Table of Contents
- Introduction to Apache Rivet
- Apache Rivet Installation
- Rivet Apache Directives
- Rivet Tcl Commands and Variables
- Examples and Usage
- Rivet Tcl Packages
- DIO - Database Interface Objects
- DIODisplay - Database Interface Objects Display Class
- Session Package
- Resources - How to Get Help
- Rivet Internals
- Upgrading from mod_dtcl or NeoWebScript
This document is also available in the following languages: Italian, Russian
Document revision: $Revision: 532699 $, last modified $Date: 2007-04-26 12:50:39 +0200 (Thu, 26 Apr 2007) $ by $Author: davidw $.
Apache Rivet is a system for creating dynamic web content via a programming language integrated with Apache Web Server. It is designed to be fast, powerful and extensible, consume few system resources, be easy to learn, and to provide the user with a platform that can also be used for other programming tasks outside the web (GUI's, system administration tasks, text processing, database manipulation, XML, and so on). In order to meet these goals, we have chosen the Tcl programming language to combine with the Apache Web Server.
In this manual, we aim to help get you started, and then writing productive code as quickly as possible, as well as giving you ideas on how to best take advantage of Rivet's architecture to create different styles of web site.
This documentation is a work in progress, and, like everything else about Apache Rivet, it is Free Software. If you see something that needs improving, and have ideas or suggestions, don't hesitate to let us know. If you want to contribute directly, better yet!
Check Dependencies
To install Rivet, you will need Tcl 8.4 or greater and Apache 1.3.xx. It is known to run on Linux, FreeBSD, OpenBSD, and Solaris and HPUX. Windows NT is also possible - please see the directions in the distribution. Note that Rivet does not currently work with Apache 2.
Get Rivet
Download the sources at http://tcl.apache.org/rivet/download. Currently the only way to obtain Rivet. In the future, we hope to have a FreeBSD port, Debian package, RPM's, and windows binaries.
Install Tcl
If you don't have Tcl already, you need it! If you already have it, you should just be able to use your system Tcl as long as it is recent. You can tell Rivet where Tcl is via the -with-tclconfig option to configure.tcl (see below).
Get and Install Apache Sources
Rivet needs some Apache include (.h) files in order to build. The easiest way to get them is to download the source code of the Apache web server, although some systems (Debian GNU/Linux for example) make it possible to install only the headers and other development files. If you intend to build Rivet statically (compiled into the Apache web server instead of loaded dynamically), you definitely need the sources. We recommend that you build Rivet as a loadable shared library, for maximum flexibility, meaning that you also build Apache to be able to load modules. Other than that, the default Apache install is fine. We will tell Rivet where it is located via the -with-apxs option to configure.tcl (see below).
The source code for the Apache web server may be found by following the links here: http://httpd.apache.org/.
Uncompress Sources
We will assume that you have Apache installed at this point. You must uncompress the Rivet sources in the directory where you wish to compile them.
gunzip tcl-rivet-X.X.X.tar.gz tar -xvf tcl-rivet-X.X.X.tar.gz
Building Rivet
On Linux or Unix systems, Rivet uses the standard ./configure ; make ; make install technique.
There are several options to configure that might be useful or necessary:
- --with-tcl
- This points to the directory where the
tclConfig.shfile is located. - --with-tclsh
- This points to the location of the
tclshexecutable. - --with-apxs
- The location of the
apxsprogram that provides information about the configuration and compilation of Apache modules.
cd src/ ./configure --with-tcl=/usr/lib/tcl8.4/ --with-tclsh=/usr/bin/tclsh8.4 \ --with-apxs=/usr/bin/apxs
Run make
At this point, you are ready to run make, which should run to completion without any errors (a warning or two is ok, generally).
Install
Now, you are ready to run the make install to install the resulting files. This should copy the shared object (like
mod_rivet.so, if one was successfully created, into Apache'slibexecdirectory, as well as install some support scripts and various code.
