イントロダクション¶
SINGAは、大規模なデータ分析の為のディープラーニングモデルのトレーニングを目的とした「分散ディープラーニング・プラットフォーム」です。 モデルとなるネットワークの「レイヤー」概念に基づき、直感的にプログラミングできるようデザインされています。
- Convolutional Neural Network (畳み込みニューラルネットワーク) のようなフィードフォワードネットワークや、Restricted Boltzmann Machine (制限ボルツマンマシン) のようなエネルギーモデル、Recurrent Neural Network (再帰型ニューラルネットワーク) モデル等、多様なモデルをサポートします。
- 様々な「レイヤー」が、Built-in Layer として実装されています。
- SINGAのアーキテクチャーは、synchronous (同期)、asynchronous (非同期)、そして hybrid (ハイブリッド) トレーニングを実行できるよう設計されています。
- 大規模なモデルのトレーニングを並列化するための、ニューラルネットワーク分割スキーム (バッチや特徴の分割) をサポートしています。
目的¶
拡張性:分散システムとして、より多くのリソースを利用し、特定の精度に達するまでのトレーニングスピードを向上させる。
使いやすさ:大規模な分散モデルの効率的なトレーニングに必要となる、データやモデルの分割、ネットワーク通信等、プログラマーにとって時間のかかる作業を簡略化し、ディープで複雑なモデルやアルゴリズムの実装を容易にする。
設計理念¶
スケーラビリティは、分散ディープラーニングにおいて重要な研究課題です。 SINGAは、様々なトレーニングフレームワークのスケーラビリティーを保てるようよう設計されています。
- Synchronous (同期):トレーニングの1ステップで得られる効果を高めます。
- Asynchronous (非同期):トレーニングの収束率を高めます。
- Hybrid (ハイブリッド):コストやリソース(クラスターサイズ等)に合った効果と収束率のバランスをとり、スケーラビリティーを高めます。
SINGAは、ディープラーニングモデルのネットワークの「レイヤー」概念に基づき、直感的にプログラミング出来るようデザインされています。様々なモデルを実装しトレーニングできます。
システム概要¶
 Figure 1 - SGD フロー
Figure 1 - SGD フロー
「ディープラーニングモデルをトレーニングする」とは、 特定のタスク(分類、予測等)を達成するために使われる特徴量を生成する変換関数の最適なパラメターを探すことです。 パラメターの良し悪しは、Cross-Entropy Loss 等の loss function (損失関数)で判断します。この関数は一般的に非線形、または非凸関数なので、閉解を探すのが難しいです。
そこで、Stochastic Gradient Descent (確率的勾配降下法) を利用します。 Figure 1 のように、ランダムに初期化されたパラメーターの値を、損失関数が小さくなるよう繰り返しアップデートしていきます。
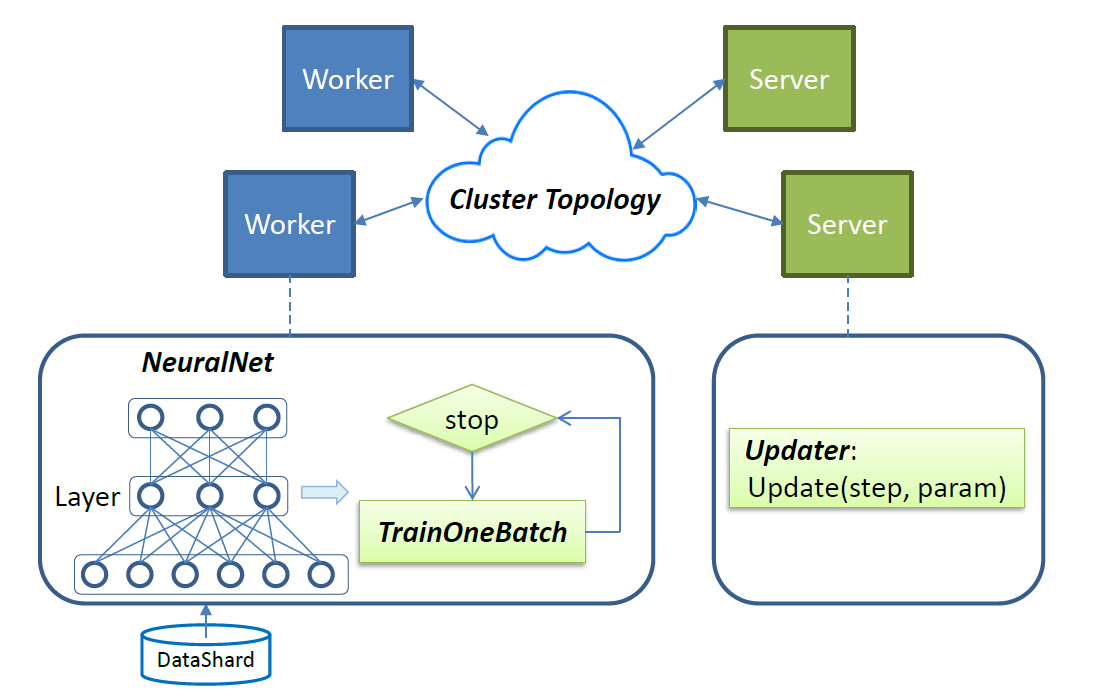 Figure 2 - SINGA 概要
Figure 2 - SINGA 概要
トレーニングに要するワークロードは、workers と servers に分散されます。Figure 2 のように、ループ毎に workers は TrainOneBatch 関数を呼び、パラメーター勾配を計算します。 TrainOneBatch は、ニューラルネットワークの構造が記述された NeuralNet オブジェクトに基づいて、「レイヤー」を順に見て回ります。 計算された勾配はローカルノードの stub に送られ、集計された後、対応する servers に送られます。Servers は、アップデートされたパラメーターを workers に送り返し、次のループを実行します。
ジョブ¶
SINGA の「ジョブ」とは、ニューラルネットワークモデルとデータ、トレーニング方法やクラスタートポロジー等が記述された、「Job Configuration」を指します。 Job Configurationは、Figure 2に描かれた次の4つのコンポネントを特定します。
- NeuralNet:ニューラルネットワークの構造と、各「レイヤー」の設定を記述します。
- TrainOneBatch:異なるモデルカテゴリに適したアルゴリズムを記述します。
- Updater: パラメーターのアップデート方法を記述します。
- Cluster Topology:workers と servers の分散トポロジーを記述します。
main 関数の SINGA ドライバにジョブを渡します。
このプロセスは、Hadoopでのジョブサブミッションに似ています。 ユーザーが main関数内でジョブの設定をします。 Hadoopユーザーは、自身の mapper や reducer を設定しますが、SINGAユーザーは、自身の「レイヤー」やUpdater等を設定します。

