
*/
@Concerns( HelloWorldBehaviourConcern.class )
@Mixins( HelloWorldBehaviourMixin.class )
public interface HelloWorldBehaviour
{
String say();
}
HelloWorldBehaviourMixin.java
/**
* This is the implementation of the HelloWorld
* behaviour interface.
* <p/>
* It uses a @This DependencyModel Injection
* annotation to access the state of the Composite. The field
* will be automatically injected when the Composite
* is instantiated. Injections of resources or references
* can be provided either to fields, constructor parameters or method parameters.
*/
public class HelloWorldBehaviourMixin
implements HelloWorldBehaviour
{
@This
HelloWorldState state;
@Override
public String say()
{
return state.getPhrase() + " " + state.getName();
}
}
HelloWorldBehaviourConcern.java
/**
* This Concern validates the parameters
* to the HelloWorldState interface.
*/
public class HelloWorldBehaviourConcern
extends ConcernOf<HelloWorldBehaviour>
implements HelloWorldBehaviour
{
@Override
public String say()
{
return "Simon says:" + next.say();
}
}
HelloWorldState.java
/**
* This interface contains only the state
* of the HelloWorld object.
* <p/>
* The parameters are declared as @NotEmpty, so the client cannot pass in empty strings
* as values.
*/
@Mixins( HelloWorldStateMixin.class )
public interface HelloWorldState
{
void setPhrase( @NotEmpty String phrase )
throws IllegalArgumentException;
String getPhrase();
void setName( @NotEmpty String name )
throws IllegalArgumentException;
String getName();
}
Next step is Step 6 - SideEffects
Previous step was Step 5 - Constraints.
The current say() method has a Concern that modifies its value. What if we instead want the value to be intact, but log that value to System.out? That would be considered a side-effect of the say() method, and should hence not be done in a Concern. It would be better to implement this in a SideEffect. SideEffects are executed after the Mixin and all Concerns for a method are done, which means that the final result has been computed. A SideEffect can access this result value, and then use that for further computation, but it should not change the value or throw an exception.
SideEffects can be either typed or generic, just like Concerns. In the typed case we are interested in specifying SideEffects for one or more particular methods, whereas in the generic case the SideEffect is not really relying on what method is being invoked. Both are useful in different scenarios.
The easiest way to implement a typed SideEffect is to subclass the SideEffectOf class. This gives you access to the result of the real method invocation by using the "next" field, which has the same type as the interface of the method you want the code to be a side-effect of. Note that calling "next" does not actually do anything, it only returns the value (or throws the exception, if one was thrown from the original method) that has already been computed. Similarly, since the method is already done, you can return anything from the SideEffect method. The framework will simply throw it away, and also ignore any exceptions that you throw in your code.
To declare that the SideEffect should be used you add the @SideEffects annotation to either the TransientComposite type, the Mixin type, or the Mixin implementation. Either works.
Steps for this tutorial:
- Create the SideEffect class that logs the result of say() to System.out.
- Add a @SideEffects annotation with the SideEffect to the HelloWorldComposite interface.
- Remove the Concern from the previous step.
- Move the HelloWorldStateMixin from the HelloWorldState to the HelloWorldComposite interface.
If you have successfully completed the task, you should end up with the following artifacts;
These ones remain unchanged:
-
HelloWorld.java -
HelloWorldBehaviourMixin.java -
HelloWorldStateMixin.java
HelloWorldBehaviour.java
/**
* This interface contains only the behaviour
* of the HelloWorld object.
*/
public interface HelloWorldBehaviour
{
String say();
}
HelloWorldBehaviourSideEffect.java
/**
* As a side-effect of calling say, output the result.
*/
public class HelloWorldBehaviourSideEffect
extends SideEffectOf<HelloWorldBehaviour>
implements HelloWorldBehaviour
{
@Override
public String say()
{
System.out.println( result.say() );
return null;
}
}
HelloWorldComposite.java
/**
* This Composite interface declares transitively
* all the Fragments of the HelloWorld composite.
* <p/>
* It declares that the HelloWorldBehaviourSideEffect should be applied.
*/
@Mixins( { HelloWorldBehaviourMixin.class, HelloWorldStateMixin.class } )
@SideEffects( HelloWorldBehaviourSideEffect.class )
public interface HelloWorldComposite
extends HelloWorld, TransientComposite
{
}
HelloWorldState.java
/**
* This interface contains only the state
* of the HelloWorld object.
* <p/>
* The parameters are declared as @NotEmpty, so the client cannot pass in empty strings
* as values.
*/
public interface HelloWorldState
{
void setPhrase( @NotEmpty String phrase )
throws IllegalArgumentException;
String getPhrase();
void setName( @NotEmpty String name )
throws IllegalArgumentException;
String getName();
}
Next step is Step 7 - Properties
Previous step was Step 6 - SideEffects.
One of the goals of Qi4j is to give you domain modeling tools that allow you to more concisely use domain concepts in code. One of the things we do rather often is model Properties of objects as getters and setters. But this is a very weak model, and does not give you any access to metadata about the property, and also makes common tasks like UI binding non-trivial. There is also a lot of repetition of code, which is unnecessary. Using JavaBeans conventions one typically have to have code in five places for one property, whereas in Qi4j the same thing can be achieved with one line of code.
But lets start out easy. To declare a property you have to make a method in a mixin type that returns a value of the type Property, and which does not take any parameters. Here’s a simple example:
Property<String> name();
This declares a Property of type String with the name "name". The Property interface has methods "get" and "set" to access and mutate the value, respectively.
For now you will be responsible for implementing these methods, but later on these will be handled automatically, thus reducing Properties to one-liners!
In the Mixin implementation of the interface with the Property declaration you should have an injection of the Property, which is created for you by Qi4j. The injection can be done in a field like this:
@State Property<String> name;
The State dependency injection annotation means that Qi4j will inject the Property for you. The field has the name "name", which matches the name in the interface, and therefore that Property is injected. You can then implement the method trivially by just returning the "name" field.
Properties can have Constraints just like method parameters. Simply set them on the Property method instead, and they will be applied just as before when you call "set".
Steps for this tutorial:
- Remove JavaBeans properties from HelloWorldState.
- Remove HelloWorld and add the HelloWorldState and HelloWorldBehavior to the HelloWorldComposite interface.
- Remove the HelloWorldBehaviourSideEffect.
- Update the behaviour mixin to use the state interface accordingly.
- Add Property methods with the correct type and the @NotEmpty annotation.
- Update the state mixin to inject and return the properties as described above.
If you have successfully completed the task, you should end up with the following artifacts;
Only HelloWorldBehavior.java remains unchanged.
Theses ones are deleted:
-
HelloWorld.java -
HelloWorldConcern.java
HelloWorldBehaviourMixin.java
/**
* This is the implementation of the HelloWorld
* behaviour interface.
* <p/>
* This version access the state using Qi4j Properties.
*/
public class HelloWorldBehaviourMixin
implements HelloWorldBehaviour
{
@This
HelloWorldState state;
@Override
public String say()
{
return state.phrase().get() + " " + state.name().get();
}
}
HelloWorldComposite.java
/**
* This Composite interface declares transitively
* all the Fragments of the HelloWorld composite.
*/
@Mixins( { HelloWorldBehaviourMixin.class, HelloWorldStateMixin.class } )
public interface HelloWorldComposite
extends HelloWorldBehaviour, HelloWorldState, TransientComposite
{
}
HelloWorldState.java
/**
* This interface contains only the state
* of the HelloWorld object.
* <p/>
* The state is now declared using Properties. The @NotEmpty annotation is applied to the
* method instead, and has the same meaning as before.
*/
public interface HelloWorldState
{
@NotEmpty
Property<String> phrase();
@NotEmpty
Property<String> name();
}
HelloWorldStateMixin.java
/**
* This is the implementation of the HelloWorld
* state interface.
*/
public class HelloWorldStateMixin
implements HelloWorldState
{
@State
private Property<String> phrase;
@State
private Property<String> name;
@Override
public Property<String> phrase()
{
return phrase;
}
@Override
public Property<String> name()
{
return name;
}
}
Next step is Step 8 - Generic Mixins
Previous step was Step 7 - Properties.
In this step we will look at how to use generic Fragments. So far all Fragments, i.e. the Concerns, SideEffects, and Mixins, have directly implemented the domain interface. But sometimes it is useful to be able to provide a generic implementation of an interface. An example of this is the HelloWorldState interface. Since it only handles properties, and the old version used the JavaBean rules for naming getters and setters we could create a mixin that handles invocations of such methods automatically for us by storing the properties in a map and use the methods to look them up.
Implementing a generic Fragment is done by creating a class that implements the interface java.lang.proxy.InvocationHandler. This has a single "invoke" method which is passed the object that was invoked (the TransientComposite in this case), the method, and the arguments. The Fragment is then allowed to implement the method any way it wants.
Since interfaces with only Properties is such a common case Qi4j already has a generic Mixin that implements the Properties management described above, but for the builtin Property type instead of the getter/setter variant. The class is aptly named PropertyMixin.
While we could use it, for now we will implement it ourselves to get a feel for how generic Mixins work.
Steps for this tutorial:
- Remove the HelloWorldStateMixin
- Add a GenericPropertyMixin, and have it implement InvocationHandler
- Inject "@State StateHolder state" in the mixin. The StateHolder interface will give you access to the Properties for the TransientComposite which Qi4j manages for you
- On call to invoke(), delegate to the StateHolder interface to get the Property for the invoked method
- Add an @AppliesTo annotation to the Mixin and implement the AppliesToFilter with a rule that matches only methods that return Property values.
- Add the mixin to the TransientComposite.
If you have successfully completed the task, you should end up with the following artifacts;
These ones remain unchanged:
-
HelloWorldBehaviour.java -
HelloWorldState.java
GenericPropertyMixin.java
@AppliesTo( { GenericPropertyMixin.PropertyFilter.class } )
public class GenericPropertyMixin
implements InvocationHandler
{
@State
private StateHolder state;
@Override
public Object invoke( Object proxy, Method method, Object[] args )
throws Throwable
{
return state.propertyFor( method );
}
public static class PropertyFilter
implements AppliesToFilter
{
@Override
public boolean appliesTo( Method method, Class<?> mixin, Class<?> compositeType, Class<?> modifierClass )
{
return Property.class.isAssignableFrom( method.getReturnType() );
}
}
}
HelloWorldBehaviourMixin.java
/**
* This is the implementation of the HelloWorld
* behaviour interface.
*/
public class HelloWorldBehaviourMixin
implements HelloWorldBehaviour
{
@This
HelloWorldState state;
@Override
public String say()
{
return state.phrase().get() + " " + state.name().get();
}
}
HelloWorldComposite.java
/**
* This Composite interface declares transitively
* all the Fragments of the HelloWorld composite.
* <p/>
* All standard declarations have been moved to
* the StandardAbstractEntityComposite so we don't have to repeat
* them in all Composites.
*/
@Mixins( { HelloWorldBehaviourMixin.class, GenericPropertyMixin.class } )
public interface HelloWorldComposite
extends HelloWorldBehaviour, HelloWorldState, TransientComposite
{
}
Next step is Step 9 - Private and Abstract Mixins
Previous step was Step 8 - Generic Mixins.
Now we’re going to turn around and see how we can reduce the code needed to implement the HelloWorld example. We will also look at how to hide the Properties from the client code, since Properties are often considered to be implementation details that should not be exposed to clients.
The first thing we will do is remove the behaviour interface, and move the say() method to the TransientComposite type. This forces the mixin to implement the TransientComposite type, which would normally mean that it would have to implement all methods, including those found in the TransientComposite interface. However, since we are only really interested in implementing the say() method we will mark this by declaring that the Mixin "implements" the TransientComposite type, but is also "abstract". This, using pure Java semantics, makes it possible to avoid having to implement all methods. Qi4j will during the initialization phase detect that the Mixin only handles the say() method, and therefore only map it to that specific method. In order to instantiate the Mixin it will generate a subclass which implements the remaining methods in the TransientComposite type, as no-ops. These will never be called however, and is there purely for the purpose of being able to instantiate the Mixin. The Mixin is considered to be an Abstract Fragment.
To hide the state from the client we need to use what is called Private Mixins. A Private Mixin is any mixin that is referenced by another Mixin by using the @This injection, but which is not included in the TransientComposite type. As long as there is a Mixin implementation declared for the interface specified by the @This injection it will work, since Qi4j can know how to implement the interface. But since it is not extended by the TransientComposite type there is no way for a user of the TransientComposite to access it. That Mixin becomes an implementation detail. This can be used either for encapsulation purposes, or for referencing utility mixins that help the rest of the code implement some interface, but which itself should not be exposed.
Since the state is now hidden the initialization of the TransientComposite is a bit more tricky. Instead of just instantiating it you have to create a TransientBuilder first, then set the state using .prototypeFor(), and then call newInstance(). This ensures that the state can be set during construction, but not at any later point, other than through publicly exposed methods.
Steps for this tutorial:
- Move the say() method into the TransientComposite interface.
- Remove the behaviour interface.
- Remove the HelloWorldBehaviourMixin, create a HelloWorldMixin and let the HelloWorldMixin implement the TransientComposite directly.
- Mark the HelloWorldMixin as abstract and implement only the say() method.
- Remove the HelloWorldState from the TransientComposite "extends" declaration.
- Remove the GenericPropertyMixin. The Property methods will be implemented by the standard PropertyMixin declared in the TransientComposite interface instead.
If you have successfully completed the task, you should end up with the following artifacts only;
HelloWorldComposite.java
/**
* This Composite interface declares transitively
* all the Fragments of the HelloWorld composite.
* <p/>
* The Fragments are all abstract, so it's ok to
* put the domain methods here. Otherwise the Fragments
* would have to implement all methods, including those in Composite.
*/
@Mixins( { HelloWorldMixin.class } )
public interface HelloWorldComposite
extends TransientComposite
{
String say();
}
HelloWorldMixin.java
/**
* This is the implementation of the say() method. The mixin
* is abstract so it doesn't have to implement all methods
* from the Composite interface.
*/
public abstract class HelloWorldMixin
implements HelloWorldComposite
{
@This
HelloWorldState state;
@Override
public String say()
{
return state.phrase().get() + " " + state.name().get();
}
}
HelloWorldState.java
/**
* This interface contains only the state
* of the HelloWorld object.
*/
public interface HelloWorldState
{
@NotEmpty
Property<String> phrase();
@NotEmpty
Property<String> name();
}
| Tip | |
|---|---|
Theses tutorials are based on actual code found in the |
In this other set of tutorials it will be shown how to create and work with Service Composites, which are composites that extends from the ServiceComposite class. We will refactor one a very simple Library where you can borrow and return books to take advantage of the various features in Qi4j. These refactorings will benefit from automatic Service activation and Configuration Entities management.
Each tutorial step in this series starts with the result from the previous tutorial, so you can always look at the next tutorial step for guidance on what to do.
At the bottom of each tutorial step, the is Solutions section, which list the files you should have come to if you have followed the instructions.
If you want to reproduce what’s explained in this tutorial, remember to depend on the Core Runtime artifact that depends on Core API, Core SPI, Core Bootstrap and Core Functional & I/O APIs:
See the Depend on Qi4j in your build tutorial for details.
In this tutorial we start with basic Java classes, to simulate a very simple Library where you can borrow and return books.
Qi4j relies heavily on the use of interfaces. This makes it possible for an object to externally implement a number of interfaces which internally is backed by a number of Mixins, some of which you may have written yourself, and some of which may have been reused. This is also true for services, which we are to cover in this tutorial.
The first task is therefore to refactor the code so that the methods are implemented from an interface instead, and to essentially make the identical "application" into a Qi4j application. We also want the Book to be a ValueComposite.
Steps for this tutorial:
- Make the Book into a ValueComposite.
- Make the Library an interface with the same methods. We call this a MixinType.
- Create a LibraryMixin class, which implements the Library interface.
- Create a LibraryService that binds the LibraryMixin.
- The LibraryMixin will need to be injected with the ValueBuilderFactory in the @Structure scope.
Services can be "activated" and "passivated". Applications can be notified of this occurring by Qi4j runtime by assembling them with an Activator.
Activators methods are called around "activation" and "passivation": beforeActivation, afterActivation, beforeActivation, afterPassivation. The ActivatorAdapter class help you keeping your code short when you only need one or two hooks.
To showcase how this works, we refactor the code to create a number of copies of the books, to be lend out upon call to the borrowBook method, which will return null if no copy is available. The book copies are created in the activate method.
Steps to do:
- Add a createInitialData method to Library.
- In the implementation, create a couple of books of each title and store each copy in a HashMap<String,ArrayList<Book>>.
- Write an Activator<ServiceReference<Library>> class extending ActivatorAdapter.
- Override the afterActivation method, use the ServiceReference to get a handle on the Library and call its createInitialData method.
- Add the @Activators annotation to the LibraryService declaring the new LibraryActivator.
Services typically have configuration. Configurations are directly supported in Qi4j. A ConfigurationComposite is a subtype of EntityComposite. That is because configurations are stored in EntityStores, can be modified in runtime by client code and has the same semantics as regular entities.
Qi4j also handles the bootstrapping of configuration for the services. If the ConfigurationComposite is not found in the configured entity store, then Qi4j will automatically locate a properties file for each service instance, read those properties into a ConfigurationComposite instance, save that to the entity store and provide the values to the service. The properties file must be with the same name as the service instance with the extension "properties" in the same package as the service.
For this exercise, create a LibraryConfiguration that contains "titles", "authors" and "copies". The first two are a string with a comma separated list, and the "copies" is just an Integer with how many copies are made of each title.
Steps to do.
- Create a LibraryConfiguration interface that extends ConfigurationComposite, and has three Property instances named "titles", "authors" and "copies", where the first two are of String type and the last is of Integer type.
- Delete the LibraryActivator and remove the @Activators annotation from the LibraryService and the corresponding createInitialData method.
- In the LibraryMixin remove the member injection of the ValueBuilderFactory, and instead inject the ValueBuilderFactory in the constructor.
- Inject the LibraryConfiguration via the constructor. The injection scope is @This.
- Create a resource called LibraryService.properties and place it in the directory org/qi4j/tutorials/services/step4 in the classpath (for instance, src/main/resources ). Put something like this in: titles=Domain Driven Design, Pragmatic Programmer, Extreme Programming Explained authors=Eric Evans, Andy Hunt, Kent Beck #Number of copies of each book. copies=3
- Load initial data from the LibraryConfiguration in the LibraryMixin constructor.
Contextual fragments are fragments that are added to the composites during assembly time. That means that they are not present in the composite declarations, but a start-up decision what should be added. Once the application instance is created, it is no longer possible to modify which fragments are attached.
Typical use-case is tracing and debugging. Other potential uses are additional security or context interfaces needing access to internal mixins not originally intended for, such as GUI frameworks doing reflection on certain composites. We strongly recommend against using this feature, as it is not needed as commonly as you may think.
| Note | |
|---|---|
Constraints are not supported to be contextual at the moment. |
If you want to reproduce what’s explained in this tutorial, remember to depend on the Core Bootstrap artifact:
At runtime you will need the Core Runtime artifact too. See the Depend on Qi4j in your build tutorial for details.
The mixins, sideeffects and concerns are added during the bootstrap phase. It is very straight-forward;
public class TraceAll
{
public void assemble( ModuleAssembly module )
throws AssemblyException
{
ServiceDeclaration decl = module.addServices( PinSearchService.class );
if( Boolean.getBoolean( "trace.all" ) )
{
decl.withConcerns( TraceAllConcern.class );
}
}
}
In the example above, we add the TraceAllConcern from the Logging Library if the system property "trace.all" is true. If the system property is not set to true, there will be no TraceAllConcern on the PinSearchService.
Concerns that are added in this way will be at the top of the method invocation stack, i.e. will be the first one to be called and last one to be completed.
SideEffects that are added in this way will be the last one’s to be executed.
Qi4j does not follow the JavaBeans standard for property support. Instead, a much more explicit concept is in place. The advantages are enormous, and the only real downside is that people are already destroyed, thinking in so called POJO terms.
If you want to reproduce what’s explained in this tutorial, remember to depend on the Core API artifact:
At runtime you will need the Core Runtime artifact too. See the Depend on Qi4j in your build tutorial for details.
So in Qi4j, instead of writing;
public interface Book
{
String getTitle();
String getAuthor();
}
public interface MutableBook extends Book
{
void setTitle( String title );
void setAuthor( String author );
}
where we need the MutableBook to be able to initialize it (known as Type 2 Dependency Injection) on creation. From our point of view, this has many flaws. If we refactor the "Title" property, our IDE need to understand the getters and setters concept. The good news now is that they all do, but how about meta information about the property itself. For instance, how to define a system where a UI can get an Icon for "Author" in a generic way? All kinds of system has been added, such as one can create a BookBean for some metadata, and then MBeans for management. Where will it end?
We think we have a much better solution, and are bold enough to abandon the getters/setters and POJOs. The above looks like this;
public interface Book
{
@Immutable
Property<String> title();
@Immutable
Property<String> author();
}
There is more to this than meets the eye.
- @Immutable annotation signals that this can’t change.
- Property still have a set() method, which can be used during the initialization only.
- Metadata about each Property can be declared as MetaInfo.
@Structure
Module module;
[...snip...]
TransientBuilder<Book> builder = module.newTransientBuilder( Book.class );
Book prototype = builder.prototype();
prototype.title().set( "The Death of POJOs" );
prototype.author().set( "Niclas Hedhman" );
Book book = builder.newInstance();
String title = book.title().get(); // Retrieves the title.
book.title().set( "Long Live POJOs" ); // throws an IllegalStateException
The Property concept also allows a much better defined persistence model. In Qi4j, only Property and Association instances are persisted, and that makes the semantics around the persistence system very clear.
Properties reference values only, and these values must be Serializable, which means that Properties can not contain Entities, since Entities are not Serializable. Associations are the opposite, as they must only reference Entities and nothing else.
Properties can also have typed, custom meta information associated with them. Meta information is declared once per Property per Module. A Property is identified by its method name and the interface it is declared in.
Let’s say we want to create a generic Swing client that can show and navigate the domain model, without knowing the actual domain model. Such Swing client will utilize a SwingInfo property info if it is available.
public interface SwingInfo
{
Icon icon( Rectangle size );
String displayName( Locale locale );
}
Our generic Swing UI will be mainly reflective in nature, but when it gets hold of a Property, it can simply do;
@Structure
private Qi4j api;
[...snip...]
private void addProperty( JPanel panel, Property<?> property )
{
SwingInfo info = api.propertyDescriptorFor( property ).metaInfo( SwingInfo.class );
Icon icon = info.icon( SIZE_32_32 );
panel.add( new JLabel(info.displayName( this.locale ), icon, JLabel.CENTER) );
}
[...snip...]
}
Constraints are defined in Constraint.
If you want to reproduce what’s explained in this tutorial, remember to depend on the Core Bootstrap artifact:
At runtime you will need the Core Runtime artifact too. See the Depend on Qi4j in your build tutorial for details.
Method Constraints are declared with annotations on the method argument. The annotation itself is custom, and it is possible to make your own.
public interface Dialer
{
void callPhoneNumber(@PhoneNumber String phoneNo);
}
In the code above we say that we want the argument to the callPhoneNumber() method to be a valid phone number. This annotation is not built-in, so we need to declare it.
@ConstraintDeclaration
@Retention( RetentionPolicy.RUNTIME )
@Target( { ElementType.PARAMETER, ElementType.ANNOTATION_TYPE, ElementType.METHOD } )
public @interface PhoneNumber
{
}
We then need to provide the Constraint implementation.
public class PhoneNumberConstraint
implements Constraint<PhoneNumber, String>
{
public boolean isValid( PhoneNumber annotation, String number )
{
boolean validPhoneNumber = true; // check phone number format...
return validPhoneNumber; // return true if valid phone number.
}
}
We also need to include the Constraint on the Composites we want to have them present.
@Constraints( PhoneNumberConstraint.class )
public interface DialerComposite extends ServiceComposite, Dialer
{
}
If a Constraint is violated, then a ConstraintViolationException is thrown. The Exception contains ALL violations found in the method invocation. Concerns can be used to catch and report these violations.
public class ParameterViolationConcern extends ConcernOf<InvocationHandler>
implements InvocationHandler
{
public Object invoke( Object proxy, Method method, Object[] args )
throws Throwable
{
try
{
return next.invoke( proxy, method, args );
}
catch( ConstraintViolationException e )
{
for( ConstraintViolation violation : e.constraintViolations() )
{
String name = violation.name();
Object value = violation.value();
Annotation constraint = violation.constraint();
report( name, value, constraint );
}
throw new IllegalArgumentException("Invalid argument(s)", e);
}
}
[...snip...]
private void report( String name, Object value, Annotation constraint )
{
}
}
Property Constraints are declared on the Property method.
public interface HasPhoneNumber
{
@PhoneNumber
Property<String> phoneNumber();
}
In this case, the Constraint associated with the phoneNumber() method, will be called before the set() method on that Property is called. If there is a constraint violation, the Exception thrown will be part of the caller, and not the composite containing the Property, so a reporting constraint on the containing Composite will not see it. If you want the containing Composite to handle the Constraint Violation, then you need to add a Concern on the Property itself, which can be done like this;
public abstract class PhoneNumberParameterViolationConcern extends ConcernOf<HasPhoneNumber>
implements HasPhoneNumber
{
@Concerns( CheckViolation.class )
public abstract Property<String> phoneNumber();
private abstract class CheckViolation extends ConcernOf<Property<String>>
implements Property<String>
{
public void set( String number )
{
try
{
next.set( number );
}
catch( ConstraintViolationException e )
{
Collection<ConstraintViolation> violations = e.constraintViolations();
report( violations );
}
}
[...snip...]
private void report( Collection<ConstraintViolation> violations )
{
}
}
}
Concerns are defined in Concern.
If you want to reproduce what’s explained in this tutorial, remember to depend on the Core Bootstrap artifact:
At runtime you will need the Core Runtime artifact too. See the Depend on Qi4j in your build tutorial for details.
A typed Concern is a Java class that implements the MixinType it can be used on:
public class InventoryConcern extends ConcernOf<Order>
implements Order
{
@Service
private InventoryService inventory;
@Override
public void addLineItem( LineItem item )
{
String productCode = item.productCode().get();
int quantity = item.quantity().get();
inventory.remove( productCode, quantity );
next.addLineItem( item );
}
@Override
public void removeLineItem( LineItem item )
{
String productCode = item.productCode().get();
int quantity = item.quantity().get();
inventory.add( productCode, quantity );
next.removeLineItem( item );
}
}
The InventoryConcern is implemented as an abstract class, since we are not interested in the many other methods in the Order interface. Extending the ConcernOf is a convenience mechanism, instead of an explicit @ConcernFor annotation on a private field, which can be used in rare occasions when you are not able to extend. This base class defines the next field, which is set up by the Qi4j runtime and points to the next fragment in the call stack. We can also see that the InventoryService is provided to the concern, which is done with dependency injection. Qi4j also supports dependency injection via constructors and methods.
It can be used as follows;
@Concerns( InventoryConcern.class )
public interface Order
{
void addLineItem( LineItem item );
void removeLineItem( LineItem item );
[...snip...]
Methods of the Concern Fragment will be called before the Mixin invocation.
A generic Concern is a Java class that implements java.lang.reflect.InvocationHandler which allows it to be used on any arbitrary MixinType.
public class MyGenericConcern extends GenericConcern
{
@Override
public Object invoke( Object proxy, Method method, Object[] args )
throws Throwable
{
// Do whatever you want
[...snip...]
It can be used as follows;
@Concerns( MyGenericConcern.class )
public interface AnyMixinType
{
[...snip...]
@MyAnnotation
void doSomething();
void doSomethingElse();
Methods of the Concern Fragment will be called before the Mixin invocation.
For generic Concerns that should only trigger on methods with specific annotations or fulfilling some expression, add @AppliesTo annotation to the Concern class which points to either triggering annotation(s), or to AppliesToFilter implementation(s).
The Concern is invoked if one of the triggering annotations is found or one of the AppliesToFilter accepts the invocation. In other words the AppliesTo arguments are OR’ed.
Here is how the declaration goes ;
@AppliesTo( { MyAnnotation.class, MyAppliesToFilter.class } )
public class MyGenericConcern extends GenericConcern
{
And how to use the annotation ;
@Concerns( MyGenericConcern.class )
public interface AnyMixinType
{
@MyAnnotation
void doSomething();
void doSomethingElse();
}
Here only the doSomething() method will see the Concern applied whereas the doSomethingElse() method won’t.
Finally here is how to implement an AppliesToFilter:
public class MyAppliesToFilter implements AppliesToFilter
{
public boolean appliesTo( Method method, Class<?> mixin, Class<?> compositeType, Class<?> modifierClass )
{
boolean appliesTo = evaluate(method); // Do whatever you want
return appliesTo;
}
[...snip...]
private boolean evaluate( Method method )
{
return true;
}
SideEffects are defined in SideEffect.
If you want to reproduce what’s explained in this tutorial, remember to depend on the Core Bootstrap artifact:
At runtime you will need the Core Runtime artifact too. See the Depend on Qi4j in your build tutorial for details.