Apache Configuration Files
Rivet is relatively easy to configure - we start off by adding the module itself:
LoadModule rivet_module
/usr/lib/apache/1.3/mod_rivet.soThis tells Apache to load the Rivet shared object, wherever it happens to reside on your file system. Now we have to tell Apache what kind of files are "Rivet" files and how to process them:
AddType application/x-httpd-rivet .rvt AddType application/x-rivet-tcl .tcl
These tell Apache to process files with the
.rvtand.tclextensions as Rivet files.You may also wish to use Rivet files as index files for directories. In that case, you would do the following:
DirectoryIndex index.html index.htm index.shtml index.cgi index.tcl index.rvt
For other directives that Rivet provides for Apache configuration, please see the section called “Rivet Apache Directives”.
These directives are used within the Apache httpd server configuration files to modify Apache Rivet's behavior. Their precedence is as follows: RivetDirConf, RivetUserConf, RivetServerConf, meaning that DirConf will override UserConf, which will in turn override ServerConf.
-
RivetServerConf (CacheSize | GlobalInitScript | ChildInitScript | ChildExitScript | BeforeScript | AfterScript | ErrorScript | UploadDirectory | UploadMaxSize | UploadFilesToVar | SeparateVirtualInterps)
- RivetServerConf specifies a global option that is valid for the whole server. If you have a virtual host, in some cases, the option specified in the virtualhost takes precedence over the 'global' version.
-
CacheSize ?
size? - Sets the size of the internal page cache, where
sizeis the number of byte-compiled pages to be cached for future use. Default is MaxRequestsPerChild / 5, or 50, if MaxRequestsPerChild is 0.This option is completely global, even when using separate, per-virtual host interpreters. -
GlobalInitScript ?
script? - Tcl script that is run when each interpreter is initialized.
scriptis an actual Tcl script, so to run a file, you would do:RivetServerConf GlobalInitScript "source /var/www/foobar.tcl"
This option is ignored in virtual hosts. -
ChildInitScript ?
script? - Script to be evaluated when each Apache child process is initialized. This is the recommended place to load modules, create global variables, open connections to other facilities (such as databases) and so on.In virtual hosts, this script is run in addition to any global childinitscript.
-
ChildExitScript ?
script? - Script to be evaluated when each Apache child process exits. This is the logical place to clean up resources created in ChildInitScript, if necessary.In virtual hosts, this script is run in addition to any global childexitscript.
-
BeforeScript ?
script? - Script to be evaluated before each server parsed (.rvt) page. This can be used to create a standard header, for instance. It could also be used to load code that you need for every page, if you don't want to put it in a GlobalInitScript ChildInitScript when you are first developing a web site.
![[Note]](images/note.png)
Note This code is evaluated at the global level, not inside the request namespace where pages are evaluated. In virtual hosts, this option takes precedence over the global setting. -
AfterScript ?
script? - Script to be called after each server parsed (.rvt) page.In virtual hosts, this option takes precedence over the global setting.
-
ErrorScript ?
script? - When Rivet encounters an error in a script, it constructs an HTML page with some information about the error, and the script that was being evaluated. If an ErrorScript is specified, it is possible to create custom error pages. This may be useful if you want to make sure that users never view your source code.In virtual hosts, this option takes precedence over the global setting.
-
UploadDirectory ?
directory? - Directory to place uploaded files.In virtual hosts, this option takes precedence over the global setting.
-
UploadMaxSize ?
size? - Maximum size for uploaded files.In virtual hosts, this option takes precedence over the global setting.
-
UploadFilesToVar (yes | no)
- This option controls whether it is possible to upload files to a Tcl variable. If you have a size limit, and don't have to deal with large files, this might be more convenient than sending the data to a file on disk.
-
SeparateVirtualInterps (yes | no)
- If on, Rivet will create a separate Tcl interpreter for each Apache virtual host. This is useful in an ISP type situation where it is desirable to separate clients into separate interpreters, so that they don't accidentally interfere with one another.This option is, by nature, only available at the global level.
-
-
RivetDirConf (BeforeScript | AfterScript | ErrorScript | UploadDirectory)
- These options are the same as for RivetServerConf, except that they are only valid for the directory where they are specified, and its subdirectories. It may be specified in Directory sections.
