How to configure S4 clusters and applications
S4 provides a set of tools to:
s4 newCluster
s4 node
s4 s4r
s4 deploy
s4 zkServer
s4 zkServer -t will start a Zookeeper server and automatically configure 2 clusterss4 status
s4 will give you a list of available commands../s4 <command> -help will provide detailed documentation for each of these commands.Before starting S4 nodes, you must define a logical cluster by specifying:
The cluster configuration is maintained in Zookeeper, and can be set using S4 tools:
./s4 newCluster -c=cluster1 -nbTasks=2 -flp=12000
See tool documentation by typing:
./s4 newCluster -help
Platform code and application code are fully configurable, at deployment time.
S4 nodes start as simple bootstrap processes whose initial role is merely to connect the cluster manager:
This figure illustrates the separation between the bootstrap code, the S4 platform code, and application code in an S4 node:
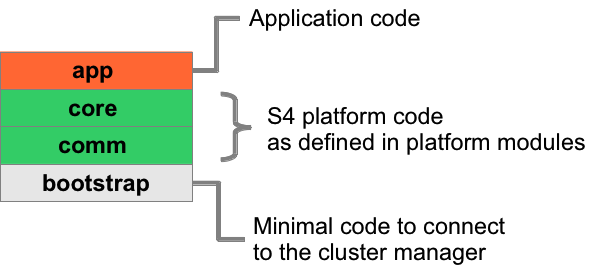
Therefore, for starting an S4 node on a given host, you only need to specify:
localhost:2181 by defaultExample:
./s4 node -c=cluster1 -zk=host.domain.com
By default, nodes read configuration from configuration files in the classpath default.s4.base.properties, default.s4.comm.properties and default.s4.core.properties.
It is possible to override these parameters by using the -p option when starting a node.
Deploying applications is easier when we can define both the parameters of the application and the target environment.
In S4, we achieve this by specifying both application parameters and S4 platform parameters in the deployment phase :
S4 follows a modular design and uses Guice for defining modules and injecting dependencies.
As illustrated above, an S4 node is composed of: * a base module that specifies how to connect to the cluster manager and how to download code * a communication module that specifies communication protocols, event listeners and senders * a core module that specifies the deployment mechanism, serialization mechanism * an application
For the comm module: communication protocols, tuning parameters for sending events
For the core module, there is no default parameters.
We provide default modules, but you may directly specify others through the command line, and it is also possible to override them with new modules and even specify new ones (custom modules classes must provide an empty no-args constructor).
Custom overriding modules can be specified when deploying the application, through thedeploy command, through the emc or modulesClasses option.
For instance, in order to enable file system based checkpointing, pass the corresponding checkpointing module class :
./s4 deploy -s4r=uri/to/app.s4r -c=cluster1 -appName=myApp \
-emc=org.apache.s4.core.ft.FileSystemBackendCheckpointingModule
You can also write your own custom modules. In that case, just package them into a jar file, and specify how to fetch that file when deploying the application, with the mu or modulesURIs option.
For instance, if you checkpoint through a specific key value store, you can write you own checkpointing implementation and module, package that into fancyKeyValueStoreCheckpointingModule.jar , and then:
./s4 deploy -c=cluster1 -emc=my.project.FancyKeyValueStoreBackendCheckpointingModule \
-mu=uri/to/fancyKeyValueStoreCheckpointingModule.jar
A simple way to pass parameters to your application code is by:
@Inject
@Named("thePortNumber")
int port-p inline with the node command, or with the ‘@’ syntax)S4 uses an internal Guice module that automatically injects configuration parameters passed through the deploy command to matching @Named parameters.
Both application and platform parameters can be overriden. For instance, specifying a custom storage path for the file system based checkpointing mechanism would be passing the s4.checkpointing.filesystem.storageRootPath parameter:
./s4 deploy -s4r=uri/to/app.s4r -c=cluster1 -appName=myApp \
-emc=org.apache.s4.core.ft.FileSystemBackendCheckpointingModule \
-p=s4.checkpointing.filesystem.storageRootPath=/custom/path
Make sure you pass overriding platform parameters through the
-poption in thenodecommand, and pass application parameters through the-poption in thedeploycommand.
Instead of specifying node parameters inline, you may refer to a file with the ‘@’ notation:
./s4 deploy @/path/to/config/file
With contents of the referenced file like:
-s4r=uri/to/app.s4r
-c=cluster1
-appName=myApp
-emc=org.apache.s4.core.ft.FileSystemBackendCheckpointingModule
-p=param1=value1,param2=value2
S4 uses logback, and here is the default configuration file. You may tweak this configuration by adding your own logback.xml file in the lib/ directory (for a binary release) or in the subprojects/s4-tools/build/install/s4-tools/lib/ directory (for a source release or checkout from git).