A typed SideEffect is a Java class that implements the MixinType it can be used on:
public abstract class MailNotifySideEffect extends SideEffectOf<Confirmable>
implements Confirmable
{
@Service
private MailService mailer;
@This
private HasLineItems hasItems;
@This
private HasCustomer hasCustomer;
@Override
public void confirm()
{
StringBuilder builder = new StringBuilder();
builder.append( "An Order has been made.\n\n\n" );
builder.append( "Customer:" );
builder.append( hasCustomer.name().get() );
builder.append( "\n\nItems ordered:\n" );
for( LineItem item : hasItems.lineItems().get() )
{
builder.append( item.name().get() );
builder.append( " : " );
builder.append( item.quantity().get() );
builder.append( "\n" );
}
mailer.send( "sales@mycompany.com", builder.toString() );
}
}
The MailNotifySideEffect is implemented as an abstract class, since we are not interested in the many other methods in the Confirmable interface. Extending the SideEffectOf is a convenience mechanism, instead of an explicit @SideEffectFor annotation on a private field, which can be used in rare occasions when you are not able to extend. This base class defines the next field, which is set up by the Qi4j runtime and points to the next fragment in the call stack. We can also see that the MailService, HasLineItems and HasCustomer are provided to the side-effect, which is done with dependency injection. Qi4j also supports dependency injection via constructors and methods.
It can be used as follows;
@SideEffects( MailNotifySideEffect.class )
public interface OrderEntity
extends Order, HasSequenceNumber, HasCustomer,
HasLineItems, Confirmable, EntityComposite
{
}
Methods of the SideEffect Fragment will be called after the Mixin invocation.
A generic SideEffect is a Java class that implements java.lang.reflect.InvocationHandler which allows it to be used on any arbitrary MixinType.
public class MyGenericSideEffect extends GenericSideEffect
{
@Override
public Object invoke( Object proxy, Method method, Object[] args )
throws Throwable
{
// Do whatever you need...
try
{
// It is possible to obtain the returned values by using 'result' member;
Object returnedValue = result.invoke( proxy, method, args );
} catch( NumberFormatException e )
{
// And Exception will be thrown accordingly, in case you need to know.
throw new IllegalArgumentException(); // But any thrown exceptions are ignored.
}
return 23; // Return values will also be ignored.
}
}
It can be used as follows;
@Concerns( MyGenericSideEffect.class )
public interface AnyMixinType
{
[...snip...]
}
Methods of the SideEffect Fragment will be called before the Mixin invocation.
For generic SideEffects that should only trigger on methods with specific annotations or fulfilling some expression, add @AppliesTo annotation to the SideEffect class which points to either triggering annotation(s), or to AppliesToFilter implementation(s).
The SideEffect is invoked if one of the triggering annotations is found or one of the AppliesToFilter accepts the invocation. In other words the AppliesTo arguments are OR’ed.
Here is how the declaration goes ;
@AppliesTo( { MyAnnotation.class, MyAppliesToFilter.class } )
public class MyGenericSideEffect extends GenericSideEffect
{
[...snip...]
}
And how to use the annotation ;
@Concerns( MyGenericSideEffect.class )
public interface AnyMixinType
{
@MyAnnotation
void doSomething();
void doSomethingElse();
}
[...snip...]
Here only the doSomething() method will see the SideEffect applied whereas the doSomethingElse() method won’t.
Finally here is how to implement an AppliesToFilter:
public class MyAppliesToFilter implements AppliesToFilter
{
public boolean appliesTo( Method method, Class<?> mixin, Class<?> compositeType, Class<?> modifierClass )
{
boolean appliesTo = evaluate(method); // Do whatever you want
return appliesTo;
}
[...snip...]
private boolean evaluate( Method method )
{
return true;
}
One of the most common tasks in Qi4j is the management of the life cycle of Entities. Since Qi4j is capable of delivering much higher performance than traditional Object-Relational Mapping technologies, we also expect that people use Entities more frequently in Qi4j applications, so it is a very important topic to cover.
If you want to reproduce what’s explained in this tutorial, remember to depend on the Core Bootstrap artifact:
Moreover, you’ll need an EntityStore for persistence and an Indexing engine for querying. Choose among the available implementations listed in the Extensions section.
At runtime you will need the Core Runtime artifact too. See the Depend on Qi4j in your build tutorial for details.
All Entity operations MUST be done within a UnitOfWork. UnitOfWorks can be nested and if underlying UnitOfWorks are not completed (method complete()), then none of the operations will be persisted permanently.
Entity composites are subtypes of the EntityComposite interface.
Domain code typically don’t need to know of the EntityComposite types directly, and is instead using the domain specific interface. The Visibility rules will be applied to associate the right EntityComposite when a domain type is requested. Ambiguities are not accepted and will result in runtime exceptions.
Qi4j supports that each entity instance can have more than one entity type, and it is managed per instance. This feature is beyond the scope of this HowTO and will be covered subsequently.
We have made the observation that it is good practice to separate the internal state from the observable behavior. By this we mean that it is not a good practice to allow client code to manipulate or even view the internal states of objects, which is such a common (bad) practice in the so called POJO world.
Instead, we recommend that the programmer defines the client requirement of what each participant within the client context needs to conform to, and then create composites accordingly and hide all the state internal to the composite in private mixins. By doing so, the same entity can participate in multiple contexts with different behavioral requirements but using the same internal state.
We recommend limited use of primitive types for Properties and instead subtype the Property.
And try to use ValueComposites instead of Entities.
We need an entity to illustrate how we recommend to separate internal state from public behavior and observable state. We will for the sake of simplicity use a trivial example. Please refer to other (possibly future) HowTos on patterns on Entity management.
public interface Car
{
@Immutable
Association<Manufacturer> manufacturer();
@Immutable
Property<String> model();
ManyAssociation<Accident> accidents();
}
public interface Manufacturer
{
Property<String> name();
Property<String> country();
@UseDefaults
Property<Long> carsProduced();
}
public interface Accident
{
Property<String> description();
Property<Date> occured();
Property<Date> repaired();
}
Above we define a Car domain object, which is of a particular Manufacturer (also an Entity), a model and a record of Accidents.
We will also need to define the composites for the above domain structure;
public interface CarEntity extends Car, EntityComposite
{}
public interface ManufacturerEntity extends Manufacturer, EntityComposite
{}
public interface AccidentValue extends Accident, ValueComposite
{}
For this case, we define both the Car and the Manufacturer as Entities, whereas the Accident is a Value, since it is an immutable event that can not be modified.
All of the above must also be declared in the assembly. We MUST associate the EntityComposites with a relevant Module. We must also assemble an EntityStore for the entire application, but that is outside the scope of this HowTo.
public class MyAssembler
implements Assembler
{
public void assemble( ModuleAssembly module )
{
module.entities( CarEntity.class,
ManufacturerEntity.class );
module.values( AccidentValue.class );
[...snip...]
}
}
We have no other Composites involved yet, so we can proceed to look at the usage code.
We recommend that the life cycle management of entities is placed inside domain factories, one for each type and made available as services.
The entity factory is something you need to write yourself, but as with most things in Qi4j it will end up being a fairly small implementation. So how is that done?
public interface CarEntityFactory
{
Car create(Manufacturer manufacturer, String model);
}
That is just the domain interface. We now need to make the service interface, which Qi4j needs to identify services and make it possible for the service injection later.
@Mixins( { CarEntityFactoryMixin.class } )
public interface CarEntityFactoryService
extends CarEntityFactory, ServiceComposite
{}
Then we need an implementation of the mixin.
public class CarEntityFactoryMixin
implements CarEntityFactory
{
And doing that, first of all we need to request Qi4j runtime to give us the UnitOfWorkFactory associated with the Module that our code belongs to, and the UnitOfWork current context the execution is happening in.
Injections that are related to the Visibility rules are handled by the @Structure annotation. And the easiest way for us to obtain a UnitOfWorkFactory is simply to;
public class CarEntityFactoryMixin
implements CarEntityFactory
{
@Structure
UnitOfWorkFactory uowf;
Here Qi4j will inject the member uowf with the correct UnitOfWorkFactory. In case we only need the UnitOfWorkFactory during the construction, we can also request it in the same manner as constructor argument.
public CarEntityFactoryMixin( @Structure UnitOfWorkFactory uowf )
{
}
This is important to know, since the injected member will not be available until AFTER the constructor has been completed.
We then need to provide the implementation for the create() method.
public Car create(Manufacturer manufacturer, String model)
{
UnitOfWork uow = uowf.currentUnitOfWork();
EntityBuilder<Car> builder = uow.newEntityBuilder( Car.class );
Car prototype = builder.instance();
prototype.manufacturer().set( manufacturer );
prototype.model().set( model );
return builder.newInstance();
}
So far so good. But how about the Manufacturer input into the create() method?
DDD promotes the use of Repositories. They are the type-safe domain interfaces into locating entities without getting bogged down with querying infrastructure details. And one Repository per Entity type, so we keep it nice, tidy and re-usable. So let’s create one for the Manufacturer type.
public interface ManufacturerRepository
{
Manufacturer findByIdentity(String identity);
Manufacturer findByName(String name);
}
And then we repeat the process for creating a Service…
@Mixins( ManufacturerRepositoryMixin.class )
public interface ManufacturerRepositoryService
extends ManufacturerRepository, ServiceComposite
{}
and a Mixin that implements it…
public class ManufacturerRepositoryMixin
implements ManufacturerRepository
{
@Structure
private UnitOfWorkFactory uowf;
@Structure
private Module module;
public Manufacturer findByIdentity( String identity )
{
UnitOfWork uow = uowf.currentUnitOfWork();
return uow.get(Manufacturer.class, identity);
}
public Manufacturer findByName( String name )
{
UnitOfWork uow = uowf.currentUnitOfWork();
QueryBuilder<Manufacturer> builder =
module.newQueryBuilder( Manufacturer.class );
Manufacturer template = templateFor( Manufacturer.class );
builder.where( eq( template.name(), name ) );
Query<Manufacturer> query = uow.newQuery( builder);
return query.find();
}
}
But now we have introduced 2 services that also are required to be declared in the assembly. In this case, we want the Services to be available to the application layer above, and not restricted to within this domain model.
public class MyAssembler
implements Assembler
{
public void assemble( ModuleAssembly module )
{
module.entities( CarEntity.class,
ManufacturerEntity.class );
module.values( AccidentValue.class );
module.addServices(
ManufacturerRepositoryService.class,
CarEntityFactoryService.class
).visibleIn( Visibility.application );
}
}
If you notice, there is a couple of calls to UnitOfWorkFactory.currentUnitOfWork(), but what is current UnitOfWork, and who is setting that up?
Well, the domain layer should not worry about UoW, it is probably the responsibility of the application/service layer sitting on top. That could be a web application creating and completing a UoW per request, or some other co-ordinator doing long-running UnitOfWorks.
There are of course a lot more details to get all this completed, but that is beyond the scope of this HowTo.
Qi4j supports a Configuration system for services. The configuration instance itself is an Entity and is therefor readable, writeable and queryable, just like other Entities. This should make Configuration management much simpler, since you can easily build GUI tools to allow editing of these in runtime. However, to simplify the initial values of the Configuration instance, Qi4j also does the initial bootstrapping of the Configuration entity for you. This HowTo is going to show how.
If you want to reproduce what’s explained in this tutorial, remember to depend on the Core Bootstrap artifact:
At runtime you will need the Core Runtime artifact too. See the Depend on Qi4j in your build tutorial for details.
To illustrate these features we create an TravelPlan service, which allows clients to find and make Reservations to Destinations. For the sake of simplicity, we are leaving out the domain details…
public interface TravelPlan
{
// Domain methods, which are beyond the discussion at hand.
}
So, then there is the ServiceComposite…
// The package is relevant to the Initial Values discussed later.
package org.qi4j.manual.travel;
[...snip...]
@Mixins( { TravelPlanMixin.class } )
public interface TravelPlanService extends TravelPlan, ServiceComposite
{}
And then in the Mixin we actually need to connect to a foreign system to obtain the various details that the service can provide to the clients. For instance, it needs a host name and port and a protocol to use. We put these into a configuration interface.
public interface TravelPlanConfiguration
{
Property<String> hostName();
@Range( min=0, max=65535 )
Property<Integer> portNumber();
@Matches( "(ssh|rlogin|telnet)" )
Property<String> protocol();
}
We used the recommended type-safe Property subtype pattern, and for each PortNumber and Protocol we have defined a Constraint required.
Now we can access this configuration in the TravelPlanMixin like this;
import org.qi4j.api.configuration.Configuration;
public class TravelPlanMixin implements TravelPlan
{
@This
Configuration<TravelPlanConfiguration> config;
private void foo()
{
TravelPlanConfiguration tpConf = config.get();
String hostName = tpConf.hostName().get();
// ...
}
[...snip...]
}
And from the Service point of view, it doesn’t need to worry about where the configuration really comes from. But it may want to control when the Configuration should be refreshed, to ensure that atomic changes are happening. This is done with the refresh() method in the Configuration interface;
public void doSomething()
{
// Refresh Configuration before reading it.
config.refresh();
TravelPlanConfiguration tpConf = config.get();
// ...
}
This ensures that any updates to the Configuration that has occurred will be retrieved and available to the Service. Since Configuration instance is an Entity, the UnitOfWork system will ensure that the Configuration is consistent and not in the middle of value changes.
The initial Configuration instance will be created automatically behind the scenes, by reading a properties file and create an Entity with the same identity as the identity of the service. That was a handful. Services are, as we know, singletons and have an identity specified at assembly. Even if it is not provided, one will automatically be assigned. The service’s "identifiedBy" will be used as the identifier for the Configuration entity and stored in the visible EntityStore. This identity is also used to locate a properties file in the same package as the ServiceComposite belongs to.
So, we create a properties file, where the keys are the names of the properties in TravelPlanConfiguration.
# Hostname to the TravelPlan service hostName=niclas.hedhman.org # Port number to use for the connection portNumber=5439 # Protocol to use; Valid options "ssh", "rlogin", "telnet" protocol=ssh
File: org/hedhman/niclas/travel/TravelPlanService.properties
Note that the file resides in the directory equivalent to the package name of the TravelPlanService.
And this would work with the standard assembly.
public void assemble(ModuleAssembly module) throws AssemblyException
{
module.addServices(TravelPlanService.class).instantiateOnStartup();
}
If you need to use multiple instances of the same service, or that the service has a non-default Identity, then you need to name the properties file according to the Identity of the service declaration, but the file will still need to be in the same package as the ServiceComposite sub type, the TravelPlanService in the above example. For instance;
public void assemble(ModuleAssembly module) throws AssemblyException
{
module.addServices(TravelPlanService.class)
.instantiateOnStartup()
.identifiedBy("ExpediaService");
module.addServices(TravelPlanService.class)
.instantiateOnStartup()
.identifiedBy("OrbitzService");
}
And the two files for configuration,
# Hostname to the TravelPlan service hostName=expedia.hedhman.org # Port number to use for the connection portNumber=9251 # Protocol to use; Valid options "ssh", "rlogin", "telnet" protocol=ssh
File: org/qi4j/manual/travel/ExpediaService.properties
# Hostname to the TravelPlan service hostName=orbitz.hedhman.org # Port number to use for the connection portNumber=7412 # Protocol to use; Valid options "ssh", "rlogin", "telnet" protocol=rlogin
File: org/qi4j/manual/travel/OrbitzService.properties
Unlike most frameworks, the Configuration in Qi4j is an active Entity, and once the properties file has been read once at the first(!) startup, it no longer serves any purpose. The Configuration will always be retrieved from the EntityStore. Changes to the properties file are not taken into consideration if the Configuration entity is found in the entity store.
But that also means that applications should not cache the configuration values, and instead read them from the Configuration instance every time needed, and do a refresh() method call when it is safe to update the Configuration Entity with new values.
| Note | |
|---|---|
This article was written on Rickard Öberg’s blog, 6 Nov 2010 |
The past week I’ve had to deal with a lot of data shuffling, both in raw form as bytes and strings, and as SPI and domain level objects. What struck me is that it is notoriously hard to shuffle things from one place to another in a way that is scalable, performant and handles errors correctly. And I had to do some things over and over again, like reading strings from files.
So the thought occurred: there must be a general pattern to how this thing works, which can be extracted and put into a library. "Reading lines from a text file" should only have to be done once, and then used in whatever scenario requires it. Let’s take a look at a typical example of reading from one file and writing to another to see if we can find out what the possible pieces could be:
1: File source = new File( getClass().getResource( "/iotest.txt" ).getFile() );
1: File destination = File.createTempFile( "test", ".txt" );
1: destination.deleteOnExit();
2: BufferedReader reader = new BufferedReader(new FileReader(source));
3: long count = 0;
2: try
2: {
4: BufferedWriter writer = new BufferedWriter(new FileWriter(destination));
4: try
4: {
2: String line = null;
2: while ((line = reader.readLine()) != null)
2: {
3: count++;
4: writer.append( line ).append( '\n' );
2: }
4: writer.close();
4: } catch (IOException e)
4: {
4: writer.close();
4: destination.delete();
4: }
2: } finally
2: {
2: reader.close();
2: }
1: System.out.println(count)As the numbers to the left indicates, I’ve identified four parts in this type of code that could be separated from each other.
1) is the client code that initiates a transfer, and which have to know the input and output source.
2) is the code that reads lines from an input.
3) is helper code that I use to keep track of what’s going on, and which I’d like to reuse no matter what kind of transfer is being done.
4) receives the data and writes it down. In this code, if I wanted to implement batching on the read and write side I could do so by changing the 2 and 4 parts to read/write multiple lines at a time.
If you want to reproduce what’s explained in this tutorial, remember to depend on the Core Runtime artifact that depends on Core API, Core SPI, Core Bootstrap and Core Functional & I/O APIs:
See the Depend on Qi4j in your build tutorial for details.
Once theses parts were identified it was mostly just a matter of putting interfaces on these pieces, and making sure they can be easily used in many different situations. The result is as follows.
To start with we have Input:
public interface Input<T, SenderThrowableType extends Throwable>
{
<ReceiverThrowableType extends Throwable> void transferTo( Output<? super T, ReceiverThrowableType> output )
throws SenderThrowableType, ReceiverThrowableType;
}
Inputs, like Iterables, can be used over and over again to initiate transfers of data from one place to another, in this case an Output. Since I want this to be generic the type of things that is sent is T, so can be anything (byte[], String, EntityState, MyDomainObject). I also want the sender and receiver of data to be able to throw their own exceptions, and this is marked by declaring these as generic exception types. For example, the input may want to throw SQLException and the output IOException, if anything goes wrong. This should be strongly typed, and both sender and receiver must know when either side screws up, so that they can recover properly and close any resources they have opened.
On the receiving side we then have Output:
public interface Output<T, ReceiverThrowableType extends Throwable>
{
[...snip...]
<SenderThrowableType extends Throwable> void receiveFrom( Sender<? extends T, SenderThrowableType> sender )
throws ReceiverThrowableType, SenderThrowableType;
}
When receiveFrom is invoked by an Input, as a result of invoking transferTo on the Input, the Output should open whatever resources it needs to write to, and then expect data to come from a Sender. Both the Input and Output must have the same type T, so that they agree on what is being sent. We will see later how this can be handled if this is not the case.
Next we have Sender:
public interface Sender<T, SenderThrowableType extends Throwable>
{
[...snip...]
<ReceiverThrowableType extends Throwable> void sendTo( Receiver<? super T, ReceiverThrowableType> receiver )
throws ReceiverThrowableType, SenderThrowableType;
}
The Output invokes sendTo and passes in a Receiver that the Sender will use to send individual items. The sender at this point can start transferring data of type T to the receiver, one at a time. The Receiver looks like this:
public interface Receiver<T, ReceiverThrowableType extends Throwable>
{
[...snip...]
void receive( T item )
throws ReceiverThrowableType;
}
When the receiver gets the individual items from the sender it can either immediately write them to its underlying resource, or batch them up. Since the receiver will know when the transfer is done (sendTo returns) it can write the remaining batches properly and close any resource it holds.
This simple pattern, with two interfaces on the sending side and two on the receiving side, gives us the potential to do scalable, performant and fault-tolerant transfers of data.
So now that the above API defines the contract of sending and receiving data, I can then create a couple of standard inputs and outputs. Let’s say, reading lines of text from a file, and writing lines of text to a file. These implementations I can then put in static methods so they are easy to use. In the end, to make a copy of a text file looks like this:
File source = new File("source.txt");
File destination = new File("destination.txt");
Inputs.text( source ).transferTo( Outputs.text( destination ) );
One line of code that handles the reading, the writing, the cleaning up, buffering, and whatnot. Pretty nifty! The transferTo method will throw IOException, which I can catch if I want to present any errors to the user. But actually dealing with those errors, i.e. closing the files and potentially deleting the destination if the transfer failed, is already handled by the Input and Output. I will never have to deal with the details of reading text from a file ever again!
While the above handles the basic input/output of a transfer, there are usually other things that I want to do as well. I may want to count how many items were transferred, do some filtering, or log every 1000 items or so to see what’s going on. Since input and output are now separated this becomes simply a matter of inserting something in the middle that mediates the input and output. Since many of these mediations have a similar character I can put these into standard utility methods to make them easier to use.
The first standard decorator is a filter. I will implement this by means of supplying a Specification:
public static <T,ReceiverThrowableType extends Throwable> Output<T, ReceiverThrowableType> filter( final Specification<T> specification, final Output<T, ReceiverThrowableType> output)
{
... create an Output that filters items based on the Specification<T> ...
}Where Specification is:
interface Specification<T>
{
boolean test(T item);
}With this simple construct I can now perform transfers and easily filter out items I don’t want on the receiving side. This example removes empty lines from a text file.
File source = ...
File destination = ...
Inputs.text( source ).transferTo( Transforms.filter(new Specification<String>()
{
public boolean test(String string)
{
return string.length() != 0;
}
}, Outputs.text(destination) );The second common operation is mapping from one type to the other. This deals with the case that one Input you have may not match the Output you want to send to, but there’s a way to map from the input type to the output type. An example would be to map from String to JSONObject, for example. The operation itself looks like this:
public static <From,To,ReceiverThrowableType extends Throwable> Output<From, ReceiverThrowableType> map( Function<From,To> function, Output<To, ReceiverThrowableType> output)
Where Function is defined as:
interface Function<From, To>
{
To map(From from);
}With this I can then connect an Input of Strings to an Output of JSONObject like so:
Input<String,IOException> input = ...; Output<JSONObject,RuntimeException> output = ...; input.transferTo(Transforms.map(new String2JSON(), output);
Where String2JSON implements Function and it’s map method converts the String into a JSONObject.
At this point we can now deal with the last part of the initial example, the counting of items. This can be implemented as a generic Map that has the same input and output type, and just maintains a count internally that updates on every call to map(). The example can then be written as:
File source = ...
File destination = ...
Counter<String> counter = new Counter<String>();
Inputs.text( source ).transferTo( Transforms.map(counter, Outputs.text(destination) ));
System.out.println("Nr of lines:"+counter.getCount())Now I can finally get back to my initial problem that led me to look into this: how to implement a good way to access EntityStates in a Qi4j EntityStore, and perform restores of backups. The current version of accessing EntityStates look like this:
<ThrowableType extends Throwable> void visitEntityStates( EntityStateVisitor<ThrowableType> visitor, ModuleSPI module )
throws ThrowableType;
interface EntityStateVisitor<ThrowableType extends Throwable>
{
void visitEntityState( EntityState entityState )
throws ThrowableType;
}This can now be replaced with:
Input<EntityState, EntityStoreException> entityStates(ModuleSPI module);
Because of the pattern outlined above, users of this will get more information about what’s happening in the traversal, such as if the EntityStore raised an EntityStoreException during the traversal, which they can then handle gracefully. It also becomes easy to add decorators such as maps and filters to users of this. Let’s say you only are interested in EntityState’s of a given type. Then add a filter for this, without changing the consumer.
For importing backup data into an EntityStore, the interface used to look like this:
interface ImportSupport
{
ImportResult importFrom( Reader in )
throws IOException;
}This ties the EntityStore to only being able to read JSON lines from Reader’s, the client will not know if the IOException raised is due to errors in the Reader or writing in the store, and the ImportResult, which contains a list of exceptions and count of stuff, is quite ugly to create and use. With the I/O API at hand this can now be replaced with:
interface ImportSupport
{
Output<String,EntityStoreException> importJSON();
}To use this, given the helpers outlined above, is as simple as:
File backup = ... ImportSupport entityStore = ... Inputs.text(backup).transferTo(entityStore.importJSON());
If the client wants any "extras", such as counting how many objects were imported, this can be done by adding filters as previously shown. If you only want to, say, import entities modified before a particular date (let’s say you know some junk was introduced after a given time), then add a specification filter that performs this check. And so on.
It is quite common while developing software that you have to shuffle data or objects from one input to another output, possible with some transformations in the middle. Usually these things have to be done from scratch, which opens up for errors and badly applied patterns. By introducing a generic Input/Output API that encapsulates and separates these things properly it becomes easier to perform these tasks in a scalable, performant and error-free way, and while still allowing these tasks to be decorated with extra features when needed.
This article has outlined one way to do this, and the API and helpers that I’ve described are available in the current Qi4j Core 1.3-SNAPSHOT in Git (see Qi4j homepage for access details). The idea is to start using it throughout Qi4j wherever we need to do I/O of the type described here.
Qi4j community migrated away from Maven after several years of frustration, especially around release management, versioning and cross-module dependency resolution issues, in Feb 2011. The tool of choice is now Gradle, and it doesn’t require any installation, there are gradlew and gradlew.bat in the root folder of the Qi4j SDK that will bootstrap Gradle if not done so already.
By default, the build system produces a "zero build". It means that there is no version assigned to the build, and a "0" is used in the produced artifacts. This is due to our disagreement (with Maven community) that the "next" version name/number is known prior to the release. This is in our opinion a delayed decision. To build a particular version, you specify a "version" property on the command-line, like
./gradlew -Dversion=2.0-FLAVOUR install
If a "version" property is not defined, the build system will refuse to make a release and upload.
Gradle is very flexible, and we have defined (or in the process of defining) the following tasks (same as Ant’s targets).
Clean up of all build output and restoring the code base to a fresh state.
This is the default build, which compiles the code and run the tests, but nothing else. A quick way to check that nothing broke.
Is roughly the same as Maven’s install goal. It produces the test reports and javadocs and installs all the Jars into the local disk repository, for consumption by other applications.
Produces all the archives, javadocs, manuals and website content. The output is generated to qi4j-sdk/build.
Uploads the release artifacts to the distribution servers and creates the release output into the qi4j-sdk/build/distributions directory.
Build System configuration is done through Gradle properties.
This can be done in many ways, see Gradle properties and system properties.
Artifact signing is done using PGP. You need to provide Gradle the following properties
signing.keyId=FB751943 signing.password=foobar signing.secretKeyRingFile=/home/foo/.gnupg/secring.gpg
Artifact upload behavior depends on the version assigned to the build.
By default RELEASES are signed, SNAPSHOTS are not.
Signing can be turned on or off by setting the uploadSigned property to false.
By default RELEASES must satisfy ReleaseSpecification, SNAPSHOT don’t.
ReleaseSpecification usage can be turned on or off by setting the uploadReleaseSpec property to false.
By default RELEASES and SNAPHOTS are uploaded using WEBDAV.
Used Wagon can be overriden by setting the uploadWagon property.
By default RELEASES and SNAPSHOTS are uploaded to Cloudbees.
Target repository can be overriden by setting the uploadRepository property.
No username/password is provided by default.
If needed set them using the uploadUsername and uploadPassword properties.
For example here is how to deploy all artifacts as unsigned SNAPSHOTs to a given repository:
./gradlew uploadArchives -Dversion=2.0-SNAPSHOT -PuploadReleaseSpec=false \
-PuploadWagon=what:ever:wagon -PuploadRepository=http://what.ever.repository/url \
-PuploadUsername=foo -PuploadPassword=barAnd here is how to deploy a signed release to the local filesystem:
./gradlew uploadArchives -Dversion=2.0 -PuploadRepository=file:///path/to/local/repository
See the Gradle documentation about supported protocols.
The documents use the asciidoc format, see:
The cheatsheet is really useful!
| Tip | |
|---|---|
To generate the website locally use |
Each (sub)project has its own documentation, in src/docs/ and all the Asciidoc documents have the .txt file extension.
The documents can use code snippets which will extract code from the project. This is preferred way to include source code in the documentation, since any refactoring will be reflected in the documentation.
The above files are all consumed by the build of the manual (by adding them as dependencies). To get content included in the manual, it has to be explicitly included by a document in the manual as well.
The whole documentation set is generated from the *manual* module in the qi4j-sdk, and we are currently only creating the website.
The User Guide and Reference Manual are future projects.
Each document starts over with headings from level zero (the document title). Each document should have an id. In some cases sections in the document need to have id’s as well, this depends on where they fit in the overall structure. To be able to link to content, it has to have an id. Missing id’s in mandatory places will produce warnings, or even fail (depending on severity), the build.
This is how a document should start:
[[unique-id-verbose-is-ok,Remember This Caption]] = The Document Title =
To push the headings down to the right level in the output, the leveloffset
attribute is used when including the document inside of another document.
Subsequent headings in a document should use the following syntax:
== Subheading == ... content here ... === Subsubheading === content here ...
Asciidoc comes with one more syntax for headings, but in this project it’s not used.
Try to put one sentence on each line. Lines without empty lines between them still belongs to the same paragraph. This makes it easy to move content around, and also easy to spot (too) long sentences.
- A chapter can’t be empty. (the build will fail on the docbook xml validity check)
-
The document title should be "underlined" by the same
number of
=as there are characters in the title. - Always leave a blank line at the end of documents (or the title of the next document might end up in the last paragraph of the document)
-
As
{}are used for Asciidoc attributes, everything inside will be treated as an attribute. What you have to do is to escape the opening brace:\{. If you don’t, the braces and the text inside them will be removed without any warning being issued!