-
RivetUserConf (BeforeScript | AfterScript | ErrorScript | UploadDirectory)
- These options are the same as for RivetServerConf, except that they are only valid for the directory where they are specified, and its subdirectories.
- var — get the value of a form variable.
- upload — handle a file uploaded by a client.
- load_response — load form variables into an array.
- load_headers — get client request's headers.
- load_cookies — get any cookie variables sent by the client.
- load_env — get the request's environment variables.
- env — Loads a single "environmental variable" into a Tcl variable.
- include — includes a file into the output stream without modification.
- parse — parses a Rivet template file.
- headers — set and parse HTTP headers.
- makeurl — construct url's based on hostname, port.
- cookie — get and set cookies.
- clock_to_rfc850_gmt — create a rfc850 time from [clock seconds].
- html — construct html tagged text.
- incr0 — increment a variable or set it to 1 if nonexistant.
- parray — Tcl's parray with html formatting.
- abort_page — Stops outputing data to web page, similar in purpose to PHP's die command.
- no_body — Prevents Rivet from sending any content.
- escape_string — convert a string into escaped characters.
- escape_sgml_chars — escape special SGML characters in a string.
- escape_shell_command — escape shell metacharacters in a string.
- unescape_string — unescape escaped characters in a string.
Name
var, var_qs, var_post — get the value of a form variable.
Synopsis
Description
The var command retrieves information about GET or POST variables sent to the script via client request. It treats both GET and POST variables the same, regardless of their origin. Note that there are two additional forms of var: var_qs and var_post. These two restrict the retrieval of information to parameters arriving via the querystring (?foo=bar&bee=bop) or POSTing, respectively.
-
var get ?
varname? ??default?? - Returns the value of variable
varnameas a string (even if there are multiple values). If the variable doesn't exist as a GET or POST variable, the?default?value is returned, otherwise "" - an empty string - is returned. -
var list ?
varname? - Returns the value of variable
varnameas a list, if there are multiple values. -
var exists ?
varname? - Returns 1 if
varnameexists, 0 if it doesn't. -
var number
- Returns the number of variables.
-
var all
- Return a list of variable names and values.
Name
upload — handle a file uploaded by a client.
Synopsis
Description
The upload command is for file upload manipulation. See the relevant Apache Directives to further configure the behavior of this Rivet feature.
-
upload channel ?
uploadname? - When given the name of a file upload
uploadname, returns a Tcl channel that can be used to access the uploaded file. -
upload save ?
uploadname? ?filename? - Saves the
uploadnamein the filefilename. -
upload data ?
uploadname? - Returns data uploaded to the server. This is binary clean - in other words, it will work even with files like images, executables, compressed files, and so on.
-
upload exists ?
uploadname? - Returns true if an upload named ?uploadname? exists. This can be used in scripts that are meant to be run by different forms that send over uploads that might need specific processing.
-
upload size ?
uploadname? - Returns the size of the file uploaded.
-
upload type
- If the
Content-typeis set, it is returned, otherwise, an empty string. -
upload filename ?
uploadname? - Returns the filename on the remote host that uploaded the file.
-
upload names
- Returns the variable names, as a list, of all the files uploaded.
Name
load_response — load form variables into an array.
Synopsis
arrayName?Description
Load any form variables passed to this page into an array.Name
load_headers — get client request's headers.
Synopsis
array_name?Description
Load the headers that come from a client request into the provided array name, or use headers if no name is provided.
Name
load_cookies — get any cookie variables sent by the client.
Synopsis
array_name?Description
Load the array of cookie variables into the specified array name. Uses array cookies by default.
Name
load_env — get the request's environment variables.
Synopsis
array_name?Description
Load the array of environment variables into the specified array name. Uses array ::request::env by default.
As Rivet pages are run in the ::request namespace, it isn't necessary to qualify the array name for most uses - it's ok to access it as env.
Name
env — Loads a single "environmental variable" into a Tcl variable.
