Please note that this documentation specifies the plans we have, rather than what we actually do right now. The key difference is that Gump will be made much more intelligent about whom to send what e-mail and what to put in those e-mails. However, the basic ideas for all this are quickly falling into place.
Lets start with the low-level overview. Gump has two main parts. The first part takes care of actually performing the build. Internally, we tend to call this part "Gumpy", since its written in python. The second part takes care of the reporting and introspection. It is written in java using Apache Cocoon.
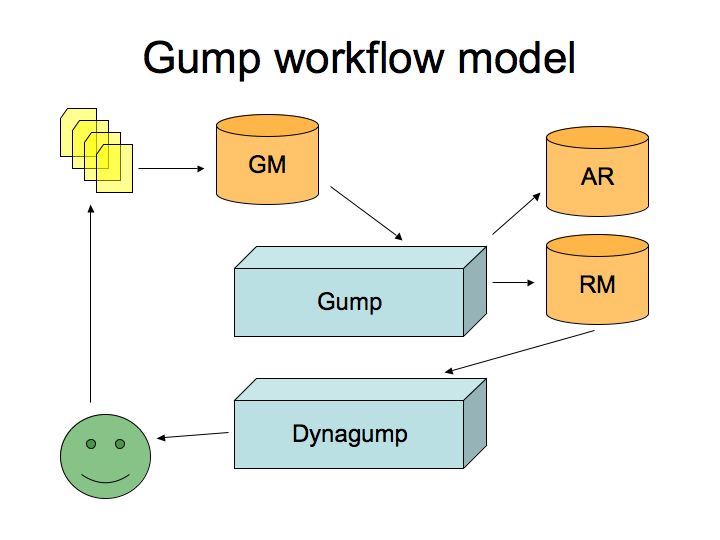
Gumpy is a python script that is fired from cron every few hours. It does some self-initialization, looks at it environment, then starts figuring out what to do. It updates the gump CVS and SVN repositories. The next task is to read in all gump project definitions. For maven-based projects, we read in maven's project.xml files and do some processing on those. For projects using other build tools (like Ant), an XML descriptor describing that project is kept in the Gump subversion repository.
All these project definitions are merged into a database, which we call the GumpModelDatabase. Once our database is filled, we start walking it to figure out the dependencies between all the projects. We then figure out a build order. With our model serialized, we know exactly what to do.
In our just-determined order, we run CVS or SVN updates for our projects, then try to build them (using ant or maven). The precise build commands to use as well as any environment settings (such as references to installed packages like javamail) are all figured out from the gump project definitions (see HowToGetBuiltByGump for more information on how that works).
Now, the tricky bit is specifying dependencies. Rather than use the maven repository or some other place where jars are stored, we set the system classpath to include all the dependencies declared for a project. And rather than point to a specific versioned jar or library, we opt to use the output of the projects that we just built straight from bleeding edge SVN.
Gumpy keeps track of everything it does, and what the results of those actions are. Success and failure states, build logs, and much more are all saved and stored into another database, which we call the ResultMetadataDatabase. This database doesn't just store the current run, but maintains information for all previous runs as well.
If a project fails to build, Gumpy will take special actions to try and figure out what caused that failure. The algorithm used to do this is based on a bit of graph theory, which won't be described here. Interested people should look at the GumpAlgorithm page. (NOTE: this algorithm has been written but not yet implemented!) Suffice saying that Gumpy is often able to determine exactly which CVS or SVN commit caused the build failure, and in other instances is able to give a good hint.
Once Gumpy is done, its time for DynaGump to do its thing. DynaGump is a web application which hooks into the ResultMetadataDatabase to generate reports. These reports allow anyone to find out how stable the build for a particular project is, what the main issues are, and the like. We produce figures describing the build history of a project. This can help developers figuring out which dependencies are causing them problems, but also how their changes affect the projects that depend on them (their dependees).
If there's an issue, DynaGump figures out who needs to know about that and sends them e-mail. For example, if a project introduced a code change that results in one or more of their dependees failing to build, we'll let that project know, as well as the project that broke. This allows all the developers involved to start collaborating immediately to resolve the issue.
Advanced reporting and workflow features (similar to the Jira Dashboard) feature will be made available. For example, you will be able to create a custom page which lists information about all the projects that you are interested in, or get that information as an RSS feed.