To link to other parts of the manual the id of the target is used. This is how such a reference looks:
<<community-docs-overall-flow>>
Which will render like: Documentation Flow
| Note | |
|---|---|
Just write "see <<target-id>>" and similar, that’s enough in most cases. |
If you need to link to another document with your own link text, this is what to do:
<<target-id, link text that fits in the context>>
| Note | |
|---|---|
Having lots of linked text may work well in a web context but is a pain in print, and we aim for both! |
External links are added like this:
http://www.qi4j.org/[Link text here]
Which renders like: Link text here
For short links it may be better not to add a link text, just do:
http://www.qi4j.org/
Which renders like: http://www.qi4j.org/
It’s ok to have a dot right after the URL, it won’t be part of the link.
http://www.qi4j.org/.
Which renders like: http://www.qi4j.org/.
- Bold - just don’t do it, the editor in charge is likely to remove it anyhow!
- _Italics_ is rendered as Italics
-
+methodName()+ is rendered as
methodName()and is used for literals as well -
`command` is rendered as
command(typically used for command-line) - 'my/path/' is rendered as my/path/ (used for file names and paths)
These are very useful and should be used where appropriate. Choose from the following (write all caps and no, we can’t easily add new ones):
| Note | |
|---|---|
Note. |
| Tip | |
|---|---|
Tip. |
| Important | |
|---|---|
Important |
| Caution | |
|---|---|
Caution |
| Warning | |
|---|---|
Warning |
Here’s how it’s done:
NOTE: Note.
A multiline variation:
[TIP] Tiptext. Line 2.
Which is rendered as:
| Tip | |
|---|---|
Tiptext. Line 2. |
| Important | |
|---|---|
All images in the entire manual share the same namespace. |
To include an image file, make sure it resides in the images/ directory relative to the document you’re including it from. Then go:
image::logo-standard.png[]
Which is rendered as:
Please note that the images/ directory is added automatically and not part of the link.
There are also global resources, residing in manual/src/resources, which will be copied to the root of the documentation.
Most source code that is included in the documentation should be extract via SNIPPET markers and then included in document with;
[snippet,java] ----------- source=tutorials/introduction/tenminutes/src/main/java/org/qi4j/demo/tenminute/OrderEntity.java tag=mainClass -----------
The source file is relative to the qi4j-sdk root, and the tag is defined in the source file.
The above could be bringing in content that looks like;
package org.qi4j.demo.tenminute;
import org.qi4j.api.concern.Concerns;
import org.qi4j.api.entity.EntityComposite;
import org.qi4j.api.sideeffect.SideEffects;
// START SNIPPET: sideEffect
@SideEffects( MailNotifySideEffect.class )
// START SNIPPET: mainClass
@Concerns({PurchaseLimitConcern.class, InventoryConcern.class})
public interface OrderEntity
extends Order, HasSequenceNumber, HasCustomer,
HasLineItems, Confirmable, EntityComposite
{
// END SNIPPET: sideEffect
}
// END SNIPPET: mainClasswhich will be rendered as;
@Concerns( { PurchaseLimitConcern.class, InventoryConcern.class } )
public interface OrderEntity
extends Order, Confirmable,
HasSequenceNumber, HasCustomer, HasLineItems,
EntityComposite
{
}
Note that 1. The START and END doesn’t need to be matching. 1. The AsciiDoc plugin will remove the START SNIPPET and END SNIPPET lines. 1. If you have more than one START/END section with the same tag, the plugin will insert a "[…snip…]" for the excluded lines.
| Warning | |
|---|---|
Use this kind of code snippets as little as possible. They are well known to get out of sync with reality after a while. |
This is how to do it:
[source,java]
----
HashMap<String,String> result = new HashMap<String,String>();
for( String name : names )
{
if( !"".equals( name ) )
result.put( name, value );
}
----Which is rendered as:
HashMap<String,String> result = new HashMap<String,String>();
for( String name : names )
{
if( !"".equals( name ) )
result.put( name, value );
}If there’s no suitable syntax highlighter, just omit the language: [source].
Currently the following syntax highlighters are enabled:
- Bash
- Groovy
- Java
- JavaScript
- Python
- Ruby
- Scala
- XML
For other highlighters we could add see http://alexgorbatchev.com/SyntaxHighlighter/manual/brushes/.
Common attributes you can use in documents:
These can substitute part of URLs that point to for example APIdocs or source code.
Useful links when configuring the docbook toolchain:
- http://www.methods.co.nz/asciidoc
- http://powerman.name/doc/asciidoc
- alexgorbatchev.com/SyntaxHighlighter/manual/brushes/
- http://www.docbook.org/tdg/en/html/docbook.html
- http://www.sagehill.net/docbookxsl/index.html
- http://docbook.sourceforge.net/release/xsl/1.76.1/doc/html/index.html
- http://docbook.sourceforge.net/release/xsl/1.76.1/doc/fo/index.html
The Qi4j SDK comes with several sample applications. This is a very good place to look for code examples and recipes.
The samples are available in the samples/ directory of the Qi4j SDK.
Sample of how DCI (Data, Context & Interaction) pattern is implemented using Qi4j core only.
Sample of how DCI (Data, Context & Interaction) pattern is implemented with Qi4j, for Eric Evans DDD sample.
This sample, contributed by Marc Grue, is described in details on his website: http://marcgrue.com/
Sample of how to build a web forum using ReST Server Library, Neo4j EntityStore and FileConfig Library.
Sample of implementation of a Car Rental application implemented as a Servlet based Webapp packaged as a WAR.
| Note | |
|---|---|
This sample use PostgreSQL and drop all of its data once run in order to be runnable multiple times. |
Sample of how to fully use Qi4j SQL support : SQL Library, SQL EntityStore and SQL Index/Query.
A gradle task runSample is defined in this module as a shortcut to run the example. See Build System.
The Qi4j Core is composed of several artifacts described in this section.
The following figure show the Core artifacts alongside libraries and extensions, and, in green, typical applications artifacts. This is not a full code dependency graph but should give you a good overview of how the pieces fit together. Find out more about each of the Qi4j Core artifacts below.

The Qi4j Core API is the primary interface for client application code during the main execution phase, i.e. after the application has been activated.
Qi4j has a distinct bootstrap phase, also known as the Assembly of an application, where the applications structure is defined programmatically. Once all the layers, modules and all the composite types in each module have been defined the model is instantiated into an application. This enables the entire structure system in Qi4j, where types "belongs" to a module and visibility rules define default behaviors, enforcement of architectural integrity and much more.
Qi4j comes with classes to help with testing. There is also some mocking support, to allow some of Qi4j’s unique aspects to be mocked, but since Qi4j is so flexible at a fine-granular level, we have found that mocking is seldom, if ever, needed.
The Qi4j Core Functional API is a generic package to work with Iterables in a "functional programming language" style.
This package is completely independent of everything else in Qi4j and may be used on its own in any kind of environment such as Spring or Java EE applications.
The Qi4j Core I/O API tries to address the problem around shuffling data around from various I/O inputs and outputs, possibly with transformations and filtering along the way.
The Qi4j Core Runtime has a number of extension points, which we call the Qi4j Core Extension SPI. These are defined interfaces used only by the Core Runtime and never directly by application code. Extensions are assembled in applications during the bootstrap phase.
Your code should never, ever, have a dependency on Qi4j Core Runtime. If you think you need this, you should probably contact qi4j-dev forum at Google Groups and see if your usecase can either be solved in a existing way or perhaps that a new Core Extension SPI is needed.
code
docs
tests
The Qi4j Core API is the primary interface for client application code during the main execution phase, i.e. after the application has been activated.
Composition is at the heart of COP, and refers to two different levels of constructs;
- the ability to assemble (compose) objects from smaller pieces, called Fragments.
- the construction of applications by assembling Composites into Modules and Modules into Layers.
In Qi4j, we use the term Assembly for the second case of composition. See separate chapter.
Composition will allow library authors a new level of flexibility in how functionality is provided to client code. More on that later.
There are 4 types of Fragments in Qi4j;
- Mixin - The state carrying part of a Composite.
- Constraint - Rules for in and out arguments, typically used for validation.
- Concern - Interceptor of method calls. General purpose use, often for cross-cutting behaviors.
- SideEffect - Executed after the method call has been completed, and unable to influence the outcome of the method call.
There are 4 Composite meta types. Each of these have very different characteristics and it is important to understand these, so the right meta type is used for the right purpose.
- Entity - Classic meaning. Has an Identity. Is persistable and can be referenced by the Identity. Can act as Aggregate. Entity supports Lifecycle interface. Equals is defined by the Identity.
- Value - Values are persistable when used in a Property from an Entity. Values are immutable, and equals is defined by the values of its fields.
- Service - Service is injectable to other composites and java objects. They are not persistable, but if referenced from an Entity or Value, a new reference to the Service will be injected when the Entity/Value is deserialized. Services are singletons. There are hosted and imported Services. The hosted Service has Configuration and its life cycle controlled by the Qi4j runtime, whereas the imported Services are external references.
- Transient - Short-lived composites that are not persistable. Equals/hashCode/toString are forwarded to the Mixin Type declaring those methods explicitly.
In versions of Qi4j prior to 2.0, composite types had to extend one of these 4 meta types, but in 2.0 and later, the meta type interface is added dynamically during Assembly. We can therefor get rid of a lot of additional types, and use Qi4j-free interfaces directly;
@Mixins( { BalanceCheckMixin.class } )
public interface BankAccount
{
Money checkBalance();
[...snip...]
}
and declare it with;
public void assemble( ModuleAssembly module )
{
module.entities( BankAccount.class );
}
Qi4j promotes a conventional view of application structure, that computer science has been using for decades.
The definition is as follows;
- One Application per Qi4j runtime instance.
- One or more Layers per Application.
- Zero, one or more Modules per Layer.
- Zero, one or more Assemblies per Module.
The principle of this Structure is to assist the programmer to create well modularized applications, that are easily extended and maintained. Qi4j will restrict access between Modules, so that code can only reach Composites and Objects in Modules (including itself) of the same or lower Layers.
Each Layer has to be declared which lower Layer(s) it uses, and it is not allowed that a lower Layer uses a higher Layer, i.e. cyclic references.
Every Qi4j runtime has one and only one Application in it. It is possible to run multiple Qi4j runtimes in the same JVM, and it is even possible to embed a Qi4j runtime within a Qi4j Application, but there can only be one Application in a Qi4j runtime.
An Application is then broken into layers and modules are placed within those layers. Composites are placed within modules. This forms the Application Structure and is enforced by the Qi4j runtime.
A Qi4j Application must consist of at least one layer. More layers are common, often dividing the application along the common architectural diagrams used on whiteboards, perhaps with a UI layer at the top, followed by a service or application layer, then with a domain layer and finally some persistence layer at the bottom.
Qi4j enforces this layering by requiring the Assembly to declare which layer uses which other layer. And Visibility rules define that layers below can not locate composites in layers above. Also, defining that "Layer1 uses Layer2" and "Layer2 uses Layer3" does NOT imply that Layer1 has Visibility to Layer3. If that is wanted, then it must be declared explicitly.
Modules are logical compartments to assist developers in creating and maintaining well modularized code. A Module only belongs to a single Layer, but many Modules can exist in the same Layer. Composite access is limited to;
- Composites within the same Module, with Visibility set to Visibility.module (default).
- Composites from Modules in the same Layer, with Visibility set to Visibility.layer
- Composites from Modules in Layers below, with Visibility set to Visibility.application
Modules contains a lot of the Qi4j infrastructure, which are the enforcers of these wise modularization principles.
It is not possible to modify the Modules, their resolution nor binding in any way after the application starts.
Usage of value objects is one of the most ignored and best return-on-investment the programmer can do. Values are immutable and can be compared by value instead of memory reference. Concurrency is suddenly not an issue, since either the value exists or it doesn’t, no need for synchronization. Values are typically very easy to test and very robust to refactoring.
Qi4j defines values as a primary meta type through the ValueComposite, as we think the benefits of values are great. The ValueComposite is very light-weight compared to the EntityComposite, and its value can still be persisted as part of an EntityComposite via a Property.
The characteristics of a ValueComposite compared to other Composite meta types are;
- It is Immutable.
- Its equals/hashCode works on both the descriptor and the values of the ValueComposite.
- Can be used as Property types.
- Can be serialized and deserialized.
Value objects can be serialized and deserialized using the ValueSerialization API which is a Service API implemented by SPI and extensions.
| Tip | |
|---|---|
|
The ValueSerialization mechanism apply to the following object types :
- ValueComposite,
- EntityReference,
- Iterable,
- Map,
- Plain Value.
Nested Plain Values, EntityReferences, Iterables, Maps, ValueComposites are supported. EntityComposites and EntityReferences are serialized as their identity string.
Plain Values can be one of :
- String,
- Character or char,
- Boolean or boolean,
- Integer or int,
- Long or long,
- Short or short,
- Byte or byte,
- Float or float,
- Double or double,
- BigInteger,
- BigDecimal,
- Date,
- DateTime (JodaTime),
- LocalDateTime (JodaTime),
- LocalDate (JodaTime).
Values of unknown types and all arrays are considered as java.io.Serializable and by so are (de)serialized to (from)
base64 encoded bytes using pure Java serialization. If it happens that the value is not Serializable or the input to
deserialize is invalid, a ValueSerializationException is thrown.
Methods of ValueSerializer allow to specify if the serialized state should contain extra type information about the
serialized value. Having type information in the serialized payload allows to keep actual ValueComposite types and by so
circumvent AmbiguousTypeException when deserializing.
Core Runtime provides a default ValueSerialization system based on the org.json Java library producing and consuming JSON.
Let’s see how it works in practice.
public interface SomeValue // (1)
{
Property<String> foo();
}
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
module.values( SomeValue.class ); // (2)
[...snip...]
}
[...snip...]
public void defaultValueSerialization()
{
SomeValue someValue = someNewValueInstance( module ); // (3)
String json = someValue.toString(); // (4)
SomeValue someNewValue = module.newValueFromSerializedState( SomeValue.class, json ); // (5)
[...snip...]
}
Reading this first example step by step we ;
- declare a ValueComposite,
- assemble it,
- create a new Value instance,
-
use the
ValueComposite#toString()method to get a JSON representation of the Value, -
and finally, use the
Module#newValueFromSerializedState()method to create a new Value instance from the JSON state.
ValueComposite#toString() method leverage Value Serialization and by so provide JSON based representation. The Module
API allows to create new Value instances from serialized state.
On top of that, Application assemblies can register different implementation of ValueSerialization as Services to support more formats, see the Extensions section. Note that the default behaviour described above is overriden if a ValueSerialization Service is visible.
Let’s see how to use the ValueSerialization Services.
public interface SomeValue // (1)
{
Property<String> foo();
}
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
module.values( SomeValue.class ); // (2)
new OrgJsonValueSerializationAssembler().assemble( module ); // (3)
}
[...snip...]
@Service
private ValueSerializer valueSerializer; // (4)
@Service
private ValueDeserializer valueDeserializer; // (4)
[...snip...]
public void assembledDefaultServiceSerialization()
{
SomeValue someValue = someNewValueInstance( module ); // (5)
String json = valueSerializer.serialize( someValue ); // (6)
SomeValue someNewValue = valueDeserializer.deserialize( SomeValue.class, json ); // (7)
[...snip...]
}
In this second example, we ;
- declare a ValueComposite,
- assemble it,
-
assemble a ValueSerialization Service backed by the
org.jsonpackage, -
get the
ValueSerializerandValueDeserializerServices injected, - create a new Value instance,
-
use the
ValueSerializer#serialize()method to get a JSON representation of the Value, -
and finally, use the
ValueDeserializer#eserialize()method to create a new Value instance from the JSON state.
Many applications need to stream data. The ValueSerialization API support such use cases in two ways.
The first one use classic streams.
public void assembledServiceStreamingSerialization()
{
[...snip...]
// (1)
Iterable<AcmeValue> data = dataSource; // Eg. Entities converted to Values
OutputStream output = targetStream; // Eg. streaming JSON over HTTP
// (2)
valueSerializer.serialize( data, output );
[...snip...]
// (3)
InputStream input = sourceStream; // Eg. reading incoming JSON
// (4)
List<AcmeValue> values = valueDeserializer.deserialize( CollectionType.listOf( AcmeValue.class ), input );
[...snip...]
}
-
get a handle on a source of values and an
OutputStream, -
serialize data into the
OutputStream, -
get a handle on an
InputStream, -
deserialize data from the
InputStream.
The second one use the I/O API:
public void assembledServiceIOSerialization()
throws IOException
{
[...snip...]
// (1)
Iterable<AcmeValue> queryResult = dataSource; // Eg. Entities converted to Values
Writer writer = outputWriter; // Eg. to pipe data to another process or to a file
// (2)
Function<AcmeValue, String> serialize = valueSerializer.serialize();
// (3)
Inputs.iterable( queryResult ).transferTo( Transforms.map( serialize, Outputs.text( writer ) ) );
[...snip...]
// (4)
Reader reader = inputReader;
List<AcmeValue> values = new ArrayList<AcmeValue>();
// (5)
Function<String, AcmeValue> deserialize = valueDeserializer.deserialize( AcmeValue.class );
// Deserialization of a collection of AcmeValue from a String.
// One serialized AcmeValue per line.
// (6)
Inputs.text( reader ).transferTo( Transforms.map( deserialize, Outputs.collection( values ) ) );
[...snip...]
}
-
get a handle on a source of values and a
Writer, -
prepare the serialization
Function, - serialize a collection of values, one serialized value per line,
-
get a handle on a serialized values
Readerand create a new emptyListof values, -
prepare the deserialization
Function, - deserialize a collection of values from read lines.
Any service added, via the ModuleAssembly.addServices(), ModuleAssembly.services() and ModuleAssembly.importServices() methods, will have the ServiceComposite meta type added to it. In Qi4j, when we speak of Services we mean instances of ServiceComposite.
Most programmers are familiar with the term "Service", and after the failure of Object Oriented Programming’s promise to encapsulate all the behavior together with the object’s state, programmers learned that the only way to deal with decoupling and re-use was to make the objects into data containers and deploy services that acted upon those data containers. Very much what functions did on structs back in the C and Pascal days.
Qi4j will bring a lot of the behavior back to the Composite itself, but we still need Services for cross-composite functionality. The Qi4j Service model is fairly simple, yet powerful and flexible enough to accommodate most service-oriented patterns and ability to integrate well with external systems whether they are in-JVM or remote, such as Spring, OSGi, WS-*, Rest and others.
The characteristics of a ServiceComposite compared to other Composite meta types are;
- It is one singleton per declaration in bootstrap.
- It has an identity defined in bootstrap.
- It has an Activation life cycle into which Activators hook.
- It has an optional Configuration.
Services in Qi4j are singletons, one instance per definition. That means that there may exist multiple instances of the same service type, but they can not be created on the fly in runtime, but has to be explicitly defined during Assembly.
By default, Services are not instantiated until they are used. This means that the ServiceComposite instance itself will not exist until someone calls a method. If a Service needs to be instantiated when the Module is activated, one need to declare/call the instantiateOnStartup() method on the ServiceDescriptor during the bootstrap.
The configuration for a service is well supported in Qi4j. See the Service Configuration chapter for details.
Services are activated (injected and instantiated) either on application start-up, or upon first use. This is controlled by calling instantiateOnStartup(), this way;
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
ServiceDeclaration service = module.addServices( MyDemoService.class );
service.instantiateOnStartup();
If this method is not called during assembly, the activation will occur on first service usage.
Passivation occurs when a Module is deactivated, typically because the whole application is shutting down. Passivation occurs in the reverse order of the activation, to ensure that dependent services are still available for a passivating service.
Activators assembled with the service will get their beforeActivation and afterActivation methods called around the ServiceComposite activation and their beforePassivation and afterPassivation around the ServiceComposite passivation. Member injection and constructor initialization occur during the activation. The ServiceComposite can be used from the afterActivation to the beforePassivation method.
Services has an Identity, which drives the Service Configuration system and can be used to lookup a particular service instance. Services can also be arbitrarily tagged, via the ServiceDescriptor. Example;
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
ServiceDeclaration service = module.addServices( MyDemoService.class );
[...snip...]
service.taggedWith( "Important", "Drain" );
Tags are useful inside the application code to locate a particular service instance, in case we have many. For instance;
@Service
private List<ServiceReference<MyDemoService>> services;
public MyDemoService locateImportantService()
{
for( ServiceReference<MyDemoService> ref : services )
{
ServiceTags serviceTags = ref.metaInfo( ServiceTags.class );
if( serviceTags.hasTag( "Important" ) )
{
return ref.get();
}
}
return null;
}
Configuration in Qi4j is for Qi4j ServiceComposite only. The Configuration is stored in a visible Entity Store and is therefor runtime modifiable and not static in properties or XML files as in most other dependency injection frameworks.
The Configuration system itself will handle all the details with interfacing with reading and writing the configuration. The normal UnitOfWork management is used, but handled internally by the configuration system.
In Qi4j, Configuration are strongly typed and refactoring-friendly. Configuration is read from the entity store, but if it can not be found, then it will try to bootstrap it from a properties file, with the same name as the ServiceDescriptor.identifiedBy(), which is set during Assembly and defaults to the fully qualified classname of the ServiceComposite type.
The Configuration type is simply listing the properties that are available. The standard rules on @UseDefaults and @Optional applies. Example;
public interface MailServiceConfiguration extends ConfigurationComposite
{
Property<String> hostName();
Property<Integer> port();
}
It is important to remember that Configuration is not static values that are set prior to application start-up and therefor applications should not cache the values retrieved forever, but consciously know when the configuration should be re-read.
Configuration is injected via the @This injection scope. One reasonable strategy is to read the configuration on service activation, so by deactivating/reactivating a service, the user have a well-defined behavior to know how configuration changes take effect. Example;
@This
private Configuration<MailServiceConfiguration> config;
@Override
public void sendMail( @Email String to, @MinLength( 8 ) String subject, String body )
{
config.refresh();
MailServiceConfiguration conf = config.get();
String hostName = conf.hostName().get();
int port = conf.port().get();
[...snip...]
}
Configuration is modifiable, and after the modifications have been made, the save() method on the Configuration type must be called. Example;
void changeExternalMailService( String hostName, int port );
[...snip...]
@Override
public void changeExternalMailService( String hostName, int port )
{
MailServiceConfiguration conf = config.get();
conf.hostName().set( hostName );
conf.port().set( port );
config.save();
}
[...snip...]
}
}
Entities are common in the object oriented programming world, but has never reached the stardom of Class and Object. Instead we have seen many attempts at creating Entities on top of Java, such as EJB (3 incompatible versions), Java Data Objects (JDO, 2 somewhat compatible versions), Java Persistence Architecture (JPA, 2 somewhat compatible versions), Hibernate (4+ somewhat incompatible versions) and many other less known. This seems to suggest that the topic of creating objects that survives over long periods of time is a difficult one.
Eric Evans points out in his book that Entities is a very definite and distinct concept that needs to be handled explicitly. Composite Oriented Programming in general, and Qi4j in particular, takes this point very seriously and makes Entities a central part of the whole system. And likewise, we are convinced that it is not possible to develop domain-knowledge-rich applications without a conscious and well-defined strategy on Entities. So, instead of spending endless hours trying to get Hibernate mapping to do the right thing, we introduce a Composite meta type called EntityComposite, which all entities must derive from, and by doing so automatically become persistable, searchable, have a lifecycle and support nested undoable modifications.
The characteristics of an EntityComposite compared to other Composite meta types are;
- It has an Identity.
- It has a LifeCycle.
- It is typically persisted.
- It can only be referenced by an Association or ManyAssociation.
- Its CRUD operations are bound by a UnitOfWork.
A UnitOfWork is a bounded group of operations performed, typically on entities, where these operations are not visible to other threads until the UnitOfWork is completed. It is also possible to discard these operations, as if they were never executed.
| Note | |
|---|---|
UnitOfWork has many similarities with the Transaction concept used with RDBMSes. But since Qi4j introduced several deviations to the common definitions of Transactions, we chose to use a different term. |
There are several key characteristics of UnitOfWork;
- They are limited to a single thread.
- They have an associated use-case.
- They can be paused and resumed.
- They have a notification mechanism (used to trigger Indexing for instance).
- They can be long-running, as they don’t tie up underlying transactions or other expensive resources.
At the moment, they are exclusively used to manipulate EntityComposite composites. All entity operations MUST be done via UnitOfWork, and in fact it is not possible to get this wrong.
UnitOfWork is associated with a thread, and can only be transferred to another thread by a relatively complex operation of pausing a UnitOfWork in one thread, then hand over the UnitOfWork to the other thread and resume it there. Don’t do it!
UnitOfWork is available from the Module, and from the Module you request either a new UnitOfWork or asking for the _current one. Current UnitOfWork means the UnitOfWork that was created earlier within the same thread. So, typically most entity manipulation code only request the current UnitOfWork and the management of creating, completing and aborting the UnitOfWork is handled by the transaction boundary, often in the so called application layer (see Layer)
Since it is very common to have all, or nearly all, methods in the transaction boundary to handle the creation and completion, possibly with retry, in the same class, module or even layer, Qi4j provides
TransientComposite is a Composite meta type for all other cases. The main characteristics are;
- It can not be serialized nor persisted.
- hashcode/equals are not treated specially and will be delegated to fragment(s) implementing those methods.
- It can not be used as a Property type.
Mixins are the state-carrying part of a Composite instance. The other Fragments can not retain state between method invocations as they are shared across Composite instances.
The Mixin Type is the interface that declares the Mixin methods. Each Mixin implementation (the classes defined in the @Mixins annotation of a Composite declaration) implements one or more methods from one or more Mixin Types.
Mixin Type can be very simple, like;
public interface BankAccount
{
Money checkBalance();
}
Or contain hundreds of methods, subclassed from dozens of super interfaces.
The Mixin Types of a Composite are ;
- all the aggregated interfaces of the Composite Type, minus Composite meta-type interfaces, and
- all private mixin referenced types.
There is not a 1:1 correlation between Mixin Type and Mixin implementation. One can’t even know if there are more or less of one over the other. That is because a Mixin implementation can implement less than one, one, or more than one Mixin Type.
It is also entirely possible that multiple implementation methods exists for a Mixin Type method. The mixin method resolution algorithm will provide a deterministic behavior of which implementation of a method is chosen. The algorithm is as follows;
For each declared method of all Mixin Types of a Composite;
- Iterate all Mixin types declared from left to right in the declaration,
- Iterate all Mixin types of super-interfaces from left to right in the extends clause,
- Iterate all Mixin types within one interface before succeeding to the next interface,
- Iterate all super-interface Mixin types before proceeding to the super-interfaces of those,
- Iterate all Typed Mixin implementations of all super-interfaces, before repeating the algorithm for Generic Mixin implementations,
This means that one Mixin implementation can override a single method that a larger mixin implementation implements together with many other methods. So, just because a mixin implements MixinTypeA.method1() and has an implementation of MixinTypeA.method2(), doesn’t mean that method2() is mapped to that mixin. This is very important to remember. The Envisage tool is capable of visualizing how Mixin Type methods are mapped to implementations.
Mixins are the state holders of the composite instance. Public Mixins are the mixins that are exposed to the outside world via the CompositeType interface.
Each method in the CompositeType interface MUST be backed by a mixin class.
Mixins are declared as annotations on the composite interface.
@Mixins( SomethingMixin.class )
public interface Something
{}
public class SomethingMixin
implements Something
{
// State is allowed.
public void doSomething()
{
// do stuff...
}
}
In the above sample, the SomethingMixin will be made part of the Something composite.
If we have many interfaces defining many methods, that all must be backed by a mixin implementation, we simply list all the mixins required.
@Mixins( { StartMixin.class, VehicleMixin.class } )
public interface Car extends Startable, Vehicle
{}
public interface Startable
{
boolean start();
void stop();
}
public interface Vehicle
{
void turn(float angle);
void accelerate(float acceleration);
// more methods
}
In the example above, the VehicleMixin would need to deal with all methods defined in the Vehicle interface. That interface could be very large, and could be totally independent concerns. So, instead we should use abstract mixins, which are ordinary mixins but are lacking some methods. This is simply done by declaring the class abstract.
@Mixins( { StartMixin.class, SpeedMixin.class, CrashResultMixin.class } )
public interface Car extends Startable, Vehicle
{}
public interface Vehicle extends SpeedLocation, Crashable
{
}
public interface SpeedLocation
{
void turn(float angle);
void accelerate(float acceleration);
}
public abstract class SpeedMixin
implements SpeedLocation
{
// state for speed
public void accelerate( float acceleration )
{
// logic
}
}
Above the SpeedMixin only implements the accelerate() method, and Qi4j will only map that method to this mixin. The other method of the SpeedLocation interface is not satisfied as the example is written and will generate a runtime exception.
Public mixins expose their methods in the composite interface, and this is not always desirable. Qi4j supports Private Mixins, which are only visible within the composite itself. That means that other fragments in the composite can see/use it, but it is not visible to the clients of the composite.
Private Mixins are handled automatically. When Qi4j detects a @This annotation referring to a type that is not defined in the Composite interface, then that is a Private Mixin. The Mixin implementation class, however, must exist in the list of Mixins in the @Mixins annotation. But often, the Private Mixin only list internal Property methods in the Mixin Type, which will be satisfied by the standard PropertyMixin and hence always available.