Synopsis
varName?Description
If it is only necessary to load one environmental variable, this command may be used to avoid the overhead of loading and storing the entire array.
Name
include — includes a file into the output stream without modification.
Synopsis
filename_name?Description
Include a file without parsing it for processing tags <? and ?>. This is the best way to include an HTML file or any other static content.
Name
parse — parses a Rivet template file.
Synopsis
filename?Description
Like the Tcl source command, but also parses for Rivet <? and ?> processing tags. Using this command, you can use one .rvt file from another.
Name
headers — set and parse HTTP headers.
Synopsis
Description
The headers command is for setting and parsing HTTP headers.
- headers set ?
headername? ?value? - Set arbitrary header names and values.
-
headers redirect ?
uri? - Redirect from the current page to a new URI. Must be done in the first block of TCL code.
-
headers add ?
headername? ?value? - Add text to header
headername. - headers type ?
content-type? - This command sets the
Content-typeheader returned by the script, which is useful if you wish to send content other than HTML with Rivet - PNG or jpeg images, for example. -
headers numeric ?
response code? - Set a numeric response code, such as 200, 404 or 500.
Name
makeurl — construct url's based on hostname, port.
Synopsis
filename?Description
Create a self referencing URL from a filename. For example:
makeurl /tclp.gif
returns
http://[hostname]:[port]/tclp.gif.
where hostname and port are the hostname and port of the
server in question.
Name
cookie — get and set cookies.
Synopsis
cookieName? ??cookiValue?? ?-days expireInDays? ?-hours expireInHours? ?-minutes expireInMinutes? ?-expires Wdy, DD-Mon-YYYY HH:MM:SS GMT? ?-path uriPathCookieAppliesTo? ?-secure 1/0?cookieName?Description
cookie gets or sets a cookie. When you get a cookie, the command returns the value of the cookie, or an empty string if no cookie exists.
Name
clock_to_rfc850_gmt — create a rfc850 time from [clock seconds].
Synopsis
seconds?Description
Convert an integer-seconds-since-1970 click value to RFC850 format, with the additional requirement that it be GMT only.
Name
html — construct html tagged text.
Synopsis
string? ?arg...?Description
Print text with the added ability to pass HTML tags following the string. Example:
html "Test" b i
produces: <b><i>Test</i></b>
Name
incr0 — increment a variable or set it to 1 if nonexistant.
Synopsis
varname? ?num?Description
Increment a variable
varname by
num. If the
variable doesn't exist, create it instead of returning an
error.
Name
parray — Tcl's parray with html formatting.
Synopsis
arrayName? ??pattern??Description
An html version of the standard Tcl parray command. Displays the entire contents of an array in a sorted, nicely-formatted way. Mostly used for debugging purposes.
Name
abort_page — Stops outputing data to web page, similar in purpose to PHP's die command.
Synopsis
Description
This command flushes the output buffer and stops the Tcl script from sending any more data to the client. A normal Tcl script might use the exit command, but that cannot be used in Rivet without actually exiting the apache child process!
Name
no_body — Prevents Rivet from sending any content.
Synopsis
Description
This command is useful for situations where it is necessary to only return HTTP headers and no actual content. For instance, when returning a 304 redirect.
Name
escape_string — convert a string into escaped characters.
Synopsis
Description
Scans through each character in the specified string looking for special characters, escaping them as needed, mapping special characters to a quoted hexadecimal equivalent, returning the result.
This is useful for quoting strings that are going to be part of a URL.
Name
escape_sgml_chars — escape special SGML characters in a string.
Synopsis
Description
Scans through each character in the specified string looking for any special (with respect to SGML, and hence HTML) characters from the specified string, and returns the result. For example, the right angle bracket is escaped to the corrected ampersand gt symbol.
Name
escape_shell_command — escape shell metacharacters in a string.
Synopsis
Description
Scans through each character in the specified string looking for any shell metacharacters, such as asterisk, less than and greater than, parens, square brackets, curly brackets, angle brackets, dollar signs, backslashes, semicolons, ampersands, vertical bars, etc.
