The AbstractTranslet class has a global hashtable that holds
an index for each named key in the stylesheet (hashing on the "name"
attribute of <xsl:key>). AbstractTranslet
has a couple of public methods for inserting and retrieving data from this
hashtable:
 | | |
|
public void buildKeyIndex(String keyName, int nodeID, String value);
public KeyIndex KeyIndex getKeyIndex(String keyName); | |
| | |
The Key class compiles code that traverses the input DOM and
extracts nodes that match some given parameters (the "match"
attribute of the <xsl:key> element). A new element is
inserted into the named key's index. The nodes' DOM index and the value
translated from the "use" attribute of the
<xsl:key> element are stored in the new entry in the
index.
Something similar is done for indexing IDs. This index is generated from
the ID and IDREF fields in the input document's
DTD. This means that the code for generating this index cannot be generated
at compile-time, which again means that the code has to be generic enough
to handle all DTDs. The class that handles this is the
org.apache.xalan.xsltc.dom.DTDMonitor class. This class
implements the org.xml.sax.XMLReader and
org.xml.sax.DTDHandler interfaces. A client application using
the native API must instanciate a DTDMonitor and pass it to the
translet code - if, and only if, it wants IDs indexed (one can improve
performance by omitting this step). This is descrived in the
XSLTC Native API reference. The
DTDMonitor class will use the same indexing as the code
generated by the Key class. The index for ID's is called
"##id". We assume that no stylesheets will contain a key with this name.
The index itself is implemented in the
org.apache.xalan.xsltc.dom.KeyIndex class. The index has an
hashtable with all the values from the matching nodes (the part of the node
used to generate this value is the one specified in the "use"
attribute). For every matching value there is a bit-array (implemented in
the org.apache.xalan.xsltc.BitArray class), holding a list of
all node indexes for which this value gives a match:
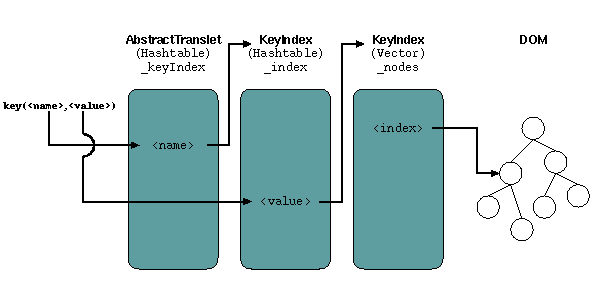
Figure 1: Indexing tables
The KeyIndex class implements the NodeIterator
interface, so that it can be returned directly by the implementation of the
key() function. This is how the index generated by
<xsl:key> and the node-set returned by the
key() and KeyPattern are tied together. You can see how this is
done in the translate() method of the KeyCall
class.
The key() function can be called in two ways:
| | |
|
key('key-name','value')
key('key-name','node-set') | |
| | |
The first parameter is always the name of the key. We use this value to
lookup our index from the _keyIndexes hashtable in AbstractTranslet:
| | |
|
il.append(classGen.aloadThis());
_name.translate(classGen, methodGen);
il.append(new INVOKEVIRTUAL(getKeyIndex)); | |
| | |
This compiles into a call to
AbstractTranslet.getKeyIndex(String name), and it leaves a
KeyIndex object on the stack. What we then need to do it to
initialise the KeyIndex to give us nodes with the requested
value. This is done by leaving the KeyIndex object on the stack
and pushing the "value" parameter to key(), before
calling lookup() on the index:
| | |
|
il.append(DUP); // duplicate the KeyIndex obejct before return
_value.translate(classGen, methodGen);
il.append(new INVOKEVIRTUAL(lookup)); | |
| | |
This compiles into a call to KeyIndex.lookup(String value).
This will initialise the KeyIndex object to return nodes that
match the given value, so the KeyIndex object can be left on
the stack when we return. This because the KeyIndex object
implements the NodeIterator interface.
This matter is a bit more complex when the second parameter of
key() is a node-set. In this case we need to traverse the nodes
in the set and do a lookup for each node in the set. What I do is this:
-
construct a
KeyIndex object that will hold the
return node-set
-
find the named
KeyIndex object from the hashtable in
AbstractTranslet
-
get an iterator for the node-set and do the folowing loop:
- get string value for current node
- do lookup in KeyIndex object for the named index
- merge the resulting node-set into the return node-set
-
leave the return node-set on stack when done