This is particularly useful in Domain Driven Design, where you only want to expose domain methods, which are defined by the context where they are used. But the state of the Mixin should not be exposed out at all. For instance, if we have the Cargo interface like;
@Mixins( CargoMixin.class )
public interface Cargo extends EntityComposite
{
String origin();
String destination();
void changeDestination( String newDestination );
}
The interface is defined by its context, and not really exposing the internal state. So in the implementation we probably do something like;
public abstract class CargoMixin
implements Cargo
{
@This
private CargoState state;
public String origin()
{
return state.origin().get();
}
public String destination()
{
return state.destination().get();
}
public void changeDestination( String newDestination )
{
state.destination().set( newDestination );
}
}
public interface CargoState
{
Property<String> origin();
Property<String> destination();
}
So, in this typical case, we don’t need to declare the Mixin for the CargoState, as it only defines Property methods, which are handled by the standard PropertyMixin always present.
Mixins, Concerns and SideEffects can either be "typed" or "generic". A Typed Mixin implementation implements one or more Mixin Type interfaces, and one or more of the methods of those interfaces. A Generic Mixin implementation implements java.lang.reflect.InvocationHandler, and can therefor be matched to any method of any interface. Typically, AppliesTo annotation is used to filter the methods that such Generic Mixin implementation is mapped against, and sometimes Generic Mixin implementations are "last resort".
Experience shows that Generic Mixin implementations are rare, and should only be used in extreme cases. They are less frequent than Generic Concern or Generic SideEffect implementations, but inside the Qi4j API are a couple of Generic Mixin implementations that are always present to make the life of the developer easier, such as PropertyMixin, AssociationMixin, ManyAssociationMixin, NoopMixin. The first 3 are declared on the Composite and EntityComposite interfaces and automatically included if needed. They also serve as excellent example of what they can be used for.
@AppliesTo( { PropertyMixin.PropertyFilter.class } )
public final class PropertyMixin
implements InvocationHandler
{
@State
private StateHolder state;
@Override
public Object invoke( Object proxy, Method method, Object[] args )
throws Throwable
{
return state.propertyFor( method );
}
/**
* Filter Property methods to apply generic Property Mixin.
*/
public static class PropertyFilter
implements AppliesToFilter
{
@Override
public boolean appliesTo( Method method, Class<?> mixin, Class<?> compositeType, Class<?> modifierClass )
{
return Property.class.isAssignableFrom( method.getReturnType() );
}
}
}
Other examples that we have come across;
- Mapping from Property<type> to POJO style "properties".
- Remote Service delegation.
- Scripting delegation, where a script will implement the Mixin Type.
which seems to indicate that Generic Mixin implementations are likely to be used in integration of other technologies.
Typed Mixin implementations are much preferred in general business logic, as they will be first-class citizens of the IDE as well, for navigation, find usage, refactoring and many other common tasks. This is one of the main advantages of the Qi4j way of doing AOP compared to AspectJ et al, where "weaving" is something bolted onto an application’s classes via regular expressions and known naming conventions, which can change in an instance by a developer being unaware of which PointCuts applies to his code.
Concerns are the equivalent of "around advice" in Aspect Oriented Programming. They are chained into an invocation stack for each Mixin Type method and invoked after the Constraints have been executed. Since they are sitting "around" the Mixin implementation method, they also have a chance to modify the returned result, and even skip calling the underlying Mixin method implementation altogether.
To create a concern, you need to create a class that,
- implements the Mixin Type (Typed Concerns) or java.lang.reflect.InvocationHandler (Generic Concerns),
- extend ConcernOf (Typed Concerns) or GenericConcern (Generic Concerns) [1]
You are allowed to modify both the in-arguments as well as the returned value, including throw exceptions if that is suitable, perhaps for post condition checks.
As mentioned above, concerns that implements the Mixin Type are called Typed Mixins. They are more common in the business domain, and can be used for many important things in the domain model, such as checking post conditions (i.e. ensure that the state in the entire composite is valid), coordinating services, handling events and much more.
Typed Concerns doesn’t have to implement all the methods in the Mixin Type. By making the class abstract and only implementing the methods of interest, Qi4j will subclass the concern (otherwise not valid for the JVM), but the generated methods will never be invoked.
In classic AOP, all advice are effectively generic. There is no type information in the advice implementation and the pointcut can be defined anywhere in the code, and the implementation uses proxy InvocationHandlers. Qi4j supports this construct as well, and we call it Generic Concern.
Generic Concerns will be added to all methods that the AppliesToFilter evaluates to true. By default, that is all methods.
AppliesToFilters is a mechanism to limit, or direct, which methods that the concern should be added to. You have full control over this selection process, via several mechanisms.
- @AppliesTo annotation can be put on the concern, with either;
- an interface for which the methods should be wrapped, or
- an AppliesToFilter implementation that is consulted during building the invocation stack, or
- an annotation type that must be given on the method.
- Concerns are added only to composites that declares the Concern, either in
- the Composite Type, or
- during assembly in the withConcerns() method.
This means that we can make the following three samples of concerns. First the generic concern that is added to the methods of the JDBC Connection class;
@AppliesTo( java.sql.Connection.class )
public class CacheConcern extends GenericConcern
implements InvocationHandler
{
We can also use an AppliesToFilter to define which methods should be wrapped with the concern, like this;
@AppliesTo( BusinessAppliesToFilter.class )
public class BusinessConcern extends GenericConcern
implements InvocationHandler
{
[...snip...]
public class BusinessAppliesToFilter
implements AppliesToFilter
{
@Override
public boolean appliesTo( Method method, Class<?> mixin, Class<?> compositeType, Class<?> fragmentClass
)
{
return true; // Some criteria for when a method is wrapped with the concern.
}
}
And finally an example of how to use annotations to mark indvidual methods for being wrapped by the concern.
@AppliesTo( Audited.class )
public class AuditConcern extends GenericConcern
implements InvocationHandler
{
[...snip...]
@Override
public Object invoke( Object proxy, Method method, Object[] args )
throws Throwable
{
return null;
}
}
[...snip...]
@Retention( RetentionPolicy.RUNTIME )
@Target( { ElementType.METHOD } )
@Documented
@InjectionScope
public @interface Audited
{
}
| Note | |
|---|---|
Even if a method fulfills the requirement for the concern, if the concern is not declared for the Composite then the concern will NOT be applied. |
The concerns are invoked AFTER all Constraint have been checked. The concerns are executed before the SideEffect are executed in the return path.
The order of execution is defined by the declaration order, interface hierarchy, whether the concern is generic or typed and if they are declared in the interface or declared in the Assembly.
From the perspective of incoming call, i.e. after the <core-api-constraint>> have been checked, the following rules are in place;
- Typed concerns are invoked AFTER Generic concerns.
- Concern declared to the LEFT are executed BEFORE concerns to the RIGHT.
- Concerns in subclasses are executed BEFORE concerns in super-interfaces.
- Concerns in super-interfaces are executed breadth BEFORE depth.
- Concerns in different super-interfaces at the same "level" are executed with the concerns declared in super-interfaces left of other super-interfaces first. (TODO: Strange explanation)
- Concerns declared in interfaces are executed AFTER concerns declared in Assembly.
A little known feature is the DecoratorMixin, which allows any object to become a Mixin. This is useful when for instance the initialization of the object to act as a Mixin is complex, or maybe an instance is shared across many Composites. This functionality is only relevant in Transients, and therefor not available in other Composite meta types.
This is done by declaring the DecoratorMixin on the interface, and add the object to be used via the use() method on the TransientBuilder.
The DecoratorMixin will optimize the invocation for generic mixins, to avoid additional cost of reflection. But otherwise the DecoratorMixin is fairly simple
Let’s say that we have a model, FooModel, whose implementation is simply a POJO. Several different views shares this the same model instance, so any changes to the model will notify the views.
We start with the FooModel interface;
public interface FooModel
{
String getBar();
void setBar(String value);
[...snip...]
}
and its implementation is not really relevant for this discussion.
Each of the views looks like this;
@Mixins(View1.Mixin.class)
public interface View1
{
String bar();
public class Mixin
implements View1
{
@This
FooModel model;
@Override
public String bar()
{
return model.getBar();
}
}
}
Note that the mixin is expecting to have the FooModel as being part of the view. This also simplies the mixin, which can for instance add and remove listeners to model updates in lifecycle methods.
But we need an implementation of the FooModel that uses the actual implementation of the FooModel. So we decorate the FooModel with the DecoratorMixin.
@Mixins(DecoratorMixin.class) public interface FooModel
The DecoratorMixin expects that the implementation is found among the "@Uses" objects, so to create a view we simply do;
public View1 createView1( FooModel model )
{
TransientBuilder<View1> builder = module.newTransientBuilder( View1.class );
builder.use( model );
return builder.newInstance();
}
And there is nothing special in the assembly of this simple example;
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
module.transients( View1.class );
module.transients( View2.class );
module.transients( FooModel.class );
}
This can now be validated in a small test;
@Test
public void testDecoration()
{
FooModelImpl model = new FooModelImpl( "Init" );
View1 view1 = createView1( model );
View2 view2 = createView2( model );
assertThat( view1.bar(), equalTo( "Init" ) );
assertThat( view2.bar(), equalTo( "Init" ) );
model.setBar( "New Value" );
assertThat( view1.bar(), equalTo( "New Value" ) );
assertThat( view2.bar(), equalTo( "New Value" ) );
}
Composite Types Lookup can occurs when you explicitely lookup for a Composite by Type (ex. ServiceFinder.findService(..) methods), when you ask for an injection or when you create a new composite instance.
All theses type lookup start from a Module, are lazy, cached and obey the Qi4j Visibility rules. Type Lookup works equally accross Composite Types with some subtle differences when it comes to Services and Entities.
When creating or injecting Objects, Transients or Values the Type Lookup does the following:
First, if Object/Transient/Value Models exactly match the given type, the closest one (Visibility then Assembly order) is returned. Multiple exact matches with the same Visibility are forbidden and result in an AmbiguousTypeException.
Second, if Object/Transient/Value Models match a type assignable to the given type, the closest one (Visibility then Assembly order) is returned. Multiple assignable matches with the same Visibility are forbidden and result in an AmbiguousTypeException.
Entity Types Lookup is splitted in two use cases famillies: Creational usecases and Non-Creational usecases.
Creational Entity Types Lookup
This Type Lookup takes place when creating new Entity instances from a UnitOfWork and behave exactly like Object/Transient/Value Types Lookups.
Non-Creational Entity Types Lookup
This Type Lookup takes place when fetching Entities from an EntityStore or writing queries using the Query API. The Type Lookup is different here to allow polymorphic use of Entities and Queries.
First difference is that this Type Lookup returns an ordered collection instead of a single match.
Returned collection contains, in order, Entity Models that:
- exactly match the given type, in Visibility then Assembly order ;
- match a type assignable to the given type, in Visibility then Assembly order.
Multiple exact matches with the same Visibility are forbidden and result in an AmbiguousTypeException.
Multiple assignable matches are allowed to enable polymorphic fetches and queries.
Service Types Lookup works as follow:
Returned collection contains, in order, ServiceReferences that:
- exactly match the given type, in Visibility then Assembly order ;
- match a type assignable to the given type, in Visibility then Assembly order.
Multiple exact matches with the same Visibility are allowed to enable polymorphic lookup/injection.
Multiple assignable matches with the same Visibility are allowed for the very same reason.
The Qi4j platform defines an advanced Metrics SPI to capture runtime metrics of Qi4j’s internals as well be used by application code (via this API) to provide production metrics for operations personnel, ensuring healthy state of the applications.
There are quite a lot of different Metrics components available, which are instantiated via factories. There is one factory for each component type, to allow for additional components to be created in the future without breaking compatibility in the existing implementations.
The MetricsProvider is a standard Qi4j Service and simply acquired via the @Service annotation on a field or constructor argument.
@Service private MetricsProvider provider;
A Gauge is the simplest form of Metric. It is a value that the application sets, which is polled upon request. The application need to provide the implementation of the value() method. Gauges are genericized for type-safe value handling.
A Gauge can represent anything, for instance, thread pool levels, queue sizes and other resource allocations. It is useful to have separate gauges for percentage (%) and absolute numbers of the same resource. Operations are mainly interested in being alerted when threshold are reach as a percentage, as it is otherwise too many numbers to keep track of.
To create a Gauge, you do something like;
final BlockingQueue queue = new LinkedBlockingQueue( 20 );
[...snip...]
MetricsGaugeFactory gaugeFactory = provider.createFactory( MetricsGaugeFactory.class );
MetricsGauge<Integer> gauge = gaugeFactory.registerGauge( getClass(), "Sample Gauge", new MetricsGauge<Integer>()
{
@Override
public Integer value()
{
return queue.size();
}
} );
MetricsCounterFactory counterFactory = provider.createFactory( MetricsCounterFactory.class ); MetricsCounter counter = counterFactory.createCounter( getClass(), "Sample Counter" );
MetricsHistogramFactory histoFactory = provider.createFactory( MetricsHistogramFactory.class ); MetricsHistogram histogram = histoFactory.createHistogram( getClass(), "Sample Histogram" );
MetricsMeterFactory meterFactory = provider.createFactory( MetricsMeterFactory.class ); MetricsMeter meter = meterFactory.createMeter( getClass(), "Sample Meter", "requests", TimeUnit.MINUTES );
Timers capture both the length of some execution as well as rate of calls. They can be used to time method calls, or critical sections, or even HTTP requests duration and similar.
MetricsTimerFactory timerFactory = provider.createFactory( MetricsTimerFactory.class ); MetricsTimer timer = timerFactory.createTimer( getClass(), "Sample Timer", TimeUnit.SECONDS, TimeUnit.HOURS );
MetricsHealthCheckFactory healthFactory = provider.createFactory( MetricsHealthCheckFactory.class );
MetricsHealthCheck healthCheck = healthFactory.registerHealthCheck(
getClass(),
"Sample Healthcheck",
new MetricsHealthCheck()
{
@Override
public Result check()
throws Exception
{
ServiceStatus status = pingMyService();
return new Result( status.isOk(), status.getErrorMessage(), status.getException() );
}
} );
code
docs
tests
Qi4j has a distinct bootstrap phase, also known as the Assembly of an application, where the applications structure is defined programmatically. Once all the layers, modules and all the composite types in each module have been defined the model is instantiated into an application. This enables the entire structure system in Qi4j, where types "belongs" to a module and visibility rules define default behaviors, enforcement of architectural integrity and much more.
The assembly is preceeded by the creation of the Qi4j Runtime. The assembly can be declared fully by defining all modules and layers, and how the layers are sitting on top of each other, OR one can utilize one of the two convenience assemblies, one for a pancake pattern, where all layers are top on each other, or one with a single module in a single layer, useful for small applications, spikes and tests.
During assembly, the application (JVM level) architecture and the application model is defined. You define which layers exist and how they relate to each other. For each layer, you define which modules it contains. And for each module, you define which composites are in it, and what are the visibility rules for each of these composites.
You can also;
- Define default values for properties.
- Add additional interfaces to composites dynamically.
- Add concerns, mixins, constraints and side effects dynamically.
- Set meta information on defined types.
- Import external services to be available as Qi4j services.
- Tag services with markers
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
module.objects( MyObject.class ).visibleIn( Visibility.layer );
}
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
module.transients( MyTransient.class ).visibleIn( Visibility.layer );
}
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
module.values( MyValue.class ).visibleIn( Visibility.layer );
}
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
module.entities( MyEntity.class ).visibleIn( Visibility.layer );
}
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
module.services( MyService.class ).visibleIn( Visibility.layer );
}
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
module.services( MyService.class ).taggedWith( "foo", "bar" );
}
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
module.importedServices( MyService.class ).
importedBy( InstanceImporter.class ).
setMetaInfo( new MyService() );
// OR
module.objects( MyService.class );
module.importedServices( MyService.class ).
importedBy( NewObjectImporter.class );
}
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
module.values( MyValue.class );
MyValue myValueDefaults = module.forMixin( MyValue.class ).declareDefaults();
myValueDefaults.foo().set( "bar" );
module.entities( MyEntity.class );
MyEntity myEntityDefaults = module.forMixin( MyEntity.class ).declareDefaults();
myEntityDefaults.cathedral().set( "bazar" );
}
Many libraries and extensions provides a cookie-cutter Assembler, to simplify the set up of such component. Often these are suitable, but sometimes they won’t fit the application in hand, in which case the source code at least provides information of what is needed for the component to be used.
Assemblers are typically just instantiated and then call the assemble() method with the ModuleAssembly instance, such as;
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
RestServerAssembler assembler = new RestServerAssembler();
assembler.assemble( module );
}
Defining an Entity Store is in principle as simple as defining a ServiceComposite implementing the EntityStore interface. The problem is that most Entity Stores require Service Configuration, and configuration requires an Entity Store. This chicken-and-egg problem is resolved by having an entity store available that does not require any Service Configuration. Many Assemblers for entity store implementations uses the MemoryEntityStore, and effectively leaves the configuration in the properties file where Service Configuration bootstraps from. It is possible to chain this, so that for instance the Neo4J Entity Store uses the Preferences Entity Store for its configuration, and the Preferences Entity Store uses the Memory Entity Store (i.e. the properties file).
The point is that the entity store used for the configuration of the primary entity store used in the application is that it must not be visible to the application itself. Sometimes it is easiest to put a Memory Entity Store in the same module, with Visibility set to module. Sometimes it makes sense to have an additional Configuration layer below the infrastructure layer, which has this setup.
As mentioned above, most entity stores defines a reasonable default Assembler, possibly with some constructor arguments to define certain aspects. An example is the popular JdbmEntityStore, which Assembler can be used like;
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
JdbmEntityStoreAssembler assembler = new JdbmEntityStoreAssembler( Visibility.application );
assembler.assemble( module );
}
Every Qi4j runtime instance consist of One Application, with one or more Layers and one or more Modules in each Layer. So the minimal application is still one layer with one module. This is not recommended other than for testing purposes and really trivial applications.
Let’s take a closer look at how it is put together.
SingletonAssembler assembler = new SingletonAssembler()
{
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
module.services( MyService.class ).identifiedBy( "Foo" );
module.services( MyService.class ).identifiedBy( "Bar" );
module.objects( Stuff.class );
}
};
Module module = assembler.module();
Stuff stuff = module.newObject( Stuff.class );
Once the SingletonAssembler constructor returns, the Qi4j application is up and running.
The SingletonAssembler also makes common system resources available from the bootstrap code, such as Module, UnitOfWorkFactory and others. This is possible since there is only one Module.
There is one case that stands out as a common case, and forms a reasonable middle-ground. It is where each layer sits exactly on top of each other layer, like pancakes. Each layer will only use the layer directly below and only that layer. For this case we have a convenience setup. You create an Assembler[][][], where the outer-most array is each layer, the middle array is the modules in each layer, and the last array is a set of assemblers needed to put the things togather.
Let’s look at an example;
public static void main( String[] args )
throws Exception
{
qi4j = new Energy4Java();
Assembler[][][] assemblers = new Assembler[][][]{
{ // View Layer
{ // Login Module
new LoginAssembler()
// :
},
{ // Main Workbench Module
new MenuAssembler(),
new PerspectivesAssembler(),
new ViewsAssembler()
// :
},
{ // Printing Module
new ReportingAssembler(),
new PdfAssembler()
// :
}
},
{ // Application Layer
{ // Accounting Module
new BookkeepingAssembler(),
new CashFlowAssembler(),
new BalanceSheetAssembler()
// :
},
{ // Inventory Module
new PricingAssembler(),
new ProductAssembler()
// :
}
},
{ // Domain Layer
// :
},
{ // Infrastructure Layer
// :
}
};
ApplicationDescriptor model = newApplication( assemblers );
Application runtime = model.newInstance( qi4j.spi() );
runtime.activate();
}
private static ApplicationDescriptor newApplication( final Assembler[][][] assemblers )
throws AssemblyException
{
return qi4j.newApplicationModel( new ApplicationAssembler()
{
@Override
public ApplicationAssembly assemble( ApplicationAssemblyFactory appFactory )
throws AssemblyException
{
return appFactory.newApplicationAssembly( assemblers );
}
} );
}
Full Assembly means that you have the opportunity to create any layer/module hierarchy that are within the rules of the Qi4j runtime. It requires more support in your code to be useful, and the example below is by no means a recommended way to organize large application assemblies.
In principle, you first start the Qi4j runtime, call newApplication with an ApplicationAssembler instance and call activate() on the returned application. The ApplicationAssembler instance will be called with an ApplicationAssemblyFactory, which is used to create an ApplicationAssembly describing the application structure.
private static Energy4Java qi4j;
private static Application application;
public static void main( String[] args )
throws Exception
{
// Create a Qi4j Runtime
qi4j = new Energy4Java();
application = qi4j.newApplication( new ApplicationAssembler()
{
@Override
public ApplicationAssembly assemble( ApplicationAssemblyFactory appFactory )
throws AssemblyException
{
ApplicationAssembly assembly = appFactory.newApplicationAssembly();
buildAssembly( assembly );
return assembly;
}
} );
// activate the application
application.activate();
}
static void buildAssembly( ApplicationAssembly app ) throws AssemblyException
{
LayerAssembly webLayer = createWebLayer( app );
LayerAssembly domainLayer = createDomainLayer( app );
LayerAssembly persistenceLayer = createInfrastructureLayer( app );
LayerAssembly authLayer = createAuth2Layer( app );
LayerAssembly messagingLayer = createMessagingLayer( app );
webLayer.uses( domainLayer );
domainLayer.uses( authLayer );
domainLayer.uses( persistenceLayer );
domainLayer.uses( messagingLayer );
}
static LayerAssembly createWebLayer( ApplicationAssembly app ) throws AssemblyException
{
LayerAssembly layer = app.layer( "web-layer" );
createCustomerWebModule( layer );
return layer;
}
static LayerAssembly createDomainLayer( ApplicationAssembly app ) throws AssemblyException
{
LayerAssembly layer = app.layer( "domain-layer" );
createCustomerDomainModule( layer );
// :
// :
return layer;
}
static LayerAssembly createInfrastructureLayer( ApplicationAssembly app ) throws AssemblyException
{
LayerAssembly layer = app.layer( "infrastructure-layer" );
createPersistenceModule( layer );
return layer;
}
static LayerAssembly createMessagingLayer( ApplicationAssembly app ) throws AssemblyException
{
LayerAssembly layer = app.layer( "messaging-layer" );
createWebServiceModule( layer );
createMessagingPersistenceModule( layer );
return layer;
}
static LayerAssembly createAuth2Layer( ApplicationAssembly application ) throws AssemblyException
{
LayerAssembly layer = application.layer( "auth2-layer" );
createAuthModule( layer );
return layer;
}
static void createCustomerWebModule( LayerAssembly layer ) throws AssemblyException
{
ModuleAssembly assembly = layer.module( "customer-web-module" );
assembly.transients( CustomerViewComposite.class, CustomerEditComposite.class,
CustomerListViewComposite.class, CustomerSearchComposite.class );
}
static void createCustomerDomainModule( LayerAssembly layer ) throws AssemblyException
{
ModuleAssembly assembly = layer.module( "customer-domain-module" );
assembly.entities( CustomerEntity.class, CountryEntity.class );
assembly.values( AddressValue.class );
}
static void createAuthModule( LayerAssembly layer ) throws AssemblyException
{
ModuleAssembly assembly = layer.module( "auth-module" );
new LdapAuthenticationAssembler().assemble( assembly );
new ThrinkAuthorizationAssembler().assemble( assembly );
new UserTrackingAuditAssembler().assemble( assembly );
}
static void createPersistenceModule( LayerAssembly layer ) throws AssemblyException
{
ModuleAssembly assembly = layer.module( "persistence-module" );
// Someone has created an assembler for the Neo EntityStore
new NeoAssembler( "./neostore" ).assemble( assembly );
}
code
docs
tests
Qi4j comes with classes to help with testing. For general development, only a couple of classes are of interest as the others are mostly for EntityStore and Index/Query SPI implementations. There is also some mocking support, to allow some of Qi4j’s unique aspects to be mocked, but since Qi4j is so flexible at a fine-granular level, we have found that mocking is seldom, if ever, needed.
In most cases, you will probably use the AbstractQi4jTest class to simplify starting a Qi4j test instance.
public class HelloTest extends AbstractQi4jTest
{
[...snip...]
}
This will do all the initialization of a Qi4j runtime instance and create a single layer with a single module in it. What goes into that module is declared in the assembly() method;
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
module.values( Hello.class );
}
In this case we declare that we have a ValueComposite of type org.qi4j.tutorials.hello.Hello which looks like
/**
* This Composite interface declares a simple "Hello World" interface with a single say() method. What is being
* said is defined in the HelloWorldState interface, which is a private mixin.
* <p/>
*/
@Mixins( { Hello.HelloWorldMixin.class } )
public interface Hello
{
String say();
/**
* This is the implementation of the say() method.
*/
public abstract class HelloWorldMixin
implements Hello
{
// @This reference the composite itself, and since HelloWorldState is not part of the public interface,
// it is a private mixin.
@This
private State state;
@Override
public String say()
{
return state.phrase().get() + " " + state.name().get();
}
}
/**
* This interface contains only the state of the HelloWorld object.
*/
public interface State
{
@NotEmpty
@UseDefaults
Property<String> phrase();
@NotEmpty
@UseDefaults
Property<String> name();
}
}
The say() method will get the phrase and name from its internal state (the State interface is not magical, it could be named anything).
And then we create the actual test;
@Test
public void givenHelloValueInitializedToHelloWorldWhenCallingSayExpectHelloWorld()
{
ValueBuilder<Hello> builder = module.newValueBuilder( Hello.class );
builder.prototypeFor( Hello.State.class ).phrase().set( "Hello" );
builder.prototypeFor( Hello.State.class ).name().set( "World" );
Hello underTest = builder.newInstance();
String result = underTest.say();
assertThat( result, equalTo( "Hello World" ) );
}
By using the prototypeFor() we can access the hidden, internal and very private state of the ValueComposite. Once the value is created we can reach this directly.
code
docs
tests
The Qi4j Core Functional API is a generic package to work with Iterables in a "functional programming language" style.
This package is completely independent of everything else in Qi4j and may be used on its own in any kind of environment such as Spring or Java EE applications.
Let’s say that you have an Iterable of Integers and you want to sum them all up. Most people would create a loop and sum it all up in something like this;
Iterable<Long> data = new ArrayList<Long>();
[...snip...]
long sum = 0;
for( Long point : data )
{
sum = sum + point;
}
System.out.println( "The sum is " + sum );
With the Qi4j Core Functional API, you go about it in a different way. The code ends up looking like this;
import static org.qi4j.functional.ForEach.forEach;
import static org.qi4j.functional.Functions.longSum;
[...snip...]
Iterable<Number> data = new ArrayList<Number>();
Long sum = forEach( data ).map( longSum() ).last();
System.out.println( "The sum is " + sum );
And this is just the tip of the iceberg.
The Qi4j Core Functional API are divided a handful of powerful concepts, especially when used together;
- Iterables - many methods to deal with Iterable data, so that the loops in your programs can largely be removed.
- Functions - f(x) and f(x,y) are well-know from mathematics and used in functional programming languages. Qi4j is not capable of introducing lambda calculus due to limitations in Java itself, but we can simulate a lot to allow people to create more readable code.
- Specification - A simple concept to define the bounds of data. This is used for filtering, query and many other higher level abstractions.
- Visitor pattern - A way to be handed the items in a collection, without having the loops. This could be for end result handling, distribution of intermediary values, and many other things.
TODO
TODO
TODO
TODO
code
docs
tests
The Qi4j Core I/O API is completely generic and not tied to the Qi4j programming model as a whole. It can be used independently of Qi4j, together with the Qi4j Core Functional API, which the Core I/O API depends on.
The Qi4j Core I/O API tries to address the problem around shuffling data around from various I/O inputs and outputs, possibly with transformations and filtering along the way. It was identified that there is a general mix-up of concerns in the stereotypical I/O handling codebases that people deal with all the time. The reasoning around this, can be found in the Use I/O API, and is recommended reading.
Why does I/O operations in Java have to be so complicated, with nested try/catch/finally and loops? Don’t you wish that the operations could be expressed in a more natural way, such as;
File source = ... File destination = ... source.copyTo( destination );
It seems natural to do, yet it is not present for us. We need to involve FileInputStream/FileOutputStream, wrap them in Buffered versions of it, do our own looping, close the streams afterwards and what not. So, the java.io.File does not have this simple feature and in the Qi4j Core API, we need to work around this limitation. We also want to make the abstraction a little bit more encompassing than "just" files. So how does that look like then?
The most common inputs and outputs are collected in the org.qi4j.io.Inputs and org.qi4j.io.Outputs classes as static factory methods, but you can create your (more about that later).
So, we want to read a text file and write the content into another text file, right? This is how it is done;
File source = new File( "source.txt" ); File destination = new File( "destination.txt" ); Inputs.text( source ).transferTo( Outputs.text( destination ) );
Pretty much self-explanatory, wouldn’t you say? But what happened to the handling of exceptions and closing of resources? It is all handled inside the Qi4j Core I/O API. There is nothing you can forget to do.
Another simple example, where we want to count the number of lines in the text;
import org.qi4j.io.Transforms.Counter;
import static org.qi4j.io.Transforms.map;
[...snip...]
File source = new File( "source.txt" );
File destination = new File( "destination.txt" );
Counter<String> counter = new Counter<String>();
Inputs.text( source ).transferTo( map(counter, Outputs.text(destination) ));
System.out.println( "Lines: " + counter.count() );
The Counter is a Function which gets injected into the transfer.
Ok, so we have seen that the end result can become pretty compelling. How does it work?
I/O is defined as a process of moving data from an Input, via one or more Transforms to an Output. The Input could be a File or a String, the transformation could be a filter, conversion or a function and finally the Output destination could be a File, String or an OutputStream. It is important to note that there is a strong separation of concern between them. Let’s look at the on at a time.
