I'm a visual type of guy. I love to see things, I love to visualize them, hopefully in esthetically pleasant ways. I'm also fascinated by human dynamics and sociology. For these reasons, I started about the shape of a virtual community and if it was possible to come up with ways to harvest the data as transparently as possible about communities of invididuals and how to visualize this incredible amount of information so that it can yield insights that were hard to see before.
Advogato is a social experiment on trust. It analizes topologies of trust information to come up with a tamper-proof way to estimate how trustful a person might be in a particular social context. This inspired me to create a system that was able to provide the people around the ASF a way to discover their social relationships.
Google is a search engine which
bases his page ranking techniques on hyperlink topology analysis. This
inspired me the concept that while trends in a small scale would be too
small to be appreciated, on a global scale might provide amazing
insights into the information that exhibits them. I call this concept
"data emergence".
The concept of blogging ecosystems (kudos to Sam Ruby for pointing me to this) inspired me against the use of a central web application (as Advogato does) in favor of a more 'laissez-faire' approach that doesn't force people to use any particular technology to express social relationships but just using hyperlinks to their homepages, just like the blogging community does. This allows people to use whatever tool/system/technology to come up with their homepages and doesn't impose them anything if not just to link to the other ASF people they know and like.
Unfortunately, unlike blogging fans, individuals that participate in apache communities use email as their favorite communication tool and therefore most of the social relationship data is contained into mail archives. (kudos to Ben Laurie for suggesting me this)
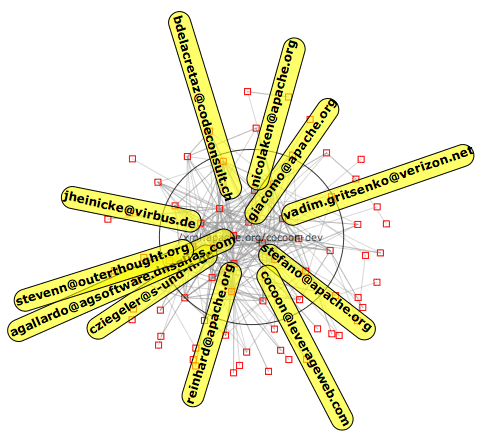
The basic idea is that every time you reply to somebody's message, you are creating a social relationship between you and that person.
That's more or less it.
Yes, really, I mean it: we are used to think at mail list archives
as flat lists of messages (date view, author view) or, in more
advanced visualizations, as trees of replies (thread view). But a tree
is only one of the possible ways to visualize the information contained
into the concept of one message
replying to another. In fact, this act of replying is a relation
between two otherwise independent messages.
In my quest to remove any of my personal judgements (or algorithmical heuristics) I wondered how it was possible to visualize the shape of a community on a 2D space but without any human interaction, so instead of coming up with a static image rendering technique, I opted for a run-time interactive molecular-style simulation where a simple model describes the behavior of a single molecule (the person, in our case) and how it interacts with others in the same environment.
The basic idea for the community simulation is that every individual has the perception of a private space that surrounds him/her and his/her level of confort is reduced if this space is violated by living entities (humans beings or animals) that are not recognized (this can be easily identified as an instinctive protection system).
Modelling this behavior in a human being is almost impossible given the amount of variables that influence it (culture, age, personal history, mood, health), so I decided to use a very basic and static model where each individual is treated exactly the same. I'm perfectly aware that this is a pretty strong assumption of the model, but I had to start somewhere.
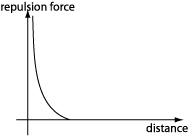
The math model of this private space is done by the creation of a repulsive force field that can pictured in the following graph:
This graphs means that after a safe distance, there is no repulsion
force between two individuals, so they are free to move as long as they
remain outside this safe circle. When this space is invaded, the perceived tension is
expressed with a tendency to repulse the offending intruder and restore
the original safe distance. The closer the distance, the more intense
the repulsion will be.
Social relationships are equivalentely complex to describe, given their incredible variety. Again, a very basic force field model is applied. The idea is to model social relationships with an attraction force field which can be pictured as in the following graph:
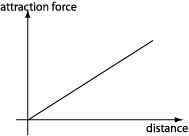
where the slope of the force/distance line represents the 'intensity' of the relation. Here, the attractive tension is resolved when the distance between individuals is zero. This might seem a little unnatural at first, but it makes sense if we consider that the repulsion force field is still present, even when a relationship is established. In fact, the pulsion of attraction and the defensive tendency of repulsion create two counter-balancing forces that create a fed-back mechanism to equilibrate the relationship.
It is also nice to note that if only one of the two individuals exhibits attraction (or if the attraction intensities are not balanced), there is no point of equilibrium and the couple will tend to move. Thus while stability is a sign of relational balance, movement is a sign of lack of ballanced attraction.

