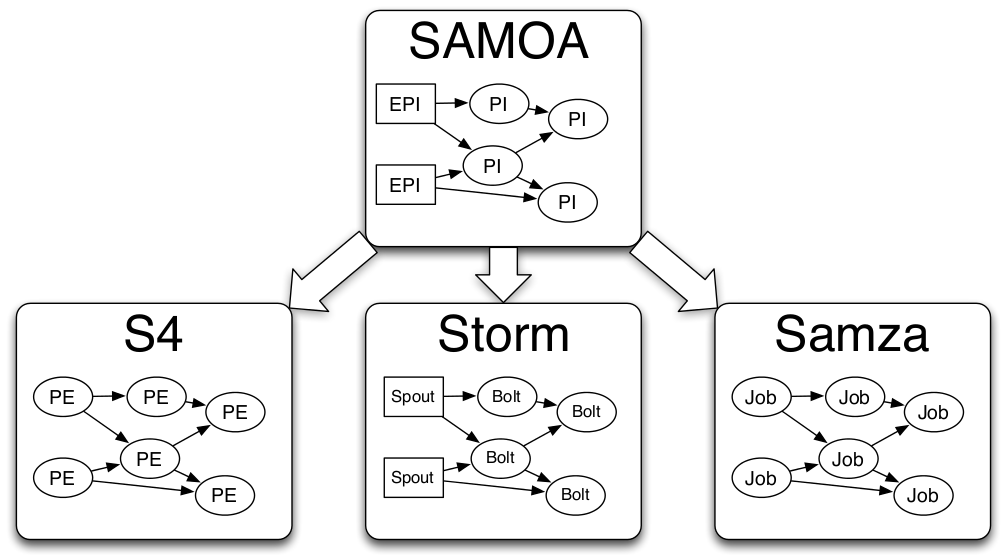
Apache SAMOA
Scalable Advanced Massive Online Analysis
Apache SAMOA is currently undergoing incubation at the Apache Software Foundation. Latest source release: 0.4.0-incubating View on GitHub.


Go to the folder where you want to store your project, and clone the new repository:
~$git clone http://git.apache.org/incubator-samoa.git
~$cd incubator-samoa
~$mvn -Pstorm package
The deployable jar for Apache SAMOA will be in target/SAMOA-Storm-0.4.0-SNAPSHOT.jar.
If you want to compile Apache SAMOA for S4, you will need to install the S4 dependencies manually as explained in Executing Apache SAMOA with Apache S4.
~$git clone http://git.apache.org/incubator-samoa.git
~$cd incubator-samoa
~$mvn -Ps4 package
The deployable jar for Apache SAMOA will be in target/SAMOA-S4-0.3.0-SNAPSHOT.jar.
Go to the folder where you want to store your project, and clone the new repository:
~$git clone http://git.apache.org/incubator-samoa.git
~$cd incubator-samoa
~$mvn -Psamza package
The deployable jar for Apache SAMOA will be in target/SAMOA-Samza-0.4.0-SNAPSHOT.jar.
If you want to test Apache SAMOA in a local environment, simply clone the repository and install Apache SAMOA.
~$git clone http://git.apache.org/incubator-samoa.git
~$cd incubator-samoa
~$mvn package
The deployable jar for Apache SAMOA will be in target/SAMOA-Local-0.4.0-SNAPSHOT.jar.
~$git clone http://git.apache.org/incubator-samoa.git
~$cd incubator-samoa
~$mvn package
If you want to compile Apache SAMOA for S4, you will need to install the S4 dependencies manually as explained in Executing Apache SAMOA with Apache S4.
~$wget "http://downloads.sourceforge.net/project/moa-datastream/Datasets/Classification/covtypeNorm.arff.zip"
~$unzip covtypeNorm.arff.zip
Forest Covertype contains the forest cover type for 30 x 30 meter cells obtained from the US Forest Service (USFS) Region 2 Resource Information System (RIS) data. It contains 581,012 instances and 54 attributes, and it has been used in several articles on data stream classification.
Classifying the CoverType dataset with the bagging algorithm
~$bin/samoa local target/SAMOA-Local-0.4.0-SNAPSHOT.jar "PrequentialEvaluation -l classifiers.ensemble.Bagging -s (ArffFileStream -f covtypeNorm.arff) -f 100000"
The output will be a list of the evaluation results, plotted each 100,000 instances.