This interface simply has a transferTo() method, which takes an Output. The formal definition is;
public interface Input<T, SenderThrowableType extends Throwable>
{
<ReceiverThrowableType extends Throwable> void transferTo( Output<? super T, ReceiverThrowableType> output )
throws SenderThrowableType, ReceiverThrowableType;
}
What on earth is all this genericized Exceptions? Well, it abstracts away the explicit Exception that implementations may throw (or not). So instead of demanding that all I/O must throw the java.io.IOException, as is the case in the JDK classes, it is up to the implementation to declare what it may throw. That is found in the SenderThrowable generic of the interface.
But hold on a second. Why is an Input throwing a "sender" exception? Well, think again. The Input is feeding "something" with data. It takes it from some source and "sends it" to the downstream chain, eventually reaching an Output, which likewise is the ultimate "receiver".
So, then, the method transferTo() contains the declaration of the downstream receiver’s possible Exception (ReceiverThrowable) which the transferTo() method may also throw as the data may not be accepted and such exception will bubble up to the transferTo() method (the client’s view of the transfer).
The output interface is likewise fairly simple;
public interface Output<T, ReceiverThrowableType extends Throwable>
{
[...snip...]
<SenderThrowableType extends Throwable> void receiveFrom( Sender<? extends T, SenderThrowableType> sender )
throws ReceiverThrowableType, SenderThrowableType;
}
It can simply receive data from a org.qi4j.io.Sender.
Hey, hold on! Why is it not receiving from an Input? Because the Input is the client’s entry point and of no use to the Output as such. Instead, the Output will tell the Sender (which is handed to from the Input or an transformation) to which Receiver the content should be sent to.
Complicated? Perhaps not trivial to get your head around it at first, but the chain is;
Input passes a Sender to the Output which tells the Sender which Receiver the data should be sent to.
The reason for this is that we need to separate the concerns properly. Input is a starting point, but it emits something which is represented by the Sender. Likewise the destination is an Output, but it receives the data via its Receiver interface. For O/S resources, they are handled purely inside the Input and Output implementations, where are the Sender/Receiver are effectively dealing with the data itself.
The 3 component in the Qi4j Core I/O API is the transformations that are possible. Interestingly enough, with the above separation of concerns, we don’t need an InputOutput type that can both receive and send data. Instead, we simply need to prepare easy to use static factory methods, which are found in the org.qi4j.io.Transforms class. Again, it is fairly straight forward to create your own Transforms if you need something not provided here.
The current transformations available are;
- filter - takes a Specification and only forwards data items conforming to the Specification.
- map - takes a org.qi4j.functional.Function to convert an item from one type to (potentially) another, and any possible change along the way.
- filteredMap - is a combination of a filter and a map. If the Specification is satisfied, the map function is applied, otherwise the item is passed through unaffected.
- lock - A wrapper which protects the Input or Output from simultaneous access. Not a transformation by itself, but implemented in the same fashion.
There are also a couple of handy map functions available, such as
- Log
- ProgressLog
- Counter
- ByteBuffer2String
- Object2String
- String2Bytes
Let us take a closer look at the implementation of a map function, namely Counter mentioned above and also used in the section First Example above.
The implementation is very straight forward.
public static class Counter<T>
implements Function<T, T>
{
private volatile long count = 0;
public long count()
{
return count;
}
@Override
public T map( T t )
{
count++;
return t;
}
}
On each call to the map() method, increment the counter field. The client can then retrieve that value after the transfer is complete, or in a separate thread to show progress.
Speaking of "progress", so how is the ProgressLog implemented? Glad you asked;
public static class ProgressLog<T>
implements Function<T, T>
{
private Counter<T> counter;
private Log<String> log;
private final long interval;
public ProgressLog( Logger logger, String format, long interval )
{
this.interval = interval;
if( logger != null && format != null )
{
log = new Log<String>( logger, format );
}
counter = new Counter<T>();
}
public ProgressLog( long interval )
{
this.interval = interval;
counter = new Counter<T>();
}
@Override
public T map( T t )
{
counter.map( t );
if( counter.count % interval == 0 )
{
logProgress();
}
return t;
}
// Override this to do something other than logging the progress
protected void logProgress()
{
if( log != null )
{
log.map( counter.count + "" );
}
}
}
It combines the Counter and the Log implementations, so that the count is forwarded to the Log at a given interval, such as every 1000 items. This may not be what you think a ProgressLog should look like, but it serves as a good example on how you can combine the general principles found in the Qi4j Core API package.
The filter transform takes a specification implementation which has a very simple method, isSatisfiedBy() (read more about that in Function.
public interface Specification<T>
{
[...snip...]
boolean satisfiedBy( T item );
}
The only thing that the implementation need to do is return true or false for whether the item passed in is within the limits of the Specification. Let’s say that you have a IntegerRangeSpecification, which could then be implemented as
public static class IntegerRangeSpecification
implements Specification<Integer>
{
private int lower;
private int higher;
public IntegerRangeSpecification( int lower, int higher )
{
this.lower = lower;
this.higher = higher;
}
@Override
public boolean satisfiedBy( Integer item )
{
return item >= lower && item <= higher;
}
}
Input and Output implementations at first glance look quite scary. Taking a closer look and it can be followed. But to simplify for users, the org.qi4j.io.Inputs and org.qi4h.io.Outputs contains static factory methods for many useful sources and destinations.
The current set of ready-to-use Input implementations are;
/**
* Read lines from a String.
*
* @param source lines
*
* @return Input that provides lines from the string as strings
*/
public static Input<String, RuntimeException> text( final String source )
[...snip...]
/**
* Read lines from a Reader.
*
* @param source lines
*
* @return Input that provides lines from the string as strings
*/
public static Input<String, RuntimeException> text( final Reader source )
[...snip...]
/**
* Read lines from a UTF-8 encoded textfile.
*
* If the filename ends with .gz, then the data is automatically unzipped when read.
*
* @param source textfile with lines separated by \n character
*
* @return Input that provides lines from the textfiles as strings
*/
public static Input<String, IOException> text( final File source )
[...snip...]
/**
* Read lines from a textfile with the given encoding.
*
* If the filename ends with .gz, then the data is automatically unzipped when read.
*
* @param source textfile with lines separated by \n character
* @param encoding encoding of file, e.g. "UTF-8"
*
* @return Input that provides lines from the textfiles as strings
*/
public static Input<String, IOException> text( final File source, final String encoding )
[...snip...]
/**
* Read lines from a textfile at a given URL.
*
* If the content support gzip encoding, then the data is automatically unzipped when read.
*
* The charset in the content-type of the URL will be used for parsing. Default is UTF-8.
*
* @param source textfile with lines separated by \n character
*
* @return Input that provides lines from the textfiles as strings
*/
public static Input<String, IOException> text( final URL source )
[...snip...]
/**
* Read a file using ByteBuffer of a given size. Useful for transferring raw data.
*
* @param source
* @param bufferSize
*
* @return
*/
public static Input<ByteBuffer, IOException> byteBuffer( final File source, final int bufferSize )
[...snip...]
/**
* Read an inputstream using ByteBuffer of a given size.
*
* @param source
* @param bufferSize
*
* @return
*/
public static Input<ByteBuffer, IOException> byteBuffer( final InputStream source, final int bufferSize )
[...snip...]
/**
* Combine many Input into one single Input. When a transfer is initiated from it all items from all inputs will be transferred
* to the given Output.
*
* @param inputs
* @param <T>
* @param <SenderThrowableType>
*
* @return
*/
public static <T, SenderThrowableType extends Throwable> Input<T, SenderThrowableType> combine( final Iterable<Input<T, SenderThrowableType>> inputs )
[...snip...]
/**
* Create an Input that takes its items from the given Iterable.
*
* @param iterable
* @param <T>
*
* @return
*/
public static <T> Input<T, RuntimeException> iterable( final Iterable<T> iterable )
[...snip...]
/**
* Create an Input that allows a Visitor to write to an OutputStream. The stream is a BufferedOutputStream, so when enough
* data has been gathered it will send this in chunks of the given size to the Output it is transferred to. The Visitor does not have to call
* close() on the OutputStream, but should ensure that any wrapper streams or writers are flushed so that all data is sent.
*
* @param outputVisitor
* @param bufferSize
*
* @return
*/
public static Input<ByteBuffer, IOException> output( final Visitor<OutputStream, IOException> outputVisitor,
final int bufferSize
)
The current set of ready-to-use Input implementations are;
/**
* Write lines to a text file with UTF-8 encoding. Separate each line with a newline ("\n" character). If the writing or sending fails,
* the file is deleted.
* <p/>
* If the filename ends with .gz, then the data is automatically GZipped.
*
* @param file the file to save the text to
*
* @return an Output for storing text in a file
*/
public static Output<String, IOException> text( final File file )
[...snip...]
/**
* Write lines to a text file. Separate each line with a newline ("\n" character). If the writing or sending fails,
* the file is deleted.
* <p/>
* If the filename ends with .gz, then the data is automatically GZipped.
*
* @param file the file to save the text to
*
* @return an Output for storing text in a file
*/
public static Output<String, IOException> text( final File file, final String encoding )
[...snip...]
/**
* Write lines to a Writer. Separate each line with a newline ("\n" character).
*
* @param writer the Writer to write the text to
* @return an Output for storing text in a Writer
*/
public static Output<String, IOException> text( final Writer writer )
[...snip...]
/**
* Write lines to a StringBuilder. Separate each line with a newline ("\n" character).
*
* @param builder the StringBuilder to append the text to
* @return an Output for storing text in a StringBuilder
*/
public static Output<String, IOException> text( final StringBuilder builder )
[...snip...]
/**
* Write ByteBuffer data to a file. If the writing or sending of data fails the file will be deleted.
*
* @param file
* @param <T>
*
* @return
*/
public static <T> Output<ByteBuffer, IOException> byteBuffer( final File file )
[...snip...]
/**
* Write ByteBuffer data to an OutputStream.
*
* @param stream
* @param <T>
*
* @return
*/
public static <T> Output<ByteBuffer, IOException> byteBuffer( final OutputStream stream )
[...snip...]
/**
* Write byte array data to a file. If the writing or sending of data fails the file will be deleted.
*
* @param file
* @param bufferSize
* @param <T>
*
* @return
*/
public static <T> Output<byte[], IOException> bytes( final File file, final int bufferSize )
[...snip...]
/**
* Do nothing. Use this if you have all logic in filters and/or specifications
*
* @param <T>
*
* @return
*/
public static <T> Output<T, RuntimeException> noop()
[...snip...]
/**
* Use given receiver as Output. Use this if there is no need to create a "transaction" for each transfer, and no need
* to do batch writes or similar.
*
* @param <T>
* @param receiver receiver for this Output
*
* @return
*/
public static <T, ReceiverThrowableType extends Throwable> Output<T, ReceiverThrowableType> withReceiver( final Receiver<T, ReceiverThrowableType> receiver )
[...snip...]
/**
* Write objects to System.out.println.
*
* @return
*/
public static Output<Object, RuntimeException> systemOut()
[...snip...]
/**
* Write objects to System.err.println.
*/
public static Output<Object, RuntimeException> systemErr()
[...snip...]
/**
* Add items to a collection
*/
public static <T> Output<T, RuntimeException> collection( final Collection<T> collection )
code
docs
tests
The Qi4j Core Runtime has a number of extension points, which we call the Qi4j Core Extension SPI. These are defined interfaces used only by the Core Runtime and never directly by application code. Extensions are assembled in applications during the bootstrap phase.
There are currently 5 Core SPI extensions;
Qi4j Runtime Extensions implementations may depend on Qi4j Libraries, but Libraries are NOT ALLOWED to depend on Extensions. Applications code is NOT ALLOWED to depend on extensions. And application code SHOULD NOT depend on the Core Extension SPI. If you think that is needed, please contact qi4j-dev forum at Google Groups, to see if your usecase can be solved in a support manner, or that we need to extend the Core API to support it.
The Qi4j Core Runtime use ValueSerialization to provide string representation of ValueComposites via their toString()
method, and, their instanciation from the very same representation via the newValueFromSerializedState(..) method of
the ValueBuilderFactory API.
If no ValueSerialization service is visible, a default implementation supporting the JSON format used but note that it won’t be available as a Service. So, in order to use the full ValueSerialization API a ValueSerialization service must be explicitely assembled in the Application. See the Extensions documentation for details.
Simply implement ValueSerialization to create an extension for the ValueSerialization SPI. The Core SPI module provides adapters to create pull-parsing capable ValueSerializers and pull-parsing and tree-parsing capable ValueDeserializers.
The behaviour described here apply to all ValueSerialization services implemented using the Core SPI adapters. Note that nothing stops you from implementing an extension for the ValueSerialization SPI without relying on theses adapters.
Theses adapters are tailored for serialization mechanisms that support the following two structures that can be nested:
- a collection of name/value pairs. In various languages, this is realized as an object, record, struct, dictionary, hash table, keyed list, or associative array,
- an ordered list of values. In most languages, this is realized as an array, vector, list, or sequence ;
in other words, a JSON-like structure.
Special attention is taken when dealing with Maps. They are serialized as an ordered list of collections of name/value pairs to keep the Map order for least surprise. That way, even when the underlying serialization mechanism do not keep the collection of name/value pairs order we can rely on it being kept.
Here is a sample Map with two entries in JSON notation to make things clear:
[
{ "key": "foo", "value": "bar" },
{ "key": "cathedral", "value": "bazar" }
]Among Plain Values (see the ValueSerialization API section) some are considered primitives to underlying serialization mechanisms and by so handed/come without conversion to/from implementations.
Primitive values can be one of:
- String,
- Boolean or boolean,
- Integer or int,
- Long or long,
- Short or short,
- Byte or byte,
- Float or float,
- Double or double.
Serialization is always done in a streaming manner using a pull-parsing based approach.
Deserialization is done in a streaming manner using a pull-parsing based approach except when encountering a ValueComposite. ValueComposite types are deserialized using a tree-parsing based approach.
All this means that you can serialize and deserialize large collections of values without filling the heap.
| Note | |
|---|---|
This SPI has no documentation yet. Learn how to contribute in Writing Documentation. |
| Note | |
|---|---|
This SPI has no documentation yet. Learn how to contribute in Writing Documentation. |
| Note | |
|---|---|
This SPI has no documentation yet. Learn how to contribute in Writing Documentation. |
It is very easy to create an extension for the Metrics SPI, simply by implementing the MetricsProvider. If only a subset of the factories/types are supported, there is a convenience adapter call MetricsProviderAdapter in the Metrics SPI package.
code
docs
tests
First of all, your code should never, ever, have a dependency on Core Runtime. If you think you need this, you should probably contact qi4j-dev forum at Google Groups and see if your usecase can either be solved in a existing way or perhaps that a new Core SPI Extension is needed.
Let’s repeat that; Never, never, ever depend on Core Runtime. Make sure that the compile dependency does NOT include
the org.qi4j.core.runtime jar.
- 7.1. Overview
- 7.2. Alarms
- 7.3. Caching
- 7.4. Circuit Breaker
- 7.5. Constraints
- 7.6. Conversion
- 7.7. CXF WebService
- 7.8. Event Sourcing
- 7.9. Event Sourcing - JDBM
- 7.10. Event Sourcing - ReST
- 7.11. FileConfig
- 7.12. HTTP
- 7.13. JMX
- 7.14. Locking
- 7.15. Logging
- 7.16. Neo4j
- 7.17. OSGi
- 7.18. RDF
- 7.19. ReST Client
- 7.20. ReST - HATEOAS Primer
- 7.21. ReST Common
- 7.22. ReST Server
- 7.23. Scheduler
- 7.24. Beanshell Scripting
- 7.25. Groovy Scripting
- 7.26. Javascript Scripting
- 7.27. JRuby Scripting
- 7.28. Scala Support
- 7.29. Servlet
- 7.30. Shiro Security
- 7.31. Shiro Web Security
- 7.32. Spring Integration
- 7.33. SQL
- 7.34. Struts - Code Behind
- 7.35. Struts - Convention
- 7.36. Struts - Plugin
- 7.37. UID
- 7.38. UoWFile
The Qi4j Libraries are of varying maturity level and we try to maintain a STATUS (dev-status.xml) file indicating how good the codebase, documentation and unit tests are for each of the libraries. This is highly subjective and potentially different individuals will judge this differently, but at least it gives a ballpark idea of the situation for our users.
code
docs
tests
The process control and industrial automation industry has for decades been struggling with a large number of unreliable data points, such as sensors, fuses and potentially malfunctioning valves and actuators. This industry quickly developed the concept of Alarm Point as an abstraction for indication that something is not working correctly. These Alarm Points could then be grouped and aggregated, along a well-defined set of rules, to provide human operators a clear view of what is going on in a plant.
The enterprise software has always assumed a much more "reliable" environment where the computers either work or they don’t. Very little thought has been spent on what happens when many independent systems interact and what the consequences are to other systems when one fails. The Alarm Point concepts becomes a natural fit for the enterprise world of today, where Alarm Points allows for fine-grained notification and view into the health of one or more systems.
In Qi4j, we are building upon this powerful abstraction, from decades of field experience.
An Alarm Point is of an Alarm Class and of an Alarm Category. The Alarm Class defines the severity of the Alarm Point and the Alarm Category defines which part of the system it belongs to. Alarm Category can be extended by the developer, and the package contains the SimpleAlarmCategory as an example, where a Description property has been added.
An Alarm Point also has a System Name, which should be the subsystem or application name.
Alarm Points are triggered and an Alarm Trigger may cause the Alarm Status to change. IF, and only if, the Alarm Status changes, and Alarm Event is generated. The Alarm Model used for an Alarm Point defines which Alarm Status, Alarm Trigger and Alarm Event that are possible.
Alarm Points may also have user-defined properties. These are primarily used for reporting and auditing.
The Alarm Point is the central API for applications. Alarm Points are entities and normally dormant on in the Entity Store. The Alarm Point is a small workflow state-machine, and the Alarm Model associated with the Alarm Point defines the workflow.
Sometimes it is much more convenient to hold on to Alarm Points all the time, instead of reviving them from the Entity Store every time they are to be modified. Therefor, there is a convenience class available who does all the grunt work, called the Alarm Proxy. By creating an Alarm Proxy, all the UnitOfWork handling is done for you. You still need to provide an Identity of the Alarm, which must survive restarts. The code could look something like this;
@Service
private AlarmProxy.Factory factory;
private AlarmProxy myAlarmPoint;
[...snip...]
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
new AlarmSystemAssembler().assemble( module );
[...snip...]
myAlarmPoint = factory.create( "This Alarm Identity", "ProActiveCRM", "Sales", AlarmClass.B );
myAlarmPoint.history().maxSize().set( 20 );
[...snip...]
myAlarmPoint.activate();
The Qi4j Alarm library comes with 3 Alarm Models which should be sufficient for most uses. These are based on decades of experience from the industrial automation industry and user feedback.
The Simple Alarm Model is the most basic one, with only two Alarm Status, Normal and Activated. The only Alarm Triggers are activate and deactivate, where activate on a Normal status will bring it to Activated status and an Activated Alarm Event is generated.
| Old Status | Trigger | Event | New Status |
|---|
code
docs
tests
Caching Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
The Circuit Breaker library provides a way to guard your application against faulty external systems (e.g. mail servers being down, web services being down). It is used by many Qi4j Extensions and Libraries.
There’s a couple of differences between this implementation and others seen on the net, but we’ve also heavily borrowed from others. The first difference is that we’ve not focused on performance at all. For some reason other implementations make a point about doing "atomic changes" with various tricks, to ensure good performance. Since this is used to guard access to external systems, where latencies range in milliseconds and up, that seems completely useless, so we’ve just put "synchronized" on all methods, which should be safe. "It works" is better than "it’s fast" for these types of things.
Second, other implementations have had really crude logic for what types
of exceptions cause the circuit to break. The most crude is "all", more
advanced ones allow exceptions that be excepted to be registered, but in
real cases this is not enough. Case in point is JDBC exceptions where
you want to fail on "connect exception" but not necessarily "invalid SQL
syntax". So instead we’ve leveraged Specification from Core Functional API where
you get to provide your own specification that can use any logic to
determine whether a particular exception is ok or not.
Third, there’s a big focus on manageability through JMX. A circuitbreaker can be easily exposed in JMX as an MBean, where you can track service levels and see exception messages, and trip/enable circuit breakers.
Fourth, if an external system is unavailable due to a circuitbreaker tripping it should be possible to expose this to other Qi4j services. There is a standard implementation of the Availability interface that delegates to a circuit breaker and the Enabled configuration flag, which is what we’d suspect will be used in most cases where external systems are invoked.
The CircuitBreaker can be used directly, even without using anything else from the Qi4j SDK.
Here is a code snippet that demonstrate how to create a CircuitBreaker and how it behave:
// Create a CircuitBreaker with a threshold of 3, a 250ms timeout, allowing IllegalArgumentExceptions CircuitBreaker cb = new CircuitBreaker( 3, 250, CircuitBreakers.in( IllegalArgumentException.class ) ); [...snip...] // Service levels goes down but does not cause a trip cb.throwable( new IOException() ); [...snip...] // Service level goes down and causes a trip cb.throwable( new IOException() ); cb.throwable( new IOException() ); [...snip...] // Turn on the CB again cb.turnOn(); [...snip...] // Service levels goes down and causes a trip cb.throwable( new IOException() ); cb.throwable( new IOException() ); cb.throwable( new IOException() ); [...snip...] // Wait until timeout [...snip...] // CircuitBreaker is back on
As a facility you can make your Services extends AbstractBreakOnThrowable, set them a CircuitBreaker as
MetaInfo during assembly and annotate methods with @BreaksCircuitOnThrowable. Doing this will :
-
add a circuit breaker accessor to the Service (
CircuitBreaker getCircuitBreaker()) ; - allow exposition of the circuit breaker in JMX ;
-
update the circuit breaker on annotated methods invocation success and thrown exceptions using the
BreakCircuitConcern.
Here is how to declare such a Service:
public void assemble( ModuleAssembly module )
throws AssemblyException
{
module.services( TestService.class ).setMetaInfo( new CircuitBreaker() );
}
[...snip...]
public interface TestService
extends AbstractBreakOnThrowable, ServiceComposite
{
@BreaksCircuitOnThrowable
int successfulMethod();
@BreaksCircuitOnThrowable
void throwingMethod();
[...snip...]
}
Remember to annotate methods which when they throw throwables should cause circuit breakers to trip and go back on
invocation success with the @BreaksCircuitOnThrowable annotation.
To expose their circuit breaker in JMX, your Services using one must implement the ServiceCircuitBreaker interface.
Note that if you already extends AbstractBreakOnThrowable you don’t need to do anything else as it already extends
ServiceCircuitBreaker.
Here is how it goes:
Traceback (most recent call last):
File "/home/eskatos/.asciidoc/filters/snippet/snippet.py", line 86, in <module>
for line in snippet(**configuration(indata)):
File "/home/eskatos/.asciidoc/filters/snippet/snippet.py", line 37, in snippet
sourceFile = open(PATH_PATTERN % locals())
IOError: [Errno 2] No such file or directory: 'libraries/circuitbreaker/src/test/java/org/qi4j/library/circuitbreaker/jmx/CircuitBreakerManagementTest.java'
A gradle task runSample is defined in this library as a shortcut to run a simple interactive example. You’ll need a MBean client to connect to the sample, VisualVM with its MBean plugin does the job. See Build System if you need some guidance.
code
docs
tests
The Constraints library provide a bunch of often used Constraints based on the Qi4j Constraints api described in Constraint.
Remember that you are not limited to constraints presents in this library, you are encouraged to write your own constraints. See Create a Constraint or take a look at this library source code to learn how to write your own.
You can use theses constraints on Properties or on method arguments. Here are some examples:
@Contains( "foo" ) Property<String> containsString();
@Email Property<String> email();
@URL Property<String> url();
@URI Property<String> uri();
@GreaterThan( 10 ) Property<Integer> greaterThan();
@InstanceOf( List.class ) Property<Collection> instanceOf();
@LessThan( 10 ) Property<Integer> lessThan();
@Matches( "a*b*c*" ) Property<String> matches();
@MaxLength( 3 ) Property<String> maxLength();
@MinLength( 3 ) Property<String> minLength();
@NotEmpty Property<String> notEmptyString();
@NotEmpty Property<Collection> notEmptyCollection();
@NotEmpty Property<List> notEmptyList();
@Range( min = 0, max = 100 ) Property<Integer> range();
@OneOf( { "Bar", "Xyzzy" } ) Property<String> oneOf();
void testParameters(@GreaterThan(10) Integer greaterThan);
code
docs
tests
The Conversion Library provides support for converting composite types.
To convert Entities to Values, use the EntityToValueService. It is easily assembled:
module.services( EntityToValueService.class );
Let’s say we have an interface defining state:
public interface PersonState
{
Property<String> firstName();
Property<String> lastName();
Property<Date> dateOfBirth();
}
An EntityComposite using the state as a Private Mixin:
@Mixins( PersonMixin.class )
public interface PersonEntity
extends EntityComposite
{
String firstName();
String lastName();
Integer age();
@Optional
Association<PersonEntity> spouse();
ManyAssociation<PersonEntity> children();
}
[...snip...]
public static abstract class PersonMixin
implements PersonEntity
{
@This
private PersonState state;
[...snip...]
}
And a ValueComposite extending this very same state;
public interface PersonValue
extends PersonState, ValueComposite
{
@Optional
Property<String> spouse();
@Optional
Property<List<String>> children();
}
Here is how to convert an EntityComposite to a ValueComposite:
EntityToValueService conversion = module.findService( EntityToValueService.class ).get(); PersonValue value = conversion.convert( PersonValue.class, entity );
Associations are converted to Identity strings.
If your Entities and Values cannot use the same state type, you can annotate the Value that is the target of the
conversion with the @Unqualified annotation. Then, the lookup of the Value Property will be performed using the
unqualified name only, and not via the default of the full qualified name. In other words, this means that the
Property may be declared in the different interfaces and still be matched.
Here is an example:
@Unqualified
public interface PersonValue2
extends ValueComposite
{
Property<String> firstName();
Property<String> lastName();
Property<Date> dateOfBirth();
@Optional
Property<String> spouse();
@Optional
Property<List<String>> children();
}
code
docs
tests
CXF WebService Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
Event Sourcing Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
Event Sourcing - JDBM Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
Event Sourcing - ReST Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
The FileConfig library provide a service for accessing application-specific directories.
A lot of the Qi4j Libraries and Extensions make use of this library to locate files.
public interface FileConfiguration
{
[...snip...]
File configurationDirectory();
File dataDirectory();
File temporaryDirectory();
File cacheDirectory();
File logDirectory();
}
To use it you simply need to declare the FileConfiguration Service in your application assembly:
module.services( FileConfigurationService.class );
These will default to the platform settings, but can be overridden manually, either one-by-one or as a whole.
You can override defaults by adding org.qi4j.library.fileconfig.FileConfiguration_OS.properties files to your classpath where OS is one of win, mac or unix.
You can also override all properties definitions at assembly time by setting a FileConfigurationOverride object as meta info of this service:
FileConfigurationOverride override = new FileConfigurationOverride().
withConfiguration( confDir ).
withData( dataDir ).
withTemporary( tempDir ).
withCache( cacheDir ).
withLog( logDir );
module.services( FileConfigurationService.class ).setMetaInfo( override );
And finally, to get the FileConfiguration Service in your application code, simply use the following:
@Service FileConfiguration fileconfig;
code
docs
tests
The HTTP library provides a Jetty based embedded HTTP service with support for easy event listeners, servlets and filters assembly as Services.
It’s an easy way to embedd a servlet container and reuse everything that can be run in it (JAX-*, Restlet, Wicket, Vaadin, GWT etc..). If instead you want to run a Qi4j Application in a servlet container, see Servlet Library.
EventListeners in HttpService are assembled as Services, so one have to declare a ServiceComposite like this:
@Mixins( FooServletContextListener.class )
public interface FooServletContextListenerService
extends ServletContextListener, ServiceComposite
{
}
Servlets in HttpService are assembled as Services, so one have to declare a ServiceComposite like this:
@Mixins( HelloWorldServlet.class )
public interface HelloWorldServletService
extends Servlet, ServiceComposite
{
}
It’s the same for Filters. As an example here is the bundled UnitOfWorkFilterService declaration:
@Mixins( UnitOfWorkFilter.class )
public interface UnitOfWorkFilterService extends Filter, ServiceComposite
{
}
The HTTP library provide a JettyServiceAssembler and a fluent API to easily assemble Servlets and Filters.
// Assemble the JettyService new JettyServiceAssembler().assemble( module ); // Set HTTP port as JettyConfiguration default JettyConfiguration config = module.forMixin( JettyConfiguration.class ).declareDefaults(); config.hostName().set( "127.0.0.1" ); config.port().set( HTTP_PORT ); // Serve /helloWorld with HelloWorldServletService addServlets( serve( "/helloWorld" ).with( HelloWorldServletService.class ) ).to( module ); // Filter requests on /* through provided UnitOfWorkFilterService addFilters( filter( "/*" ).through( UnitOfWorkFilterService.class ).on( REQUEST ) ).to( module );
This library can be used alonside the JMX library, described in JMX Library. If it is visible and that you enable Jetty statistics configuration property they will be automatically exposed through JMX.
Here is a simple example from the unit tests showing what’s necessary but inside a simple Module for the sake of clarity:
new JettyServiceAssembler().assemble( module ); new JMXAssembler().assemble( module ); // Assemble both JettyService and JMX JettyConfiguration config = module.forMixin( JettyConfiguration.class ).declareDefaults(); config.hostName().set( "127.0.0.1" ); config.port().set( 8441 ); config.statistics().set( Boolean.TRUE ); // Set statistics default to TRUE in configuration // Hello world servlet related assembly addServlets( serve( "/hello" ).with( HelloWorldServletService.class ) ).to( module );
Underlying Jetty engine configuration is exposed as a Qi4j Service Configuration. The only one that is mandatory is the port.