For each metacharacter found, it is quoted in the result by prepending it with a backslash, returning the result.
Name
unescape_string — unescape escaped characters in a string.
Synopsis
Description
Scans through each character in the specified string looking for escaped character sequences (characters containing a percent sign and two hexadecimal characters, unescaping them back to their original character values, as needed, also mapping plus signs to spaces, and returning the result.
This is useful for unquoting strings that have been quoted to be part of a URL.
Some examples of Rivet usage follow. Some prior Tcl knowledge is assumed. If you don't know much Tcl, don't worry, it's easy, and there are some good resources available on the web that will get you up to speed quickly. Go to the web sites section and have a look.
Example 1. Hello World
As with any tool, it's always nice to see something work, so let's create a small "Hello World" page.
Assuming you have Apache configured correctly, create a file
called hello.rvt where Apache can find
it, with the following content:
<? puts "Hello World" ?>
If you then access it with your browser, you should see a blank page with the text "Hello World" (without the quotes) on it.
Example 2. Generate a Table
In another simple example, we dynamically generate a table:
<? puts "<table>\n"
for {set i 1} { $i <= 8 } {incr i} {
puts "<tr>\n"
for {set j 1} {$j <= 8} {incr j} {
set num [ expr $i * $j * 4 - 1]
puts [ format "<td bgcolor=\"%02x%02x%02x\" > $num $num $num </td>\n" \
$num $num $num ]
}
puts "</tr>\n"
}
puts "</table>\n" ?>
If you read the code, you can see that this is pure Tcl. We could take the same code, run it outside of Rivet, and it would generate the same HTML!
The result should look something like this:
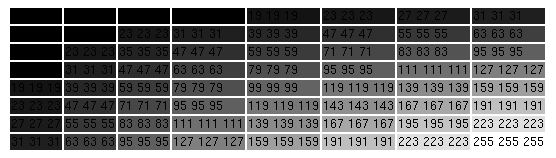
Example 3. Variable Access
Here, we demonstrate how to access variables set by GET or POST operations.
Given an HTML form like the following:
<form action="vars.rvt">
<table>
<tbody>
<tr>
<td><b>Title:</b></td>
<td><input name="title"></td>
</tr>
<tr>
<td><b>Salary:</b></td>
<td><input name="salary"></td>
</tr>
<tr>
<td><b>Boss:</b></td>
<td><input name="boss"></td></tr>
<tr>
<td><b>Skills:</b></td>
<td>
<select name="skills" multiple="multiple">
<option>c</option>
<option>java</option>
<option>Tcl</option>
<option>Perl</option>
</select>
</td>
</tr>
<tr>
<td><input type="submit"></td>
</tr>
</tbody>
</table>
</form>
We can use this Rivet script to get the variable values:
<?
set errlist {}
if { [var exists title] } {
set title [var get title]
} else {
set errlist "You need to enter a title"
}
if { [var exists salary] } {
set salary [var get salary]
if { ! [string is digit $salary] } {
lappend errlist "Salary must be a number"
}
} else {
lappend errlist "You need to enter a salary"
}
if { [var exists boss] } {
set boss [var get boss]
} else {
set boss "Mr. Burns"
}
if { [var exists skills] } {
set skills [var list skills]
} else {
lappend errlist "You need to enter some skills"
}
if { [llength $errlist] != 0 } {
foreach err $errlist {
puts "<b> $err </b>"
}
} else {
puts "Thanks for the information!"
?>
<table>
<tbody>
<tr>
<td><b>Title:</b></td>
<td><? puts $title ?></td>
</tr>
<tr>
<td><b>Boss:</b></td>
<td><? puts $boss ?></td>
</tr>
<tr>
<td><b>Salary:</b></td>
<td><? puts $salary ?></td>
</tr>
<tr>
<td><b>Skills:</b></td>
<td><? puts $skills ?></td>
</tr>
</tbody>
</table>
<?
}
?>
The first statement checks to make sure that the
boss variable has been passed to the
script, and then does something with that information. If
it's not present, an error is added to the list of errors.