The application is divided into two regions:
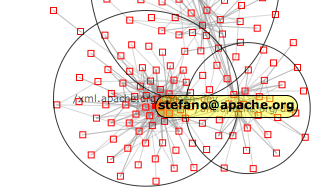

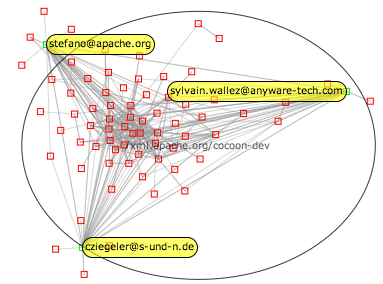
If the graph is complex and contains lots of node and edges, the
drawing might be slow. Use the "Drawing" tab to remove edges and speed
up drawing until the graphs have stabilized.
You can also play with the "Parameters" tab to provide different
physical parameters (such as mass of the node, drag of the surface, and
repulsion or attraction coefficients) to change the behavior of the
graph (in some big graphs, in fact, the system might become unstable
and sweaking the parameters might be necessary).
The MBOX processing script is written in Python. The visualization engine is
written in Java. It's both an
applet and a
standalone application. The java application is selfcontained,
optimized for speed and size. Uses Java2D for drawing and it is
hardware optimized in those JVM that support this (like under MacOSX).
I see a few, both technological and social. Technologically, the
problem will not be able to scale easily since the computational
complexity of the mathematical model used grows with the square of the
amount of nodes involved (N*N). This is very similar to the math
problem
that molecular chemists face when they have to visualize the exact
shape
of complex molecules. There are no known (to me, at least)
algorithmical
methods to reduce that computational complexity down to, say, N*log(N)
which would be much more reasonable. If you know more, I want to hear
from you!
Another challenge is to find out how to collapse different email
addresses used by the same person so that data is more meaningful.
Today, the data is harvested by using the email address as a unique
key.
In the future, the goal is to either harvest this information somewhere
and somehow trasparently, or to have a database where users indicate
the
system which addresses belong to them, so that the dataclouds can be
renormalized on that respect. It can be possible to process .forward
files from a given user domain (the ASF, for example), but this raises
privacy concerns.
Another technical challenge (kudos to Pier Fumagalli for
pointing this out) is to parallelize the symulation routine on
different
threads so that multi-processor machines can really execute the
application in parallel. While this degrades performance on a
single-processor machine (althought not by much), it speeds it up
incredibly on a multi-processing one. Since I estimate that today the
overall ASF datacloud might account for something around 15000/20000
nodes (that is, emal addresses that had a significant replying impact
on
any ASF community), it might not be possible to actually play with it
realtime, but at least it could be possible to run the application in
background for several weeks and see what happens. For this, we really
need to go multiprocessor.
People have an automatic repulsion
toward any mathematical model that tries to observe and simulate human
behavior. While this is understandable, it must also be acknowledged
how
the simple analysis of human-created hyperlink topologies created the
most successful search engine system (Google) and how it's
human-semantic inferrence that leads to the perception of its smartness. I humbly try to follow
the same model: avoid heuristical analysis and concentrate on
extraction
of human-inferred metadata (in this case, replying is agora's metadata,
where hyperlinking is google's).
At the same time, Agora does NOT want to be a measurement tool for
virtual communities and users should not rely only on Agora-inferred
data on how a community behaves or various communities interact.
Last but not least, while Agora discards information on the content
of the email messages, even its metadata can create security concerns.
Analyzing somebody else's email without his permission is unethical and
illegal in many countries: make sure you have permission from the email
senders before analyzing them.
For example, analyzing email messages that were posted on a public
mail list, newsgroup, BBS or forum and publicly made available is
perfectly legal. Processing your employers mailbox without telling
them, well, that's not, unless they gave you explicit permission.
Anyway, under no circumstance, the Apache Software Foundation will
be liable for abuse of its software, as explicitly stated in the
license upon which Agora is distributed.
Why the name Agora?
The terms originates in ancient greece and can be described such as
A central feature of the polis. Originally a marketplace, the agora also served as the chief social and political meeting place. Along with the acropolis (the upper fortified part of a city), the agora housed the most important buildings of the city-state. [original]
I thought that the visualizer can be seen as the view from above of
a virtual meeting place where all individuals are gathered into a
location.
Why is it hosted here and not in a
more public apache location?
Just because I didn't know where to put it and wanted to hear feedback
before doing anything. I'll be very happy to move it on a more visible
location if this desire appears.
Can I run Agora on my own mail
lists?
Sure, Agora is not bound in any way with Apache or Apache-specific
data. Agora is able to generate dataclouds of any collection of MBOX
mail archives.
Do you know any similar efforts?
Paul Mutton independently applied similar concepts of reply means social connection on IRC channels for PieSpy.
[Kudos to Nicola Ken Barozzi for forwarding me the link]
Copyright © 2002-2003 Apache Software Foundation. All Rights Reserved.