See org.qi4j.library.http.JettyConfiguration for a reference of all available configuration properties.
The HTTP library provides a second HttpService that brings SSL support.
Simply change from JettyServiceAssembler to SecureJettyServiceAssembler:
new SecureJettyServiceAssembler().assemble( module ); [...snip...] addServlets( serve( "/hello" ).with( HelloWorldServletService.class ) ).to( module ); addFilters( filter( "/*" ).through( UnitOfWorkFilterService.class ).on( REQUEST ) ).to( module );
You must at least configure a KeyStore using the three related properties. All the other ones have sensible defaults.
If you want, or need, to do client certificate authentication you’ll need to configure at least a "trust store", a KeyStore that contains your trusted trust anchors.
Here is some code that set HTTP port a well as a KeyStore and a TrustStore as SecureJettyConfiguration default during assembly:
SecureJettyConfiguration config = module.forMixin( SecureJettyConfiguration.class ).declareDefaults(); config.hostName().set( "127.0.0.1" ); config.port().set( HTTPS_PORT ); config.keystorePath().set( SERVER_KEYSTORE_PATH ); config.keystoreType().set( "JCEKS" ); config.keystorePassword().set( KS_PASSWORD ); config.truststorePath().set( TRUSTSTORE_PATH ); config.truststoreType().set( "JCEKS" ); config.truststorePassword().set( KS_PASSWORD ); config.wantClientAuth().set( Boolean.TRUE );
See org.qi4j.library.http.SecureJettyConfiguration for a reference of all available configuration properties.
The SLF4J logger used by this library is named "org.qi4j.library.http".
code
docs
tests
The JMX library provides a service that exposes a Qi4j app in JMX automatically, giving you an opportunity to inspect the app much as you would with the Envisage Tool tool.
public void assemble( ModuleAssembly module )
throws AssemblyException
{
[...snip...]
new JMXAssembler().assemble( module );
module.services( JMXConnectorService.class ).instantiateOnStartup();
module.entities( JMXConnectorConfiguration.class );
module.forMixin( JMXConnectorConfiguration.class ).declareDefaults().port().set( 1099 );
}
Note that you need to run it with -Dcom.sun.management.jmxremote so that the JVM starts the MBeanServer.
code
docs
tests
Locking Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
First of all, Qi4j is taking a fresh look at all things that we take for granted. Logging is one such thing.
It should (but is not) obvious that Logging are used for three very distinct purposes, and in our opinion the concepts are not related and should not be abstracted in the same fashion, as has been the norm in Log4j, JDK logging, Commons Logging and most other similar packages and APIs.
- Tracing - Developers often need to trace where the application has been, recording the sequence of execution to see if the logic is correct. This is often a choice when stepping through with a debugger is not possible for whatever reason.
- Debugging - Developers like to get additional information out from a running system. This could be information about conditions, events or unexpected results that we want to record and analyse later.
- Logging - The requirements of an application sometimes specifies that events or conditions should be recorded for auditing purposes. These are often described as domain events and written to a special log file and/or printed to log printer.
Although similar in nature, the audience are very different in Logging vs Debugging/Tracing and their requirements are not only different, but if not handled properly the debug log is mixed up with the audit logs, which in turn can lead to turning off whole or parts of the domain logging by mistake. We want to avoid this, and instead crystalize the needs for each scenario and audience.
Another drastic difference from previous frameworks is that we don’t have an Appender notion. All messages are entities which are stored in a configured entity store. This means that especially the domain log can be more easily be given a user interface suitable for the domain, without complex parsing of message strings
Logging is still not finalized and will need a lot more thought before considered done.
To produce debugging output in your code you just need to add the field
@Optional @This Debug debug;
and then check for null at each usage
if( debug != null )
{
debug.debug( Debug.NORMAL, "Debugging is made easier." );
}
The Debug mixin can be either added to the composite declaration, or it can be added as a contextual fragment during bootstrap.
You will also need to declare a DebugService to be visible to the composite where the debug output is coming from. And the DebugService in turn will use the default UnitOfWork and associated entity store, which must also be configured and visible.
Tracing is the process of tracking all the methods that has been called. There are two levels of tracing available in Qi4j. Either Trace All or trace where a annotation has been given.
If the TraceAllConcern is added to a composite, and there is a TraceService visible, then all method calls into that composite is traced.
If a subset of the methods want to be traced, you can annotate those methods with @Trace in either the Composite Type interface or the mixin implementation. You will also need to add the TraceConcern to the composite.
public interface ImportantRepository
{
@Trace
void addImportantStuff( ImportantStuff stuff );
@Trace
void removeImportantStuff( ImportantStuff stuff );
ImportantStuff findImportantStuff( String searchKey );
}
In the above sample code, the findImportantStuff() method is not traced, whereas the other two will be traced if there is a TraceConcern declared on the composite, and a TraceService visible from that composite.
The fact that each TraceConcern (and TraceAllConcern) will use the TraceService that is visible, allows you to enable or disable tracing per module, simply by adding or removing a TraceService with Visibility.module in each module you want it, or expose Visibility.layer and turn on/off tracing by layers. The TraceConcern has the TraceService as optional.
The recommended way to enable tracing is to use contexual fragments, a feature that allows you to add concerns, sideeffects and mixins to composites during the bootstrap phase instead of hard-coded into the composite declaration.
public void assemble( ModuleAssembly module )
throws AssemblyException
{
module.addServices(ImportantRepository.class)
.withConcerns( TraceAllConcern.class )
.withMixins( Debug.class );
}
code
docs
tests
The Neo4J Library provides a Neo4J embedded database as a Qi4j Service.
Simply assemble the Service:
public void assemble( ModuleAssembly module )
throws AssemblyException
{
module.services( EmbeddedDatabaseService.class );
}
The embedded Neo4J database files are stored in the data directory defined using the FileConfig Library.
@Service EmbeddedDatabaseService neo4jService;
public void doSomething()
{
GraphDatabaseService db = neo4jService.database();
[...snip...]
}
code
docs
tests
OSGi Library allows you to import OSGi services as Qi4j Services and to export Qi4j Services as OSGi Services both leveraging the Qi4j Availability and OSGi FallbackStrategy mechanisms.
interface MyQi4jService
extends OSGiEnabledService
{
// ...
}
[...snip...]
public void assemble( ModuleAssembly module )
throws AssemblyException
{
BundleContext bundleContext = // ...
[...snip...]
module.services( OSGiServiceExporter.class ).
setMetaInfo( bundleContext );
module.services( MyQi4jService.class );
}
public void assemble( ModuleAssembly module )
throws AssemblyException
{
[...snip...]
module.services( OSGiServiceImporter.class ).
setMetaInfo( new OSGiImportInfo( bundleContext,
MyOSGiService.class,
MyOtherOSGiService.class ) ).
setMetaInfo( new MyFallbackStrategy() );
}
The fallback strategy is invoked when the OSGi service is not available and a method call is invoked.
code
docs
tests
RDF Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
Rickard sent a very interesting HATEOAS Primer to the mailing list in October 2011, as the starting point for the renovation of the ReST Client Library. You should read that to get the full background on the choices made in this library.
This library leverages the Restlet library, so keep its documentation nearby as well.
This library expects the client code to build up handlers on how to react to resources and errors. It is a more declarative approach than a typical ReST client application, which often isn’t HATEOAS at all, and Roy Fielding is upset that ReST now means something else than it was originally intended. We try to be true to Dr. Fielding’s intentions.
The first thing that must be done is to create a ContextResourceClient. Let’s walk through the different steps typically needed.
Client client = new Client( Protocol.HTTP ); ContextResourceClientFactory contextResourceClientFactory = module.newObject( ContextResourceClientFactory.class, client ); contextResourceClientFactory.setAcceptedMediaTypes( MediaType.APPLICATION_JSON );
Above we create the Client instance and a ContextResourceClientFactory, which takes a client via @Uses annotation. We also set the accepted media type to JSON.
We then create the global handler, which will be set to all ContextResourceClient instances that this factory creates.
contextResourceClientFactory.setErrorHandler( new ErrorHandler().onError( ErrorHandler.AUTHENTICATION_REQUIRED, new ResponseHandler()
{
boolean tried = false;
@Override
public HandlerCommand handleResponse( Response response, ContextResourceClient client )
{
if (tried)
throw new ResourceException( response.getStatus() );
tried = true;
client.getContextResourceClientFactory().getInfo().setUser( new User("rickard", "secret") );
// Try again
return refresh();
}
} ).onError( ErrorHandler.RECOVERABLE_ERROR, new ResponseHandler()
{
@Override
public HandlerCommand handleResponse( Response response, ContextResourceClient client )
{
// Try to restart
return refresh();
}
} ) );
Above, we try to handle that autheorization is required by setting user credentials and then try again. The client could do a pop-up box instead, have its own cached entries, contact a credentials server or many other things.
We also added another handler that does a refresh() on any recoverable error.
Note that the ErrorHandler.AUTHENTICATION_REQUIRED and ErrorHandler.RECOVERABLE_ERROR are not enums or constants, but Specifications and it is possible to implement your own.
We then simply proceed to create the ContextResourceClient, by giving the factory the bookmarkable reference of the ReST API.
Reference ref = new Reference( "http://localhost:8888/" ); crc = contextResourceClientFactory.newClient( ref );
Once we have the ContextResourceClient, we can proceed with using it. The general approach is to register handlers for potential results when invoking the method on the ReST resource.
crc.onResource( new ResultHandler<Resource>()
{
@Override
public HandlerCommand handleResult( Resource result, ContextResourceClient client )
{
return query( "querywithoutvalue" );
}
} ).
onQuery( "querywithoutvalue", new ResultHandler<TestResult>()
{
@Override
public HandlerCommand handleResult( TestResult result, ContextResourceClient client )
{
Assert.assertThat( result.xyz().get(), CoreMatchers.equalTo( "bar" ) );
return null;
}
} );
crc.start();
crc.onResource( new ResultHandler<Resource>()
{
@Override
public HandlerCommand handleResult( Resource result, ContextResourceClient client )
{
return query( "querywithvalue", null );
}
} ).onProcessingError( "querywithvalue", new ResultHandler<TestQuery>()
{
@Override
public HandlerCommand handleResult( TestQuery result, ContextResourceClient client )
{
ValueBuilder<TestQuery> builder = module.newValueBuilderWithPrototype( result );
builder.prototype().abc().set( "abc" + builder.prototype().abc().get() );
return query( "querywithvalue", builder.newInstance() );
}
} ).onQuery( "querywithvalue", new ResultHandler<TestResult>()
{
@Override
public HandlerCommand handleResult( TestResult result, ContextResourceClient client )
{
return command( "commandwithvalue", null );
}
} ).onProcessingError( "commandwithvalue", new ResultHandler<Form>()
{
@Override
public HandlerCommand handleResult( Form result, ContextResourceClient client )
{
result.set( "abc", "right" );
return command( "commandwithvalue", result );
}
} );
crc.start();
crc.onResource( new ResultHandler<Resource>()
{
@Override
public HandlerCommand handleResult( Resource result, ContextResourceClient client )
{
return query( "commandwithvalue" );
}
} ).onQuery( "commandwithvalue", new ResultHandler<Links>()
{
@Override
public HandlerCommand handleResult( Links result, ContextResourceClient client )
{
Link link = LinksUtil.withId( "right", result );
return command( link );
}
} ).onCommand( "commandwithvalue", new ResponseHandler()
{
@Override
public HandlerCommand handleResponse( Response response, ContextResourceClient client )
{
System.out.println( "Done" );
return null;
}
} );
crc.start();
[...snip...]
crc.onResource( new ResultHandler<Resource>()
{
@Override
public HandlerCommand handleResult( Resource result, ContextResourceClient client )
{
return query( "commandwithvalue" ).onSuccess( new ResultHandler<Links>()
{
@Override
public HandlerCommand handleResult( Links result, ContextResourceClient client )
{
Link link = LinksUtil.withId( "right", result );
return command( link ).onSuccess( new ResponseHandler()
{
@Override
public HandlerCommand handleResponse( Response response, ContextResourceClient client )
{
System.out.println( "Done" );
return null;
}
} );
}
} );
}
} );
crc.start();
crc.onResource( new ResultHandler<Resource>()
{
@Override
public HandlerCommand handleResult( Resource result, ContextResourceClient client )
{
return query( "commandwithvalue" ).onSuccess( new ResultHandler<Links>()
{
@Override
public HandlerCommand handleResult( Links result, ContextResourceClient client )
{
Link link = LinksUtil.withId( "right", result );
return command( link ).onSuccess( new ResponseHandler()
{
@Override
public HandlerCommand handleResponse( Response response, ContextResourceClient client )
{
System.out.println( "Done" );
return null;
}
} );
}
} );
}
} );
crc.start();
The Qi4j ReST Client implements HATEOAS (Hypermedia As The Engine Of Application State) to the full extent intended by Roy Fielding. The ReST Client Library enables the creation of HATEOAS applications that are NOT using the URL space, and it is NOT about doing RPC calls over HTTP using a common exchange format (like JSON).
The ReST Server Library is a corresponding library for creating usecase-driven ReST servers, and with that the corresponding client becomes very thin, as all business rules remain on the server where they belong.
The main point is to support exposing REST resources that focus on use cases and hypermedia.
On the client, we have been thinking a lot about what Roy wrote in his thesis, which boils down to "client makes GET request, based on relation of link invoked and response (headers+hypermedia) make a decision, and then follow links or invoke forms to perform state transitions". It’s a state machine. This is different from your average REST client today in that this model explicitly says that you need to do a GET first (otherwise you have nothing to react to), that the "rel" of the link you followed is important (otherwise context is unknown), and that the client should not make assumptions about what comes back (otherwise you cannot deal with exceptions, on system and application level).
The current REST client approach which is imperative:
result = client.get(somelink)
does not allow for any of the above. Instead, the client code should first register handlers for what to do in various circumstances, and then simply perform one operation: "refresh". This will trigger the first GET to the bookmarked URL, and after that the handlers will do all the work, based on the result. A handler may continue the work by invoking new requests, or it may abort. "refresh" does not return any value, and usually does not throw any exceptions.
Example:
crc.onResource( new ResultHandler<Resource>()
{
@Override
public HandlerCommand handleResult( Resource result, ContextResourceClient client )
{
// This may throw IAE if no link with relation
// "querywithoutvalue" is found in the Resource
return query( "querywithoutvalue", null );
}
} ).
onQuery( "querywithoutvalue", new ResultHandler<TestResult>()
{
@Override
public HandlerCommand handleResult( TestResult result, ContextResourceClient client )
{
Assert.assertThat(result.xyz().get(), CoreMatchers.equalTo("bar"));
return null;
}
} );
crc.start();
The client first builds up the set of handlers, and describe what they should react to. The client then invokes "refresh" which will trigger the first GET on the bookmark URL. This will return a representation of that context as a Resource, and the handler for that is invoked. This then invokes the link with relation "querywithoutvalue" with no input (no request parameters needed). The result of that is then handled by another handler, and the invocation of "refresh" then returns successfully. Note that the first handler may not directly handle the "result" of client.query("querywithoutvalue, null) as it cannot be assumed what happens next. All you know is that you are following a link.
On crc (ContextResourceClient) it is also possible to registers handlers that are always applied, such as error handlers. Here is the setup of crc:
// Create Restlet client and bookmark Reference
Client client = new Client( Protocol.HTTP );
Reference ref = new Reference( "http://localhost:8888/" );
ContextResourceClientFactory contextResourceClientFactory = module.newObject( ContextResourceClientFactory.class, client, new NullResponseHandler() );
contextResourceClientFactory.setAcceptedMediaTypes( MediaType.APPLICATION_JSON );
// Handle logins
contextResourceClientFactory.setErrorHandler( new ErrorHandler().onError( ErrorHandler.AUTHENTICATION_REQUIRED, new ResponseHandler()
{
// Only try to login once
boolean tried = false;
@Override
public HandlerCommand handleResponse( Response response, ContextResourceClient client )
{
// If we have already tried to login, fail!
if (tried)
throw new ResourceException( response.getStatus() );
tried = true;
client.getContextResourceClientFactory().getInfo().setUser( new User("rickard", "secret") );
// Try again
return refresh();
}
} ).onError( ErrorHandler.RECOVERABLE_ERROR, new ResponseHandler()
{
@Override
public HandlerCommand handleResponse( Response response, ContextResourceClient client )
{
// Try to restart this scenario
return refresh();
}
} ) );
crc = contextResourceClientFactory.newClient( ref );
These general handlers cover what to do for login and error handling, for example. In the traditional REST client this is not as easy to do, as you are more or less assuming a "happy path" all the time. In the above scenario there could be any number of steps between doing "refresh" and getting to the meat of the use case, such as doing a signup for the website, login, redirects to other servers, error handling and retries, etc. It becomes possible to blend general application and error handling logic with use case specific handlers.
That’s basically it. This is where I want to go with support for REST, as a way to truly leverage the REST ideas and make it very easy to do REST applications and clients based on Qi4j, by keeping the application logic on the server. In the long run there would also be a JavaScript version of the client, with the same characteristics, so that you can easily build a jQuery UI for Qi4j REST apps.
code
docs
tests
ReST Common Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
ReST Server Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
The Scheduler library provides an easy way to schedule tasks using cron expressions if needed.
An optional Timeline allows you to browse past and future task runs.
The SLF4J Logger used by this library is named "org.qi4j.library.scheduler".
Use SchedulerAssembler to add the Scheduler service to your Application. This Assembler provide a fluent api to programmatically configure configuration defaults and activate the Timeline service assembly that allow to browse in past and future Task runs.
Here is a full example:
new SchedulerAssembler().visibleIn( Visibility.layer )
.withConfigAssembly( configModuleAssembly )
.withTimeline()
.assemble( moduleAssembly );
SchedulerConfiguration defines configuration properties details:
/** * @return Number of worker threads, optional and defaults to the number of available cores. */ @Optional Property<Integer> workersCount(); /** * @return Size of the queue to use for holding tasks before they are run, optional and defaults to 10. */ @Optional Property<Integer> workQueueSize(); /** * @return If the scheduler must stop without waiting for running tasks, optional and defaults to false. */ @UseDefaults Property<Boolean> stopViolently();
To write a schedulable Task, compose an EntityComposite using Task to be able to schedule it.
The Task contract is quite simple:
public interface Task
extends Runnable
{
Property<String> name();
@UseDefaults
Property<List<String>> tags();
}
Tasks have a mandatory name property and an optional tags property. Theses properties get copied in each TimelineRecord created when the Timeline feature is activated.
The run() method of Tasks is wrapped in a UnitOfWork when called by the Scheduler. Thanks to the UnitOfWork handling in Qi4j, you can split the work done in your Tasks in several UnitOfWorks, the one around the Task#run() invocation will then be paused.
Here is a simple example:
interface MyTaskEntity extends Task, EntityComposite
{
Property<String> myTaskState();
Association<AnotherEntity> anotherEntity();
}
abstract class MyTaskMixin implements Runnable
{
@This MyTaskEntity me;
public void run()
{
me.myTaskState().set(me.anotherEntity().get().doSomeStuff(me.myTaskState().get()));
}
}
Tasks are scheduled using the Scheduler service. This creates a Schedule associated to the Task that allows you to know if it is running, to change it’s cron expression and set it’s durability.
By default, a Schedule is not durable. In other words, it do not survive an Application restart. To make a Schedule durable, set it’s durable property to true once its scheduled.
There are two ways to schedule a Task using the Scheduler service: once or with a cron expression.
This is the easiest way to run a background Task once after a given initial delay in seconds.
@Service Scheduler scheduler;
public void method()
{
MyTaskEntity myTask = todo();
Schedule schedule = scheduler.scheduleOnce( myTask, 10, false ); // myTask will be run in 10 seconds from now
}
Note that there is no point in making such a Schedule durable because it won’t be run repeatedly.
Cron expression parsing is based on the GNU crontab manpage that can be found here: http://unixhelp.ed.ac.uk/CGI/man-cgi?crontab+5 .
The following extensions are used:
- a mandatory field is added at the begining: seconds.
- a special string is added: @minutely
- a special character is added: ? to choose between dayOfMonth and dayOfWeek
The ? special char has the same behavior as in the Quartz Scheduler expression. The wikipedia page http://en.wikipedia.org/wiki/CRON_expression explains Quartz Scheduler expression, not simple cron expressions. You’ll find there about the ? special char and maybe that some other extensions you would like to use are missing in this project.
To sum up, cron expressions used here have a precision of one second. The following special strings can be used:
- @minutely
- @hourly
- @midnight or @daily
- @weekly
- @monthly
- @annualy or @yearly
Timeline allow to browse in past and future Task runs. This feature is available only if you activate the Timeline assembly in the SchedulerAssembler}, see above.
Once activated, Task success and failures are recorded. Then, the Timeline service allow to browse in past (recorded) and in anticipated (future) Task runs.
Use the following in your code to get a Timeline Service injected:
@Service Timeline timeline;
Here is the actual Timeline contract:
public interface Timeline
{
[...snip...]
Iterable<TimelineRecord> getLastRecords( int maxResults );
[...snip...]
Iterable<TimelineRecord> getNextRecords( int maxResults );
[...snip...]
Iterable<TimelineRecord> getRecords( DateTime from, DateTime to );
[...snip...]
Iterable<TimelineRecord> getRecords( long from, long to );
}
code
docs
tests
Beanshell Scripting Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
Groovy Scripting Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
Javascript Scripting Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
JRuby Scripting Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
code
docs
tests
This library provide the necessary boilerplate code to bootstrap a Qi4j Application in a Servlet container plus some facilities. It aims at a very simple need and is provided as an example integration.
If instead you want to run a servlet container inside a Qi4j Application, see HTTP Library.
Extends AbstractQi4jServletBootstrap to easily bind a Qi4j Application activation/passivation to your webapp
lifecycle.
Use Qi4jServletSupport#application(javax.servlet.ServletContext) to get a handle on the Application from the
ServletContext.
Here is an example ServletContextListener:
public static class FooServletContextListener
extends AbstractQi4jServletBootstrap
{
public ApplicationAssembly assemble( ApplicationAssemblyFactory applicationFactory )
throws AssemblyException
{
ApplicationAssembly appass = applicationFactory.newApplicationAssembly();
[...snip...]
return appass;
}
}
Qi4jServlet and Qi4jFilter respectively provide base class for easy access to the Application from the
ServletContext.
Here is a sample servlet that simply output the assembled Application name:
public static class FooServlet
extends Qi4jServlet
{
@Override
protected void doGet( HttpServletRequest req, HttpServletResponse resp )
throws ServletException, IOException
{
// Output the assembled Application's name as an example
resp.getWriter().println( application().name() );
}
}
The SLF4J logger used by this library is named "org.qi4j.library.servlet".
code
docs
tests
This library provides integration with the Apache Shiro Java Security Framework.
| Note | |
|---|---|
If you are working on a HTTP based application, see the Shiro Web Security Library that leverages this very library and is directly usable with the HTTP Library, the Servlet Library or any other Servlet based stack. |
“Apache Shiro is a powerful and easy-to-use Java security framework that performs authentication, authorization, cryptography, and session management. With Shiro’s easy-to-understand API, you can quickly and easily secure any application – from the smallest mobile applications to the largest web and enterprise applications.” says the Apache Shiro website.
Altough Apache Shiro can be used as-is with Qi4j Applications, this library provides integrations that can come in handy. If your use case do not fit any of theses integrations, look at their respective code. You should find out pretty easily how to compose the provided code to write your integration. Don’t hesitate to contribute interesting integrations to this very library.
We invite you to read the comprehensive Apache Shiro documentation, we will mostly discuss Qi4j related matters here.
For standalone applications, you can use plain Shiro easily. The only thing to do is to register a configured SecurityManager when activating your Qi4j Application. It can be done outside the application, before its activation, "à là" by-hand ;
IniSecurityManagerFactory factory = new IniSecurityManagerFactory( "classpath:standalone-shiro.ini" ); SecurityManager securityManager = factory.getInstance(); SecurityUtils.setSecurityManager( securityManager );
note that this example code register the SecurityManager as a VM static singleton.
However we recommend to use the provided IniSecurityManagerService that does exactly this when activated and unregister the SecurityManager when passivated:
new StandaloneShiroAssembler().withConfig( configModule ).assemble( module );
You can change the INI resource path through the ShiroIniConfiguration:
public interface ShiroIniConfiguration
extends ConfigurationComposite
{
/**
* Resource path of the ini configuration file.
* "classpath:", "file": and "url:" prefixes are supported.
* Defaulted to "classpath:shiro.ini".
*/
@Optional
Property<String> iniResourcePath();
}
Remember that this setup use a ThreadLocal SecurityManager singleton. Among other things it means that, althoug the IniSecurityManagerService is activated on Application activation, if you need to use Shiro in other Services that are activated on Application activation you should tell Qi4j about this dependency by injecting the SecurityManagerService in the laters.
Once started you must remember to register the SecurityManager in Shiro’s ThreadContext ;
@Service
private IniSecurityManagerService securityManagerService;
[...snip...]
public void interactionBegins()
{
ThreadContext.bind( securityManagerService.getSecurityManager() );
}
[...snip...]
public void interactionEnds()
{
ThreadContext.unbindSubject();
ThreadContext.unbindSecurityManager();
}
that’s how Shiro works.
This library provides the SecurityConcern that should be used alongside the provided method annotations that mimic
Apache Shiro annotations:
-
The
@RequiresAuthenticationannotation requires the current Subject to have been authenticated during their current session for the annotated class/instance/method to be accessed or invoked. -
The
@RequiresGuestannotation requires the current Subject to be a "guest", that is, they are not authenticated or remembered from a previous session for the annotated class/instance/method to be accessed or invoked. -
The
@RequiresPermissionsannotation requires the current Subject be permitted one or more permissions in order to execute the annotated method. -
The
@RequiresRolesannotation requires the current Subject to have all of the specified roles. If they do not have the role(s), the method will not be executed and an AuthorizationException is thrown. -
The
@RequiresUserannotation requires the current Subject to be an application user for the annotated class/instance/method to be accessed or invoked. An application user is defined as a Subject that has a known identity, either known due to being authenticated during the current session or remembered from RememberMe services from a previous session.
All the above is sufficient as long as you use the ini file to store user credentials and permissions or a Realm that has no dependency on your application code and can be specified in the ini file to be instanciated by Shiro outside the Qi4j scope.
One usecase where it’s not sufficient comes quickly as you would like to provide user credentials and permissions from Entities stored in an EntityStore or perform any custom logic involving your Qi4j Application.
Let’s look at a complete example using a Realm Service that extends one of the Shiro provided Realm which use in-memory credientials and configuring it ;
@Mixins( MyRealmMixin.class )
public interface MyRealmService
extends Realm, ServiceComposite, ServiceActivation
{
}
[...snip...]
public class MyRealmMixin
extends SimpleAccountRealm
implements ServiceActivation
{
private final PasswordService passwordService;
public MyRealmMixin()
{
super();
passwordService = new DefaultPasswordService();
PasswordMatcher matcher = new PasswordMatcher();
matcher.setPasswordService( passwordService );
setCredentialsMatcher( matcher );
}
public void activateService()
throws Exception
{
// Create a test account
addAccount( "foo", passwordService.encryptPassword( "bar" ) );
}
[...snip...]
}
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
[...snip...]
new StandaloneShiroAssembler().withConfig( configModule ).assemble( module );
module.services( MyRealmService.class );
[...snip...]
}
We start by defining a Realm Service and its Mixin that’s based on SimpleAccountRealm that we configure to handle hashed passwords. For the sake of the example it is shown how to hash a password using Shiro built in mecanisms. Then comes the Assembly where we simply reuse the Standalone Shiro Assembly and declare our Realm as a Service. It works the same way when using the Shiro Web Security Library.
Note that under the hood, assembled Realm Services are added to the ones configured in the INI file.
Going further, if you want to persist credentials and permissions in an EntityStore, the Shiro Security Library provides skeletons to easily setup some usecases consisting of Shiro setup facilities and base state model for you to compose with.
Password storage is not a simple subject. Shiro provide best practice mecanisms using salt and repeated-hashing out of the box. It is possible to setup your Realm so that hashed passwords are stored in a future proof manner, meaning that you can change the used algorithms while retaining compatibility with passwords already stored.
Shiro use the Shiro1CryptFormat which is a fully reversible Modular Crypt Format (MCF).
This library provides a PasswordRealmService to be used with a PasswordSecurable. Let’s look at a complete
example.
First you need to define your User (or Account, or whatever fits your domain), for the sake of the example we define a UserFactory too. Note that the factory uses the PasswordService implemented by the PasswordRealm to hash the password:
public interface User
extends PasswordSecurable
{
}
[...snip...]
@Mixins( UserFactoryMixin.class )
public interface UserFactory
{
User createNewUser( String username, String password );
}
[...snip...]
public static class UserFactoryMixin
implements UserFactory
{
@Structure
private Module module;
@Service
private PasswordService passwordService;
@Override
public User createNewUser( String username, String password )
{
EntityBuilder<User> userBuilder = module.currentUnitOfWork().newEntityBuilder( User.class );
User user = userBuilder.instance();
user.subjectIdentifier().set( username );
user.password().set( passwordService.encryptPassword( password ) );
return userBuilder.newInstance();
}
}
Now comes the assembly that reuse what’s described above and add both the password domain assembly plus your custom User entity and its factory:
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
[...snip...]
new StandaloneShiroAssembler().withConfig( configModule ).assemble( module );
new PasswordDomainAssembler().withConfig( configModule ).assemble( module );
module.entities( User.class );
module.services( UserFactory.class );
[...snip...]