In the second block of code, the variable
salary is fetched, with one more error
check - because it's a number, it needs to be composed of
digits.
The boss variable isn't required to have
been sent - we set it to "Mr. Burns" if it isn't among the
information we received.
The last bit of variable handing code is a bit trickier.
Because skills is a listbox, and can
potentially have multiple values, we opt to receive them as a
list, so that at some point, we could iterate over them.
The script then checks to make sure that
errlist is empty and outputting a thankyou
message. If errlist is not empty, the list
of errors it contains is printed.
Example 4. File Upload
The upload command endows Rivet with an
interface to access files transferred over http as parts of a
multipart form. The following HTML in one file, say,
upload.html creates a form with a text
input entry. By clicking the file chooser button the file
browser shows up and the user selects the file to be uploaded
(the file path will appear in the text input). In order to make
sure you're uploading the whole file you must combine the
action of the enctype and method attributes of the
<form...> tag in the way shown in the example. Failure
to do so would result in the client sending only the file's
path, rather than the actual contents.
<form action="foo.rvt" enctype="multipart/form-data" method="post"> <input type="file" name="MyUpload"></input> <input type="submit" value="Send File"></input> </form>
In the script invoked by the form
(upload.rvt) upload
?argument ...? commands can be used to manipulate the
various files uploaded.
<? upload save MyUpload /tmp/uploadfiles/file1 puts "Saved file [upload filename MyUpload] \ ([upload size MyUpload] bytes) to server" ?>
Don't forget that the apache server must have write access to the directory where files are being created. The Rivet Apache directives have a substantial impact on the upload process, you have to carefully read the docs in order to set the appropriate directives values that would match your requirements.
It is also important to understand that some upload commands are effective only when used in a mutually exclusive way. Apache stores the data in temporary files which are read by the upload save ?upload name? ?filename? or by the upload data ?upload name? command. Subsequent calls to these 2 commands using the same ?upload name? argument will return no data on the second call. Likewise upload channel ?upload name? will return a Tcl file channel that you can use in regular Tcl scripts only if you haven't already read the data, for example with a call to the upload data ?upload name? command.
Example 5. File Download
In general setting up a data file to be sent over http is as easy as determining the file's URI and letting Apache's standard download mechanism do all that is needed. If this approach fits your design all you have to do is to keep the downloadable files somewhere within Apache's DocumentRoot (or in any of the directories that you can configure and register using the Alias definitions or the Virtual Hosts mechanism).
When a client sends a request for a file Apache takes care of determining the filetype, sends appropriate headers to the client and then the file content. If the client is a browser capable of displaying the content of the file a representation is shown in the browser's window. When the browser hasn't a valid builtin method or plugin registered for the file's content the typical download dialog pops up asking for directions from the user.
Rivet can help if you have more sofisticated needs. For instance you may be developing an application that uses webpages to collect input data that have to be passed on to scripts or programs. In this case the content is generated on demand and a real file representing the data doesn't exist on the server. In other circumstances you may need to dynamically inhibit the download of a specific file and hide it away, even to those clients that might have already saved the URI to the file in their bookmarks. Your scripts may expunge from the pages every link to the file (your pages are dynamic, aren't they?) and move the file out of way, but it looks like a cumbersome solution.
Putting Tcl and Rivet in charge of the whole download mechanism helps in building cleaner and safer approaches to the download problem.
In this example a procedure checks for the existence of a parameter passed in by the browser. The parameter is the name (without extension) of a pdf file. Pdf files are stored in a directory whose path is in the pdf_repository variable.