}
And finally here is how to create a new user and below how to perform a login:
User user = userFactory.createNewUser( "foo", "bar" ); [...snip...] Subject currentUser = SecurityUtils.getSubject(); currentUser.login( new UsernamePasswordToken( "foo", "bar" ) );
In this setup, password hashing use the Shiro’s default (Salted SHA-256 with 500.000 iterations). If you need to change this you can do it using PasswordRealmConfiguration properties:
/** * Sets the name of the MessageDigest algorithm that will be used to compute hashes. */ @Optional Property<String> hashAlgorithmName(); /** * Sets the number of hash iterations that will be performed during hash computation. */ @Optional Property<Integer> hashIterationsCount();
In the same vein, this library provide a domain state skeleton with support in PasswordRealmService. It allows you to
easily store roles, permissions and assignment to your accounts.
Let’s look at the previous example with permissions added.
First you need to add the RoleAssignee type to your account:
public interface User
extends PasswordSecurable, RoleAssignee
{
}
Assembly is straight forward:
new StandaloneShiroAssembler().withConfig( configModule ).assemble( module ); new PasswordDomainAssembler().withConfig( configModule ).assemble( module ); new PermissionsDomainAssembler().assemble( module ); module.entities( User.class ); module.services( UserFactory.class );
And here is how to use all this:
UnitOfWork uow = module.newUnitOfWork();
User user = userFactory.createNewUser( "foo", "bar" );
Role role = roleFactory.create( "role-one", "permission-one", "permission-two" );
role.assignTo( user );
uow.complete();
[...snip...]
uow = module.newUnitOfWork();
Subject currentUser = SecurityUtils.getSubject();
currentUser.login( new UsernamePasswordToken( "foo", "bar" ) );
if ( !currentUser.hasRole( "role-one" ) ) {
fail( "User 'foo' must have 'role-one' role." );
}
if ( !currentUser.isPermitted( "permission-one" ) ) {
fail( "User 'foo' must have 'permission-one' permission." );
}
[...snip...]
uow.discard();
For other authentication mecanisms you can leverage Shiro extensions available in the Shiro distribution or as external libraries. There’s support for text files, simple JDBC, LDAP, CAS SSO, OAuth, OpenID, X.509 Certificates etc…
Take the PasswordRealmService as a start and extend/rewrite it to suit your needs.
If you happen to come with a Qi4j integration that could be valuable in this very library, don’t hesitate to contribute.
All code from this library use the org.qi4j.library.shiro logger.
code
docs
tests
This library provides integration with the Apache Shiro Java Security Framework.
| Note | |
|---|---|
This library only contains web related information. Most of the documentation can be found in the Shiro Security Library that this very library leverages. |
“Apache Shiro is a powerful and easy-to-use Java security framework that performs authentication, authorization, cryptography, and session management. With Shiro’s easy-to-understand API, you can quickly and easily secure any application – from the smallest mobile applications to the largest web and enterprise applications.” says the Apache Shiro website.
We invite you to read the comprehensive Apache Shiro documentation, we will mostly discuss Qi4j related matters here.
In a servlet context, being through the Servlet Library, the HTTP Library or your custom Qi4j application bootstrap, plain Shiro is usable. A WebEnvironment must be globally available and ShiroFilter must be registered.
If you use a custom Qi4j application boostrap or the Servlet Library you can directly use Shiro’s provided EnvironmentLoaderListener and ShiroFilter.
If you use the HTTP Library you can either directly use Shiro classes or use the assembly API as follows:
new JettyServiceAssembler().assemble( module ); [...snip...] new HttpShiroAssembler().withConfig( configModule ).assemble( module );
code
docs
tests
Spring Integration Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
The SQL Library provides facilities for working with SQL databases.
The center piece is the DataSource support that comes with Circuit Breaker Library and JMX Library support. Facilities for doing SQL I/O with the I/O API are provided.
| Tip | |
|---|---|
See the SQL Support Sample that demonstrate combined use of SQL Library, SQL EntityStore and SQL Index/Query. |
Moreover, supplementary libraries helps dealing with different connection pool implementations and schema migrations. None of theses libraries depends on an actual JDBC driver, you are free to use the one that suits your needs.
DataSource support comes in four flavors:
- using the BoneCP connection pool
- using the C3P0 connection pool
- using the Apache DBCP connection pool
- importing an existing DataSource provided at assembly time
Connection Pools support is provided by supplementary libraries.
BoneCP
code
docs
tests
BoneCP support resides in the sql-bonecp module.
// Assemble the BoneCP based Service Importer
new BoneCPDataSourceServiceAssembler().
identifiedBy( DS_SERVICE_ID ).
visibleIn( Visibility.module ).
withConfig( config ).
withConfigVisibility( Visibility.layer ).
assemble( module );
C3P0
code
docs
tests
// Assemble the C3P0 based Service Importer
new C3P0DataSourceServiceAssembler().
identifiedBy( DS_SERVICE_ID ).
visibleIn( Visibility.module ).
withConfig( config ).
withConfigVisibility( Visibility.layer ).
assemble( module );
Apache DBCP
code
docs
tests
// Assemble the Apache DBCP based Service Importer
new DBCPDataSourceServiceAssembler().
identifiedBy( DS_SERVICE_ID ).
visibleIn( Visibility.module ).
withConfig( config ).
withConfigVisibility( Visibility.layer ).
assemble( module );
Assembly
// Assemble a DataSource
new DataSourceAssembler().
withDataSourceServiceIdentity( DS_SERVICE_ID ).
identifiedBy( DS_ID ).
visibleIn( Visibility.module ).
assemble( module );
// Another DataSource managed by the same C3P0 connection pool
new DataSourceAssembler().
withDataSourceServiceIdentity( DS_SERVICE_ID ).
identifiedBy( OTHER_DS_ID ).
visibleIn( Visibility.module ).
assemble( module );
Assembled DataSources must be visible from the connection pool importer service.
Configuration
You need to provide a DataSource Configuration Entity per assembled DataSource. See Configure a Service.
public interface DataSourceConfigurationState
extends Enabled
{
Property<String> driver();
Property<String> url();
@UseDefaults Property<String> username();
@UseDefaults Property<String> password();
@Optional Property<Integer> minPoolSize();
@Optional Property<Integer> maxPoolSize();
@Optional Property<Integer> loginTimeoutSeconds();
@Optional Property<Integer> maxConnectionAgeSeconds();
@Optional Property<String> validationQuery();
@UseDefaults Property<String> properties();
}
Sample DataSource configuration defaults:
enabled=true url=jdbc:derby:memory:testdb;create=true driver=org.apache.derby.jdbc.EmbeddedDriver username= password=
Importing an existing DataSource at assembly time is usefull when your Qi4j Application runs in an environment where DataSource are already provided.
new ExternalDataSourceAssembler( externalDataSource ).
visibleIn( Visibility.module ).
identifiedBy( "datasource-external-id" ).
withCircuitBreaker( DataSources.newDataSourceCircuitBreaker() ).
assemble( module );
This mechanism is provided as an integration convenience and using the embedded connection pools described above is recommended.
Assemblers for managed and external DataSource takes an optional CircuitBreaker and set it as MetaInfo of the DataSource.
CircuitBreaker circuitBreaker = newDataSourceCircuitBreaker( 5 /* threshold */,
1000 * 60 * 5 /* 5min timeout */ );
new DataSourceAssembler().
withDataSourceServiceIdentity( DS_SERVICE_ID ).
identifiedBy( DS_ID ).
visibleIn( Visibility.layer ).
withCircuitBreaker( circuitBreaker ).
assemble( module );
Then, when you gets injected or lookup a DataSource it will be automatically wrapped by a CircuitBreaker proxy.
@Service DataSource dataSource; // Wrapped with a CircuitBreaker proxy
Here is a simple example:
// Look up the DataSource
DataSource ds = module.findService( DataSource.class ).get();
// Instanciate Databases helper
Databases database = new Databases( ds );
// Assert that insertion works
assertTrue( database.update( "insert into test values ('someid', 'bar')" ) == 1 );
[...snip...]
// Select rows and load them in a List
List<SomeValue> rows = new ArrayList<SomeValue>();
database.query( "select * from test" ).transferTo( map( toValue, collection( rows ) ) );
// Transfer all rows to System.out
Inputs.iterable( rows ).transferTo( Outputs.systemOut() );
Thanks to the JMX Library the Configuration of DataSources is exposed through JMX.
new DataSourceJMXAssembler().visibleIn( Visibility.module ).assemble( module );
Every DataSource visible from the DataSourceConfigurationManager Service will get its Configuration available using a JMX client.
Note that the JMX support does not apply to existing DataSource imported as described above.
Database schema migration can be delegated to Liquibase.
code
docs
tests
Assembly
new LiquibaseAssembler( Visibility.module ).
withConfigIn( configModule, Visibility.layer ).
assemble( module );
The LiquibaseService is activated on Application startup and if enabled it applies the configured changelog.
Configuration
public interface LiquibaseConfiguration
extends ConfigurationComposite, Enabled
{
@UseDefaults Property<String> contexts();
@UseDefaults Property<String> changeLog();
}
For the Liquibase service to be enabled you must set it’s Configuration
enabled Property to TRUE. contexts and changeLog are optional.
code
docs
tests
Struts Code Behing Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
Struts Convention Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
Struts Plugin Library
| Note | |
|---|---|
This Library has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
This library provides Services to easily generate unique identifiers and sequences of numbers.
Assembly is done using the provided Assembler:
new UuidServiceAssembler().withVisibility( layer ).assemble( moduleAssembly );
Usage is quite simple:
@Service UuidService uuidService;
public void doSomething()
{
String id1 = uuidService.generateUuid( 0 );
// eg. 1020ECBB-098C-46E0-94DC-F78E2265EAA1-36
String id2 = uuidService.generateUuid( 12 );
// eg. 84E06578EAE3
}
Sequencing is used to automatically generate a sequence of numbers.
The algorithm is that currentSequenceValue is the number that was last returned in a newSequenceValue call, and will
initially be zero. Persisting Sequencing services defines "initially" as the first run ever, as subsequent starts may
retrieve the currentSequenceValue from an EntityStore.
Assembly is done using the provided Assembler:
new TransientSequencingAssembler().withVisibility( layer ).assemble( moduleAssembly );
Usage is quite simple:
@Service Sequencing sequencing;
public void doSomething()
{
sequencing.currentSequenceValue(); // return 0
sequencing.newSequenceValue(); // return 1
sequencing.currentSequenceValue(); // return 1
}
Assembly is done using the provided Assembler:
new PersistingSequencingAssembler().withVisibility( layer ).assemble( moduleAssembly );
Usage is quite simple:
@Service Sequencing sequencing;
public void doSomething()
{
sequencing.currentSequenceValue(); // return 0
sequencing.newSequenceValue(); // return 1
sequencing.currentSequenceValue(); // return 1
}
code
docs
tests
The UoWFile Library provides an easy way to bind file operations to UnitOfWorks.
In other words, using this library you can easily attach files to your Composites, mostly EntityComposites, so that if the UoW gets discarded, changes to files are discarded too. Concurrent modifications are properly handled.
Note that it has a performance impact relative to the files size as it duplicates the file to keep a backup for eventual rollback. However, the API provides a way to get non-managed handles on the attached files to keep your read-only operations fast.
The location of files is left to the developer using a private mixin.
The SLF4J Logger used by this library is named "org.qi4j.library.uowfile".
Let’s say you have the following Entity:
public interface TestedEntity
extends EntityComposite,
[...snip...]
{
Property<String> name();
}
To add an attached file to it you first need to extends HasUoWFileLifecycle:
public interface TestedEntity
extends EntityComposite,
HasUoWFileLifecycle
{
Property<String> name();
}
This provides you with the following contract:
public interface HasUoWFile
{
/**
* IMPORTANT Use this {@link File} only inside read-only {@link UnitOfWork}s
*/
File attachedFile();
File managedFile();
[...snip...]
}
Next you need to write the UoWFileLocator mixin:
public static abstract class TestedFileLocatorMixin
implements UoWFileLocator
{
@This
private Identity meAsIdentity;
@Override
public File locateAttachedFile()
{
return new File( baseTestDir, meAsIdentity.identity().get() );
}
}
Assemble all this as follow:
public void assemble( ModuleAssembly module )
throws AssemblyException
{
new UoWFileAssembler().assemble( module );
module.entities( TestedEntity.class ).withMixins( TestedFileLocatorMixin.class );
[...snip...]
}
You can now use the following methods on your EntityComposite:
File attachedFile = entity.attachedFile(); File managedFile = entity.managedFile();
Now if you want to attach several files to one entity, this library provides a simple mechanism allowing you to use any enum as discriminator.
Let’s say you have the following Entity:
public interface TestedEntity
extends EntityComposite,
[...snip...]
{
Property<String> name();
}
It’s the very same as the one used to start the singular file support described above.
To add an attached file to it you first need to write an enum and extends HasUoWFilesLifecycle:
public enum MyEnum
{
fileOne, fileTwo
}
public interface TestedEntity
extends EntityComposite,
HasUoWFilesLifecycle<MyEnum>
{
Property<String> name();
}
This provides you with the following contract:
public interface HasUoWFiles<T extends Enum<T>>
{
/**
* IMPORTANT Use this {@link File} only inside read-only {@link UnitOfWork}s
*/
File attachedFile( T key );
/**
* IMPORTANT Use these {@link File}s only inside read-only {@link UnitOfWork}s
*/
Iterable<File> attachedFiles();
File managedFile( T key );
Iterable<File> managedFiles();
[...snip...]
}
Next you need to write the UoWFileLocator mixin:
public static abstract class TestedFilesLocatorMixin
implements UoWFilesLocator<MyEnum>
{
@This
private Identity meAsIdentity;
@Override
public Iterable<File> locateAttachedFiles()
{
List<File> list = new ArrayList<File>();
for ( MyEnum eachValue : MyEnum.values() ) {
list.add( new File( baseTestDir, meAsIdentity.identity().get() + "." + eachValue.name() ) );
}
return list;
}
@Override
public File locateAttachedFile( MyEnum key )
{
return new File( baseTestDir, meAsIdentity.identity().get() + "." + key.name() );
}
}
Assemble all this as follow:
public void assemble( ModuleAssembly module )
throws AssemblyException
{
new UoWFileAssembler().assemble( module );
module.entities( TestedEntity.class ).withMixins( TestedFilesLocatorMixin.class );
[...snip...]
}
You can now use the following methods on your EntityComposite:
File attachedFileTwo = entity.attachedFile( MyEnum.fileTwo ); File managedFileOne = entity.managedFile( MyEnum.fileOne );
- 8.1. Overview
- 8.2. org.json ValueSerialization
- 8.3. Jackson ValueSerialization
- 8.4. StAX ValueSerialization
- 8.5. Ehcache Cache
- 8.6. Memory EntityStore
- 8.7. File EntityStore
- 8.8. Google AppEngine EntityStore
- 8.9. Hazelcast EntityStore
- 8.10. JClouds EntityStore
- 8.11. JDBM EntityStore
- 8.12. LevelDB EntityStore
- 8.13. MongoDB EntityStore
- 8.14. Neo4j EntityStore
- 8.15. Preferences EntityStore
- 8.16. Redis EntityStore
- 8.17. Riak EntityStore
- 8.18. SQL EntityStore
- 8.19. Voldemort EntityStore
- 8.20. ElasticSearch Index/Query
- 8.21. OpenRDF Index/Query
- 8.22. Apache Solr Index/Query
- 8.23. SQL Index/Query
- 8.24. Yammer Metrics
- 8.25. Migration
- 8.26. Reindexer
We try to keep the Qi4j Core Runtime as lean as possible, and a lot of the power to the Qi4j Platform comes via its Extension SPI, which defines clear ways to extend the platform. There are currently the following Extensions types, each with possibly more than one implementation;
- Value Serialization
- Entity Stores
- Index / Query Engines
- Entity Caches
- Metrics Gathering
- Reindexing
- Migration
This section will go through each of the available extensions. The Qi4j Extensions are of varying maturity level and we try to maintain a STATUS (dev-status.xml) file indicating how good the codebase, documentation and unit tests are for each of the libraries. This is highly subjective and potentially different individuals will judge this differently, but at least it gives a ballpark idea of the situation for our users.
code
docs
tests
ValueSerialization Service backed by org.json.
Artifact
| Group ID | Artifact ID | Version |
|---|---|---|
org.qi4j.extension | org.qi4j.extension.valueserialization-orgjson | 2.0 |
code
docs
tests
ValueSerialization Service backed by Jackson.
Artifact
| Group ID | Artifact ID | Version |
|---|---|---|
org.qi4j.extension | org.qi4j.extension.valueserialization-jackson | 2.0 |
code
docs
tests
ValueSerialization Service backed by StAX.
code
docs
tests
Ehcache Cache
| Note | |
|---|---|
This Extension has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
EntityStore service backed by an in-memory Map.
Assembly is done as follows:
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
new MemoryEntityStoreAssembler().assemble( module );
[...snip...]
}
This EntityStore has no configuration.
code
docs
tests
EntityStore service backed by a source control friendly file system format.
Note that content should not be modified directly, and doing so may corrupt the data.
Assembly is done as follows:
public void assemble( ModuleAssembly module )
throws AssemblyException
{
[...snip...]
new OrgJsonValueSerializationAssembler().assemble( module );
new FileEntityStoreAssembler().assemble( module );
config.entities( FileEntityStoreConfiguration.class ).visibleIn( Visibility.layer );
}
Here are the configuration properties for the File EntityStore:
public interface FileEntityStoreConfiguration
extends ConfigurationComposite
{
[...snip...]
@Optional
Property<String> directory();
[...snip...]
@Optional @Range(min=1, max=10000)
Property<Integer> slices();
}
directory is optional and represent the directory where the File EntityStore will keep its persisted state.
It defaults to System.getProperty( "user.dir" ) + "/qi4j/filestore" If the given path is not absolute, then it’s relative to the current working directory. If you use the FileConfig Library then this property value is ignored and FileConfig is prefered.
slices defines how many slice directories the store should use.
Many operating systems run into performance problems when the number of files in a directory grows. If you expect a large number of entities in the file entity store, it is wise to set the number of slices (default is 1) to an approximation of the square root of number of expected entities.
For instance, if you estimate that you will have 1 million entities in the file entity store, you should set the slices to 1000.
There is a limit of minimum 1 slice and maximum 10,000 slices, and if more slices than that is needed, you are probably pushing this entitystore beyond its capabilities.
Note that the slices() can not be changed once it has been set, as it would cause the entity store not to find the entities anymore.
code
docs
tests
AppEngine EntityStore
| Note | |
|---|---|
This Extension has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
EntityStore service backed by the Hazelcast in-memory data grid.
Assembly is done using the provided Assembler:
public void assemble( ModuleAssembly module )
throws AssemblyException
{
[...snip...]
new HazelcastEntityStoreAssembler().withConfigIn( configModule, Visibility.layer ).assemble( module );
}
Here are the configuration properties for the Hazelcast EntityStore:
public interface HazelcastConfiguration
extends ConfigurationComposite
{
@UseDefaults
Property<String> configXmlLocation();
@UseDefaults
Property<String> mapName();
}
configXmlLocation represent the location of the Hazelcast XML based configuration.
mapName is the name of the used Hazelcast Map
code
docs
tests
EntityStore service backed by a JClouds BlobStore.
It means you get access to a growing list of providers available at the JClouds website that includes Amazon, VMWare, Azure, and Rackspace.
For testing purpose theses providers are supported too:
- Transient
- Filesystem
Assembly is done using the provided Assembler:
new JCloudsMapEntityStoreAssembler().withConfigIn( config, Visibility.layer ).assemble( module );
Here are the configuration properties for the JClouds EntityStore:
/** * Name of the JClouds provider to use. Defaults to 'transient'. */ @Optional Property<String> provider(); @UseDefaults Property<String> identifier(); @UseDefaults Property<String> credential(); /** * Use this to fine tune your provider implementation according to JClouds documentation. */ @UseDefaults Property<Map<String, String>> properties(); /** * Name of the JClouds container to use. Defaults to 'qi4j-entities'. */ @Optional Property<String> container();
code
docs
tests
EntityStore service backed by an embedded JDBM2 database.
Assembly is done using the provided Assembler:
@Override
public void assemble( ModuleAssembly module )
throws AssemblyException
{
JdbmEntityStoreAssembler assembler = new JdbmEntityStoreAssembler( Visibility.application );
assembler.assemble( module );
}
Here are the configuration properties for the JDBM EntityStore:
public interface JdbmConfiguration
extends ConfigurationComposite
{
[...snip...]
@Optional
Property<String> file();
// JDBM RecordManager options
@UseDefaults
Property<Boolean> autoCommit();
@UseDefaults
Property<Boolean> disableTransactions();
}
file is optional and represent the file where the JDBM EntityStore will keep its persisted state.
It defaults to System.getProperty( "user.dir" ) + "/qi4j/jdbmstore.data" If the given path is not absolute, then it’s relative to the current working directory. If you use the FileConfig Library then this property value is ignored and FileConfig is prefered.
code
docs
tests
EntityStore service backed by a LevelDB embedded database.
LevelDB is a fast key-value storage library written at Google that provides an ordered mapping from string keys to string values.
By default use the native implementation through JNI bindings and fallback to the pure Java implementation if not available on the current platform. Used implementation can be forced in the configuration.
The LevelDB EntityStore relies on the FileConfig Library to decide where it stores its database.
Assembly is done using the provided Assembler:
public void assemble( ModuleAssembly module )
throws AssemblyException
{
[...snip...]
new LevelDBEntityStoreAssembler().
withConfig( config, Visibility.layer ).
identifiedBy( "java-leveldb-entitystore" ).
assemble( module );
[...snip...]
}
Here are the configuration properties for the LevelDB EntityStore:
public interface LevelDBEntityStoreConfiguration
extends ConfigurationComposite
{
/**
* LevelDB flavour, can be 'java' or 'jni'.
* By default, tries 'jni' and fallback to 'java'.
*/
@Optional
Property<String> flavour();
@Optional
Property<Integer> blockRestartInterval();
@Optional
Property<Integer> blockSize();
@Optional
Property<Long> cacheSize();
@Optional
Property<Boolean> compression();
@Optional
Property<Integer> maxOpenFiles();
@Optional
Property<Boolean> paranoidChecks();
@Optional
Property<Boolean> verifyChecksums();
@Optional
Property<Integer> writeBufferSize();
}
All configuration properties are defaulted to the implementation defaults meaning that you can use LevelDB EntityStore service without configuration.
code
docs
tests
EntityStore service backed by a MongoDB collection in which Entity state is stored as native MongoDB BSON.
Assembly is done using the provided Assembler:
public void assemble( ModuleAssembly module )
throws AssemblyException
{
[...snip...]
new MongoMapEntityStoreAssembler().withConfigModule( config ).assemble( module );
[...snip...]
}
Here are the configuration properties for the MongoDB EntityStore:
public interface MongoEntityStoreConfiguration
extends ConfigurationComposite
{
@Optional
Property<String> hostname();
@Optional
Property<Integer> port();
@UseDefaults
Property<List<ServerAddress>> nodes();
@UseDefaults
Property<String> username();
@UseDefaults
Property<String> password();
@Optional
Property<String> database();
@Optional
Property<String> collection();
@UseDefaults
Property<WriteConcern> writeConcern();
enum WriteConcern
{
/** Exceptions are raised for network issues, but not server errors */
NORMAL,
/** No exceptions are raised, even for network issues */
NONE,
/** Exceptions are raised for network issues, and server errors; waits on a server for the write operation */
SAFE,
/** Exceptions are raised for network issues, and server errors; waits on a majority of servers for the write operation */
MAJORITY,
/** Exceptions are raised for network issues, and server errors; the write operation waits for the server to flush the data to disk*/
FSYNC_SAFE,
/** Exceptions are raised for network issues, and server errors; the write operation waits for the server to group commit to the journal file on disk*/
JOURNAL_SAFE,
/** Exceptions are raised for network issues, and server errors; waits for at least 2 servers for the write operation*/
REPLICAS_SAFE;
}
}
code
docs
tests
Neo4j EntityStore
| Note | |
|---|---|
This Extension has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
EntityStore service backed by java.util.prefs.Preferences. It can be a good candidate to store Configuration Composites.
Assembly is done using the provided Assembler:
public void assemble( ModuleAssembly module )
throws AssemblyException
{
new PreferenceEntityStoreAssembler( Visibility.module ).assemble( module );
}
code
docs
tests
EntityStore service backed by a Redis database.
Assembly is done using the provided Assembler.
public void assemble( ModuleAssembly module )
throws AssemblyException
{
[...snip...]
new RedisMapEntityStoreAssembler().withConfigModule( config ).assemble( module );
}
Here are the configuration properties for the Redis client:
public interface RedisEntityStoreConfiguration
extends ConfigurationComposite
{
/**
* Redis host.
*
* Defaulted to 127.0.0.1.
*/
@Optional
Property<String> host();
/**
* Redis port.
*
* Defaulted to 6379.
*/
@Optional
Property<Integer> port();
/**
* Connection timeout in milliseconds.
*
* Defaulted to 2000.
*/
@Optional
Property<Integer> timeout();
/**
* Redis password.
*/
@Optional
Property<String> password();
/**
* Redis database.
*
* Defaulted to 0.
*/
@Optional
Property<Integer> database();
}
code
docs
tests
EntityStore service backed by a Riak bucket.
The EntityStore comes in two flavours: HTTP or ProtocolBuffer based. See the Riak documentation.
Assembly is done using the provided Assemblers.
For HTTP based Riak client:
public void assemble( ModuleAssembly module )
throws AssemblyException
{
[...snip...]
new RiakHttpMapEntityStoreAssembler().withConfigModule( config ).assemble( module );
}
For ProtocolBuffer based Riak client:
public void assemble( ModuleAssembly module )
throws AssemblyException
{
[...snip...]
new RiakProtobufMapEntityStoreAssembler().withConfigModule( config ).assemble( module );
}
Here are the configuration properties for the HTTP based Riak client:
public interface RiakHttpEntityStoreConfiguration
extends ConfigurationComposite
{
/**
* List of Riak URLs.
*
* Defaulted to http://127.0.0.1:8098/riak if empty.
*/
@UseDefaults
Property<List<String>> urls();
/**
* Riak Bucket where Entities state will be stored.
*
* Defaulted to "qi4j:entities".
*/
@Optional
Property<String> bucket();
/**
* Maximum total connections.
*
* Defaulted to 50. Use 0 for infinite number of connections.
*/
@Optional
Property<Integer> maxConnections();
/**
* The connection, socket read and pooled connection acquisition timeout in milliseconds.
*
* Defaulted to 0 (infinite).
*/
@UseDefaults
Property<Integer> timeout();
}
Here are the configuration properties for the ProtocolBuffer based Riak client:
public interface RiakProtobufEntityStoreConfiguration
extends ConfigurationComposite
{
/**
* List of Riak Protocol Buffer hosts.
*
* Each entry can contain either an IP address / hostname
* or an IP address / hostname followed by a column and the host's port.
*
* Defaulted to 127.0.0.1 if empty.
*/
@UseDefaults
Property<List<String>> hosts();
/**
* Riak Bucket where Entities state will be stored.
*
* Defaulted to "qi4j:entities".
*/
@Optional
Property<String> bucket();
/**
* Maximum total connections.
*
* Defaulted to 50. Use 0 for infinite number of connections.
*/
@Optional
Property<Integer> maxConnections();
/**
* The connection timeout in milliseconds.
*
* Defaulted to 1000.
*/
@Optional
Property<Integer> connectionTimeout();
/**
* Idle connection time to live in milliseconds.
*
* Defaulted to 1000.
*/
@Optional
Property<Integer> idleConnectionTTL();
/**
* Max pool size.
*
* Defaulted to 0 (unlimited).
*/
@UseDefaults
Property<Integer> maxPoolSize();
/**
* Initial pool size.
*
* Defaulted to 0.
*/
@UseDefaults
Property<Integer> initialPoolSize();
/**
* Socket buffer size in KB.
*
* Defaulted to 16.
*/
@Optional
Property<Integer> socketBufferSizeKb();
}
code
docs
tests
EntityStore service backed by a SQL database.
This extension fully leverage the SQL Library meaning that you must use it to assemble your DataSource and that you get Circuit Breaker and JMX integration for free.
| Tip | |
|---|---|
See the SQL Support Sample that demonstrate combined use of SQL Library, SQL EntityStore and SQL Index/Query. |
The following SQL databases are supported:
Each entity state is stored as a single row so maximum number of entities is the maximum number of rows per table supported by the underlying SQL database.
Implementations per database Vendor share a generic codebase but can override about everything SQL. As a consequence they can have strong differences in terms of performance if they use vendor specific extensions.
SQL EntityStore Configuration is optional and provides only one configuration property: schemaName defaulted to
qi4j_es. On SQL databases that don’t support schemas this configuration property is simply ignored.
The assembly snippets below show the DataSource assembly alongside the SQL EntityStore assembly. Remember to configure the DataSource properly, see SQL Library and Configure a Service.
Maximum number of entities is unlimited.
Assembly is done using the provided Assembler:
public void assemble( ModuleAssembly module )
throws AssemblyException
{
[...snip...]
// DataSourceService
new DBCPDataSourceServiceAssembler().
identifiedBy( "postgresql-datasource-service" ).
visibleIn( Visibility.module ).
withConfig( config ).
withConfigVisibility( Visibility.layer ).
assemble( module );
// DataSource
new DataSourceAssembler().
withDataSourceServiceIdentity( "postgresql-datasource-service" ).
identifiedBy( "postgresql-datasource" ).
visibleIn( Visibility.module ).
withCircuitBreaker();
// SQL EntityStore
new PostgreSQLEntityStoreAssembler().
visibleIn( Visibility.application ).
withConfig( config ).
withConfigVisibility( Visibility.layer ).
assemble( module );
}
Sample DataSource configuration defaults:
enabled=true url=jdbc:postgresql://localhost:5432/jdbc_test_db driver=org.postgresql.Driver username=jdbc_test_login password=password
Maximum number of entities depends on the choosen storage engine.
Assembly is done using the provided Assembler:
public void assemble( ModuleAssembly module )
throws AssemblyException
{
[...snip...]
// DataSourceService
new DBCPDataSourceServiceAssembler().
identifiedBy( "mysql-datasource-service" ).
visibleIn( Visibility.module ).
withConfig( config ).
withConfigVisibility( Visibility.layer ).
assemble( module );
// DataSource
new DataSourceAssembler().
withDataSourceServiceIdentity( "mysql-datasource-service" ).
identifiedBy( "mysql-datasource" ).
visibleIn( Visibility.module ).
withCircuitBreaker().
assemble( module );
// SQL EntityStore
new MySQLEntityStoreAssembler().
visibleIn( Visibility.application ).
withConfig( config ).
withConfigVisibility( Visibility.layer ).
assemble( module );
}
Sample DataSource configuration defaults:
enabled=true url=jdbc:mysql://localhost:3306/jdbc_test_db?profileSQL=true driver=com.mysql.jdbc.Driver username=root password=
Maximum number of entities is unlimited.
The Xerial SQLite JDBC driver is recommended. It provides native support on Linux, Windows and MaxOSX, pure Java on other OSes.
Assembly is done using the provided Assembler:
public void assemble( ModuleAssembly module )
throws AssemblyException
{
[...snip...]
// DataSourceService
new DBCPDataSourceServiceAssembler().
identifiedBy( "sqlite-datasource-service" ).
visibleIn( Visibility.module ).
withConfig( config ).
withConfigVisibility( Visibility.layer ).
assemble( module );
// DataSource
new DataSourceAssembler().
withDataSourceServiceIdentity( "sqlite-datasource-service" ).
identifiedBy( "sqlite-datasource" ).
visibleIn( Visibility.module ).
withCircuitBreaker().
assemble( module );
// SQL EntityStore
new SQLiteEntityStoreAssembler().
visibleIn( Visibility.application ).
withConfig( config ).
withConfigVisibility( Visibility.layer ).
assemble( module );
}
Sample DataSource configuration defaults:
enabled=true url=jdbc:sqlite::memory: driver=org.sqlite.JDBC username= password=
Maximum number of entities is 2^64.
Assembly is done using the provided Assembler:
public void assemble( ModuleAssembly module )
throws AssemblyException
{
[...snip...]
// DataSourceService
new DBCPDataSourceServiceAssembler().
identifiedBy( "h2-datasource-service" ).
visibleIn( Visibility.module ).
withConfig( config ).
withConfigVisibility( Visibility.layer ).
assemble( module );
// DataSource
new DataSourceAssembler().
withDataSourceServiceIdentity( "h2-datasource-service" ).
identifiedBy( "h2-datasource" ).
visibleIn( Visibility.module ).
withCircuitBreaker().
assemble( module );
// SQL EntityStore
new H2SQLEntityStoreAssembler().
visibleIn( Visibility.application ).
withConfig( config ).
withConfigVisibility( Visibility.layer ).
assemble( module );
}
Sample DataSource configuration defaults:
enabled=true url=jdbc:h2:mem:test driver=org.h2.Driver username= password=
Maximum number of entities is unlimited.
Assembly is done using the provided Assembler:
public void assemble( ModuleAssembly module )
throws AssemblyException
{
[...snip...]
// DataSourceService
new DBCPDataSourceServiceAssembler().
identifiedBy( "derby-datasource-service" ).
visibleIn( Visibility.module ).
withConfig( config ).
withConfigVisibility( Visibility.layer ).
assemble( module );
// DataSource
new DataSourceAssembler().
withDataSourceServiceIdentity( "derby-datasource-service" ).
identifiedBy( "derby-datasource" ).
visibleIn( Visibility.module ).
withCircuitBreaker().
assemble( module );
// SQL EntityStore
new DerbySQLEntityStoreAssembler().
visibleIn( Visibility.application ).
withConfig( config ).
withConfigVisibility( Visibility.layer ).
assemble( module );
}
Sample DataSource configuration defaults:
enabled=true url=jdbc:derby:memory:testdb;create=true driver=org.apache.derby.jdbc.EmbeddedDriver username= password=
code
docs
tests
Voldemort EntityStore
| Note | |
|---|---|
This Extension has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
Index/Query services backed by ElasticSearch search engine built on top of Apache Lucene.
| Warning | |
|---|---|
ElasticSearch does not support queries using regular expressions. It means that you can’t use MatchesSpecification from the Query API. See the ElasticSearch issue #988. |
Three modes of operation are supported:
- in-memory ;
- on-filesystem ;
- clustered.
Both in-memory and on-filesystem assemblies share the same configuration properties, see below.
In-memory ElasticSearch Index/Query service relies on the FileConfig Library to decide where it stores its transaction logs as there’s no in-memory transaction log implementation in ElasticSearch.
Assembly is done using the provided Assembler:
new ESMemoryIndexQueryAssembler().withConfigModule( configModule ).assemble( module );
Filesystem based ElasticSearch Index/Query service relies on the FileConfig Library to decide where it stores its index data, transaction logs etc…
Assembly is done using the provided Assembler:
new ESFilesystemIndexQueryAssembler().withConfigModule( configModule ).assemble( module );
| Important | |
|---|---|
By default queries can only traverse Aggregated Associations, if you want to be able to traverse all
Associations set the |
Here are the configuration properties for both the in-memory and on-filesystem ElasticSearch Index/Query services:
public interface ElasticSearchConfiguration
extends ConfigurationComposite
{
/**
* Cluster name.
* Defaults to 'qi4j_cluster'.
*/
@Optional Property<String> clusterName();
/**
* Index name.
* Defaults to 'qi4j_index'.
*/
@Optional Property<String> index();
/**
* Set to true to index non aggregated associations as if they were aggregated.
* WARN: Don't use this if your domain model contains circular dependencies.
* Defaults to 'FALSE'.
*/
@UseDefaults Property<Boolean> indexNonAggregatedAssociations();
}
All configuration properties are defaulted meaning that you can use ElasticSearch Index/Query service without configuration.
Assembly is done using the provided Assembler:
new ESClusterIndexQueryAssembler().withConfigModule( configModule ).assemble( module );
Here are the configuration properties for the clustered ElasticSearch Index/Query service. Note that it inherits the properties defined in the in-memory or on-filesystem configuration, see above.
public interface ElasticSearchClusterConfiguration
extends ElasticSearchConfiguration
{
/**
* Coma separated list of nodes host:port.
* Defaults to '127.0.0.1:9300'.
*/
@Optional Property<String> nodes();
/**
* Allows client to sniff the rest of the cluster, and add those into its list of machines to use.
* In this case, note that the ip addresses used will be the ones that the other nodes were started
* with (the “publish” address).
* Defaults to FALSE.
*/
@UseDefaults Property<Boolean> clusterSniff();
/**
* Set to true to ignore cluster name validation of connected nodes.
* Defaults to FALSE.
*/
@UseDefaults Property<Boolean> ignoreClusterName();
/**
* The time to wait for a ping response from a node.
* Defaults to 5s.
*/
@Optional Property<String> pingTimeout();
/**
* How often to sample / ping the nodes listed and connected.
* Defaults to 5s.
*/
@Optional Property<String> samplerInterval();
}
Again, all configuration properties are defaulted meaning that you can use ElasticSearch Index/Query service without configuration.
code
docs
tests
Index/Query services backed by OpenRDF Sesame framework for processing RDF data.
Assembly is done using the provided Assembler:
new RdfMemoryStoreAssembler().assemble( module );
No configuration needed.
Assembly is done using the provided Assembler:
new RdfNativeSesameStoreAssembler().assemble( module );
Here are the configuration properties for the Native RDF Index/Query:
public interface NativeConfiguration extends ConfigurationComposite
{
@Optional @Matches( "([spoc][spoc][spoc][spoc],?)*" ) Property<String> tripleIndexes();
@Optional Property<String> dataDirectory();
@UseDefaults Property<Boolean> forceSync();
}
Assembly is done using the provided Assembler:
new RdfRdbmsSesameStoreAssembler().assemble( module );
Here are the configuration properties for the RDBMS based RDF Index/Query:
public interface RdbmsRepositoryConfiguration
{
Property<String> jdbcDriver();
Property<String> jdbcUrl();
Property<String> user();
Property<String> password();
}
code
docs
tests
Index/Query services backed by an embedded Apache Solr Search.
| Warning | |
|---|---|
Solr Index/Query service do not support the Qi4j Query API but only native Solr queries. |
Assembly is done using the provided Assembler:
new SolrAssembler().assemble( module );
Apache Solr Index/Query exclusively use the FileConfig Library to locate the directory where it persists its index.
You must provide solrconfig.xml and schema.xml files either from the classpath or in the configuration directory of
the FileConfig Library.
code
docs
tests
This extension fully leverage the SQL Library meaning that you must use it to assemble your DataSource and that you get Cricuit Breaker and JMX integration for free.
| Tip | |
|---|---|
See the SQL Support Sample that demonstrate combined use of SQL Library, SQL EntityStore and SQL Index/Query. |
The following SQL databases are supported:
Implementations per database Vendor share a generic codebase but can override about everything SQL. As a consequence they can have strong differences in terms of performance if they use vendor specific extensions.
SQL Index/Query Configuration is optional and provides only one configuration property: schemaName defaulted to
qi4j_es. On SQL databases that don’t support schemas this configuration property is simply ignored.
The assembly snippets below show the DataSource assembly alongside the SQL Index/Query assembly. Remember to configure the DataSource properly, see SQL Library and Configure a Service.
Assembly is done using the provided Assembler:
// DataSourceService
new DBCPDataSourceServiceAssembler().
identifiedBy( "postgres-datasource-service" ).
visibleIn( Visibility.module ).
withConfig( config ).
withConfigVisibility( Visibility.layer ).
assemble( mainModule );
// DataSource
new DataSourceAssembler().
withDataSourceServiceIdentity( "postgres-datasource-service" ).
identifiedBy( "postgres-datasource" ).
visibleIn( Visibility.module ).
withCircuitBreaker().
assemble( mainModule );
// SQL Index/Query
new PostgreSQLIndexQueryAssembler().
visibleIn( Visibility.application ).
withConfig( config ).
withConfigVisibility( Visibility.layer ).
assemble( mainModule );
Sample DataSource configuration defaults:
enabled=true url=jdbc:postgresql://localhost:5432/jdbc_test_db driver=org.postgresql.Driver username=jdbc_test_login password=password
| Important | |
|---|---|
The PostgreSQL ltree extension is needed on the used database, see below how to install it on your database. |
It’s bundled with PostgreSQL but you need to activate it on your database:
CREATE EXTENSION ltree;
You need to install postgresql-contrib and import the module in your database. The following applies to Debian based distributions, adapt it to yours:
- Install the contrib package: sudo apt-get install postgresql-contrib
- Restart the database: sudo /etc/init.d/postgresql-8.4 restart
- Change to the database owner account (e.g., postgres).
- Change to the contrib modules' directory: /usr/share/postgresql/8.4/contrib/
- Load the SQL files using: psql -U user_name -d database_name -f module_name.sql
For example to install the needed ltree module:
psql -U postgres -d database_name -f ltree.sql
code
docs
tests
Yammer Metrics
| Note | |
|---|---|
This Extension has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
Migration
| Note | |
|---|---|
This Extension has no documentation yet. Learn how to contribute in Writing Documentation. |
code
docs
tests
Reindexer
| Note | |
|---|---|
This Extension has no documentation yet. Learn how to contribute in Writing Documentation. |
The Qi4j SDK comes with usefull development tools. Theses tools can come in handy when assembled into your Application in development Application Mode.
The tools are available in the tools/ directory of the Qi4j SDK.
Envisage is a Swing based visualization tool for the Qi4j Application model. Visualizations can be printed to PDFs.
Envisage can be easily used directly and prior your Application activation:
public static void main( String[] args )
throws Exception
{
Energy4Java energy4Java = new Energy4Java();
ApplicationDescriptor applicationModel =
energy4Java.newApplicationModel( new SchoolAssembler() );
new Envisage().run( applicationModel );
}
As you can see, Envisage operates on the ApplicationModel, this means that you can easily embedd it in your own Applications too.
Two gradle tasks runSample and runSchool are defined in this module as a shortcut to run the examples. See Build System.
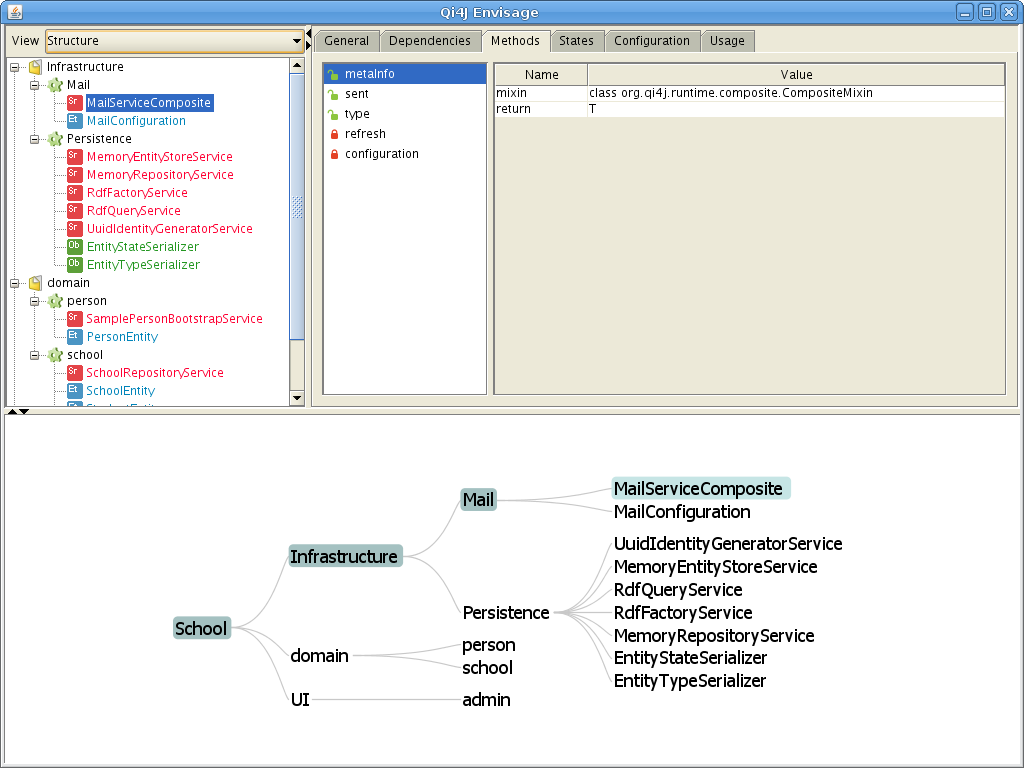
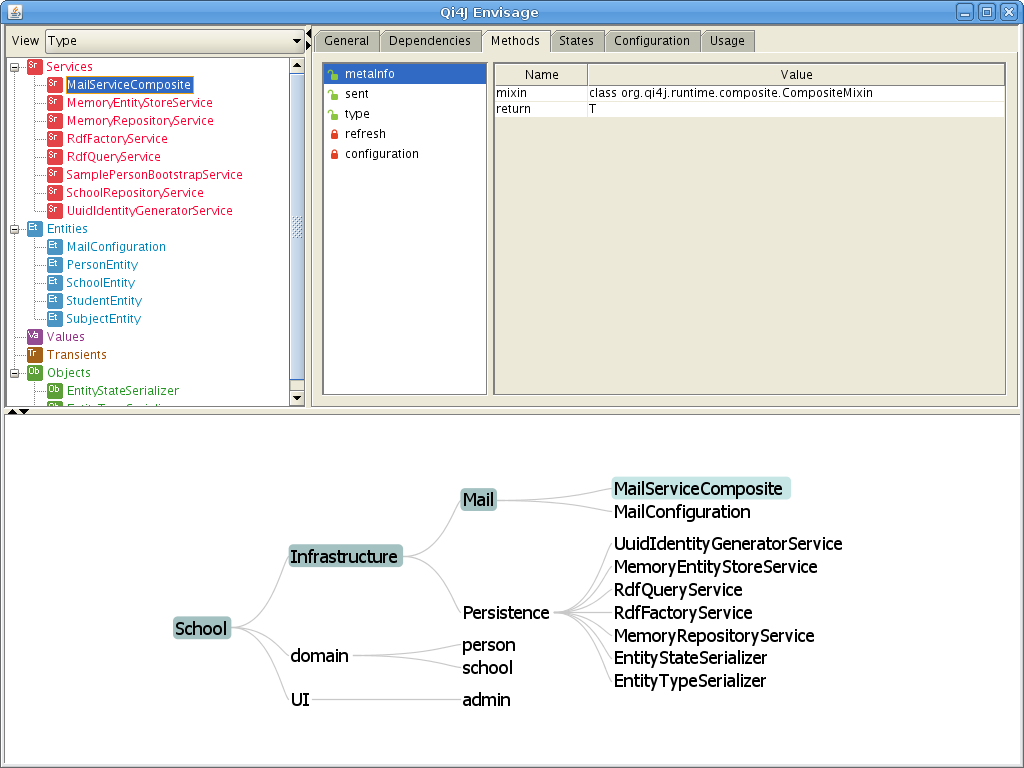
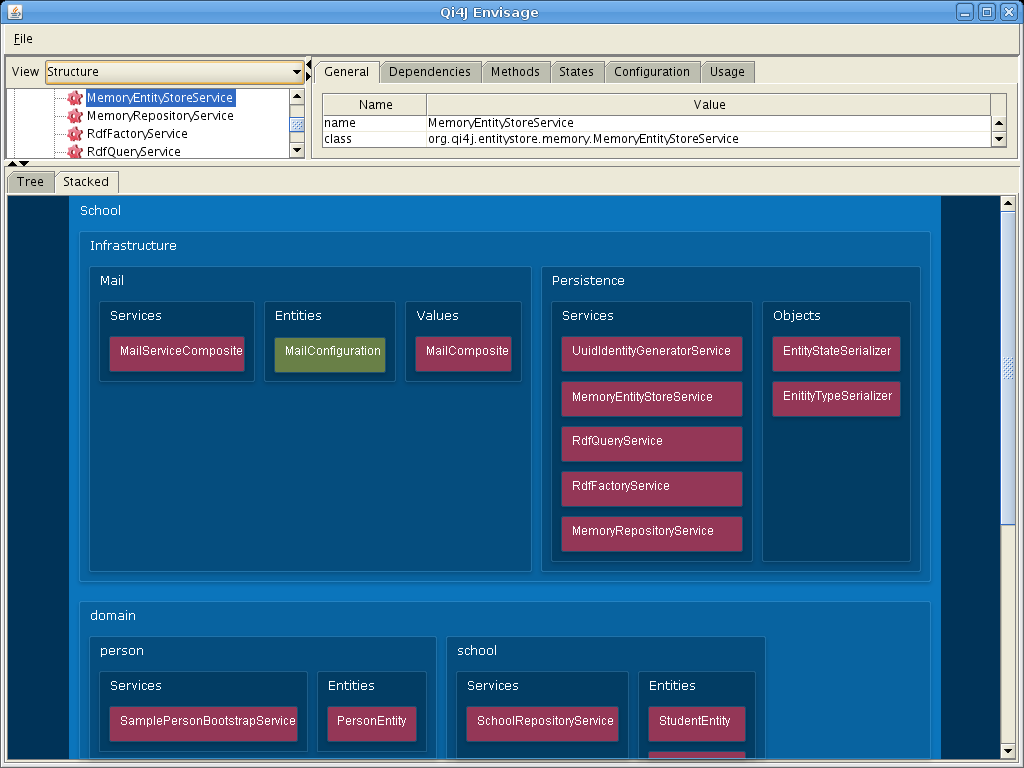
EntityViewer is a Swing based Entities browser. It allows you to browse Entities persisted in EntityStores.
EntityViewer can easily be used as follows:
new EntityViewer().show( qi4j.spi(), applicationModel, application );
A gradle task runSample is defined in this module as a shortcut to run the example. See Build System.
There are a lot of concepts in Qi4j which may have different meanings in other contexts. So in true DDD-style ubiquitous language, we are here listing the definitions of the terms and concepts that are being used.
- Abstract Mixin
An Abstract Mixin is an implementation of the MixinType interface, but is an abstract class and has not implemented all the methods.
The Qi4j runtime can use multiple Mixins for each MixinType interface. It is also possible to let a Generic Mixin handle the remaining missing methods.
- Abstract Modifier
Abstract Modifiers are Modifiers that do not implement all the methods of the MixinType interface.
This works essentially in the same manner as the Abstract Mixin. And the methods that are not implemented will not be part of the Invocation Stack of those methods.
- Application
Application is the top level concept handled by the Qi4j runtime instance. It holds the information about the Layers in the application architecture. See Structure for more information.
There is one and only one Application instance per Qi4j Runtime instance.
- Application Mode
During the Bootstrap phase an Application is given a Mode that can be test, development, staging or production.
See Assembly.
- Association
An Association is a reference to an Entity Composite.
References to Entities must be maintained in Associations. It is illegal to define a Property with an Entity Composite as its type.
- Composite
A Composite is an instance of a Composite Type.
However, we often speak of Composites when we actually mean CompositeType, similarly as we often speak of objects when we really are talking of classes in OOP.
- Composite Context
A Composite Context is a mechanism to separate the state of a TransientComposite across two or more threads. If a thread modifies a value, only that thread will see the changes, another thread will have its values protected by the thread boundaries. Use-cases for this include user credentials on which behalf the thread is executing.
- Composite Meta Type
There are 5 Composite Meta Types defined in Qi4j, which each share the composition features but have distinct semantic differences.
- Entity Composite
- ValueComposite
- Service composite
- Configuration Composite (subtype of EntityComposite)
- TransientComposite
- Composite Type
CompositeType is the Java interface that declares the composition, from which Composite instances can be created.
Composite Type interfaces must be a sub-type of one of the 5 Composite Meta Types defined in Qi4j otherwise it can not be instantiated.
- Concern
A concern is a stateless Fragment, shared between invocations, that acts as an interceptor of the call to the Mixin. The Concern is a Java class, that either implements the MixinType it can be used on, or java.lang.reflect.InvocationHandler which allows it to be used on any arbitrary MixinType.
Concerns have many purposes, but they are not intended to produce side effects (see SideEffect). Use-cases involves;
- Transaction handling.
- Call Tracing.
- User security.
Concerns are established by the use of the @Concerns annotation on composites.
Concern is one of the 3 kinds of Modifiers defined in Qi4j.
- Configuration Composite
Service Composites can have configuration associated to it and that is done via Configuration Composites, which are a subtype of Entity Composite, as they are stored permanently in configured Entity Stores. Configuration Composites are also initialized automatically from properties files first time. Note that on consequent start-ups the properties file is not read, as the configuration is read from the EntityStore.
ConfigurationComposite is one of the 5 Composite Meta Types defined in Qi4j.
See Configure a Service to learn how to use Configuration Composites.
- Constraint
Constraints are a kind of validators, which are consulted prior to invoking the method call. Qi4j currently only supports ParameterConstraints on methods and value constraints on Properties, but future versions will include Constraint types for checking complete method calls and return values.
See Constraint for better understanding of its details.
See Constraints Library for ready to use Constraints.
See Create a Constraint to learn how to write your own Constraints.
Constraint is one of the 3 kinds of Modifiers defined in Qi4j.
- Entity Composite
An Entity Composite, or just Entity for short, is a persisted composite with an Identity. An entity only has scope within an UnitOfWork and is therefor inherently thread-safe.
EntityComposite is one of the 5 Composite Meta Types defined in Qi4j.
- Fragment
A part of the implementation of a Composite. There are 4 fragment types:
- Generic Fragment
Generic Fragments are Fragments that implements java.lang.reflect.InvocationHandler and potentially capable of being used for all MixinTypes. This is the direct opposite of the Typed Fragments, which implements the MixinType interface.
- Generic Mixin
A Generic Mixin implements the java.lang.reflect.InvocationHandler. The invoke() method will be called for all MixinType methods that the Mixin has been matched with, through the matching rules.
It is potentially possible that the Generic Mixin also implements the MixinType interface. In that case, the concrete methods will be called, but if the Mixin is also an abstract class, then the invoke() method will be called for the methods that has been match but are not present.
- Identity
TODO
This term has no definition yet. Learn how to contribute in Writing Documentation.
- Invocation Stack
For each method, Qi4J will create and re-use an Invocation Stack. It will be built with the sequence of Modifiers and an end-point that will link into the stateful Mixin.
It is important to recognize that, for memory footprint reasons, Invocation Stacks are shared across Composites of the same Composite Type. They are however thread-safe, in that Qi4j will never bind the same Invocation Stack to more than one Composite instance during a method call, but that between method invocations the Modifiers in the Invocation Stack can not assume that it is bound to the same Composite instance. Therefor, Modifiers are not expected to keep state between method invocations, and when it needs to do that, then it should reference a Mixin via the @This annotation. Qi4j will during the binding of the Invocation Stack to the Composite, also ensure that all referenced Mixins are correctly injected in the Invocation Stack.
- Layer
Qi4j promotes a Layered application design, where Layers can only access lower Layers and not higher Layers or Layers at the same level.
- ManyAssociation
TODO
This term has no definition yet. Learn how to contribute in Writing Documentation.
- MetaInfo
TODO
This term has no definition yet. Learn how to contribute in Writing Documentation.
- Mixin
The Mixin is the instance providing the stateful representation of the MixinType. This can either be a class implementing the MixinType or a java.lang.reflect.InvocationHandler that is generic to handle any or a subset of MixinType.
- MixinType
The MixinType is the static type of a part of the Composite. The MixinType is an interface that defines the methods to be exposed in the Composite.
- Modifier
Modifiers are stateless interceptors of method calls, that forms an Invocation Stack. The top of the Invocation Stack is linked to the Composite invocation handler and the bottom of the Invocation Stack is linked to the Mixins. Invocation Stacks are shared, so Modifiers must assume that the member fields will only be valid within a single method invocation.
There are 3 kinds of Modifiers;
- Module
Modules defines the scope of the Composites. Modules are wired with Assemblies, and can expose Composites as visible. Non-visible Composites are not reachable from other Modules.
- Private Mixin
When a @This injection refers to a MixinType which is not extended by the Composite Type the former becomes a private MixinType.
- Property
TODO
This term has no definition yet. Learn how to contribute in Writing Documentation.
See the Leverage Properties how-to.
- Service Composite
Service Composite is a subtype of Composite, and has a range of features built into it.
ServiceComposite is one of the 5 Composite Meta Types defined in Qi4j.
See the Service Composite chapter.
- SideEffect
A side effect is a stateless Fragment, shared between invocations, that acts as an interceptor of the call to the Mixin. The SideEffect is a Java class, that either implements the MixinType it can be used on, or java.lang.reflect.InvocationHandler which allows it to be used on any arbitrary MixinType.
SideEffects are executed after the completion of the method invocation and therefore cannot change parameters nor eventually returned object.
SideEffects have many purposes. Use-cases involves;
- Sending emails.
- Call Tracing.
- Domain side effects modeling.
SideEffects are established by the use of the @SideEffects annotation on composites.
SideEffect is one of the 3 kinds of Modifiers defined in Qi4j.
- Structure
Qi4j promotes a conventional view of application structure, that computer science has been using for decades.
The definition is as follows;
- One Application per Qi4j runtime instance.
- One or more Layers per Application.
- Zero, one or more Modules per Layer.
- Zero, one or more Assemblies per Module.
The principle of this Structure is to assist the programmer to create well modularized applications, that are easily extended and maintained. Qi4j will restrict access between Modules, so that code can only reach Composites and Objects in Modules (including itself) of the same or lower Layers.
Each Layer has to be declared which lower Layer(s) it uses, and it is not allowed that a lower Layer uses a higher Layer, i.e. cyclic references.
- TransientComposite
TransientComposite is a Composite Meta Type for all other cases. The main characteristics are;
- It can not be serialized nor persisted.
- hashcode/equals are not treated specially and will be delegated to Fragment(s) implementing those methods.
- It can not be used as a Property type.
- UnitOfWork
TODO
This term has no definition yet. Learn how to contribute in Writing Documentation.
- ValueComposite
Usage of value objects is one of the most ignored and best return-on-investment the programmer can do. Values are immutable and can be compared by value instead of memory reference. Concurrency is suddenly not an issue, since either the value exists or it doesn’t, no need for synchronization. Values are typically very easy to test and very robust to refactoring.
Qi4j defines values as a primary meta type through the ValueComposite, as we think the benefits of values are great. The ValueComposite is very light-weight compared to the Entity Composite, and its value can still be persisted as part of an Entity Composite via a Property.
The characteristics of a ValueComposite compared to other Composite Meta Types are;
- It is Immutable.
- Its equals/hashCode works on the values of the ValueComposite.
- Can be used as Property types, but will not be indexed and searchable.