# Code example for the transmission of a pdf file.
if {[var exists pdfname]} {
set pdfname [var get pdfname]
# let's build the full path to the pdf file. The 'pdf_repository'
# directory must be readable by the apache children
set pdf_full_path [file join $pdf_repository ${pdfname}.pdf]
if {[file exists $pdf_full_path]} {
# Before the file is sent we inform the client about the file type and
# file name. The client can be proposed a filename different from the
# original one. In this case, this is the point where a new file name
# must be generated.
headers type "application/pdf"
headers add Content-Disposition "attachment; filename=${pdfname}.pdf"
headers add Content-Description "PDF Document"
# The pdf is read and stored in a Tcl variable. The file handle is
# configured for a binary read: we are just shipping raw data to a
# client. The following 4 lines of code can be replaced by any code
# that is able to retrieve the data to be sent from any data source
# (e.g. database, external program, other Tcl code)
set paper [open $pdf_full_path r]
fconfigure $paper -translation binary
set pdf [read $paper]
close $paper
# Now we got the data: let's tell the client how many bytes we are
# about to send (useful for the download progress bar of a dialog box)
headers add Content-Length [string length $pdf]
# Let's send the actual file content
puts $pdf
} else {
source pdf_not_found_error.rvt
}
} else {
source parameter_not_defined_error.rvt
}
Before the pdf is sent the procedure sets the
Content-Type,
Content-Disposition,
Content-Description and
Content-Length headers to inform
the client about the file type, name and size. Notice that in
order to set the Content-Type header Rivet
uses a specialiezed form of the headers
command. Headers must be sent before data gets sent down the
output channel. Messing with this prescription causes an error
to be raised (in fact the protocol itself is been violated)
More information about the meaning of the mime headers in the http context can be found at http://www.w3.org/Protocols/rfc2616/rfc2616.html
Example 6. XML Messages and Ajax
The headers command is crucial for generating XML messages that have to be understood by JavaScript code used in Ajax applications.
Ajax is a web programming technique that heavily relies on the abilty of JavaScript (and other scriping languages like VBScript) to manipulate dynamically the HTML structure of a page. In modern browsers JavaScript code is enabled to send GET or POST requests to the webserver. These requests can ask the server to run scripts (for example Rivet Tcl scripts) that build responses and send them back to the browser. JavaScript code reads asynchronously these responses, elaborates their content and accordingly modifies the page on display. Ajax helps to build web applications that are more responsive and flexible. Instead of going through the cycle of request-generation-transfer of a page, Ajax allows the programmer to request and transmit only the essential data thus matching the general requirement of separation between data and user interface (and saving the server from sending over the same html code and graphics every time a page is refreshed)
In Ajax applications the communication between client and server is controlled by an instance of a specialized object: the non-IE world uses the XMLHttpRequest class to create it, whereas IE uses the ActiveXObject class. Through an instance of that class a POST or GET request is sent to the server, which in turn responds with a message that is stored as a string in a property of the communication object called 'returnedText'. Although this sort of communication channel doesn't imply that the messages being transmitted through it have a specific protocol, it's become widely customary to use XML as the format for such messages. A number of XML specification are being used for this, among which XML-RPC and SOAP are worth to be quoted. Anyway, you can invent your own protocol (either based on XML or anything else), but one has to be aware of the fact that if the http headers are properly set and the message returned to the client is a well formed XML fragment, also the property XMLResponse is set with a reference to an object that stores the response as an XML document. This object is an instance of a class that implements the XML W3C DOM tree methods and properties, thus enabling the scripts to read and manipulate the data embedded in the XML message with a structured and standard interface.
In this example a Rivet script initializes an array with the essential data regarding a few of the major composers of the european music. This array plays the role of a database which, in a real case, might store large tables with thousands records and more complete and extended information. The script is designed to send back to the client two types of responses: a catalog of the composers or a single record of a composer.
# The database array contains xml fragments representing the
# results of queries to a database. Many databases are now able
# to produce the results of a query in XML.
#
#array unset composer
#
set composer(1) "<composer>\n"
append composer(1) " <first_name>Claudio</first_name>\n"
append composer(1) " <last_name>Monteverdi</last_name>\n"
append composer(1) " <lifespan>1567-1643</lifespan>\n"
append composer(1) " <era>Renaissance/Baroque</era>\n"
append composer(1) " <key>1</key>\n"
append composer(1) "</composer>\n"
set composer(2) "<composer>\n"
append composer(2) " <first_name>Johann Sebastian</first_name>\n"
append composer(2) " <last_name>Bach</last_name>\n"
append composer(2) " <lifespan>1685-1750</lifespan>\n"
append composer(2) " <era>Baroque</era>\n"
append composer(2) " <key>2</key>\n"
append composer(2) "</composer>\n"
set composer(3) "<composer>\n"
append composer(3) " <first_name>Ludwig</first_name>\n"
append composer(3) " <last_name>van Beethoven</last_name>\n"
append composer(3) " <lifespan>1770-1827</lifespan>\n"
append composer(3) " <era>Romantic</era>\n"
append composer(3) " <key>3</key>\n"
append composer(3) "</composer>\n"
set composer(4) "<composer>\n"
append composer(4) " <first_name>Wolfgang Amadaeus</first_name>\n"
append composer(4) " <last_name>Mozart</last_name>\n"
append composer(4) " <lifespan>1756-1791</lifespan>\n"
append composer(4) " <era>Classical</era>\n"
append composer(4) " <key>4</key>\n"
append composer(4) "</composer>\n"
set composer(5) "<composer>\n"
append composer(5) " <first_name>Robert</first_name>\n"
append composer(5) " <last_name>Schumann</last_name>\n"
append composer(5) " <lifespan>1810-1856</lifespan>\n"
append composer(5) " <era>Romantic</era>\n"
append composer(5) " <key>5</key>\n"
append composer(5) "</composer>\n"
# we use the 'load' argument in order to determine the type of query
#
# load=catalog: we have to return a list of the names in the database
# load=composer&res_id=<id>: the script is supposed to return the record
# having <id> as record id
if {[var exists load]} {
# the xml declaration is common to every message (error messages included)
set xml "<?xml version=\"1.0\" encoding=\"ISO-8859-1\"?>\n"
switch [var get load] {
catalog {
append xml "<catalog>\n"
foreach nm [array names composer] {
if {[regexp {<last_name>(.+)</last_name>} $composer($nm) m last_name] && \
[regexp {<first_name>(.+)</first_name>} $composer($nm) m first_name]} {
append xml " <composer key='$nm'>$first_name $last_name</composer>\n"
}
}
append xml "</catalog>"
}
composer {
if {[var exists rec_id]} {
set rec_id [var get rec_id]
if {[info exists composer($rec_id)]} {
append xml $composer($rec_id)
}
}
}
}
# we have to tell the client this is an XML message. Failing to do so
# would result in an XMLResponse property set to null
headers type "text/xml"
headers add Content-Length [string length $xml]
puts $xml
}
For sake of brevity the JavaScript and HTML will not listed here. They can be downloaded (along with the Tcl script) stored in the rivet-ajax.tar.gz archive. By simply opening this tar archive in a directory accessible by your apache server and pointing your browser to the rivetService.html page you should see a page with a drop-down list. Every time a different name is picked from the list a new query is sent and logged in the apache access.log file, even though the html is never reloaded.
In addition to the core Apache module, Rivet provides a number of Tcl packages that include potentially useful code.
- commserver is a package providing a server that can be used for IPC. Still experimental. Requires the comm package from tcllib.
- dio is a database abstraction layer.
- dtcl is a compatibility package for mod_dtcl applications.
- form - for creating forms.
- rivet - some additional, useful routines.
- tclrivet
- DIO — Database Interface Objects
Name
DIO — Database Interface Objects
Synopsis
interface ?objectName? (-option | option | -option | option | ...)Description
DIO is designed to be a generic, object-oriented interface to SQL databases. Its main goal is to be as generic as possible, but since not all SQL databases support the exact same syntaxes, keeping code generic between databases is left to the abilities of the programmer. DIO simply provides a way to keep the Tcl interface generic.
interface - The name of the database interface. Currently supported interfaces are Postgresql and Mysql.
If objectName is
specified, DIO creates an object of that name. If there is
no objectName
given, DIO will automatically generate a unique object ID
Options
- -host ?
hostname?The hostname of the computer to connect to. If none is given, DIO assumes the local host. - -port ?
portNumber?The port number to connect to on hostname. - -user ?
username?The username you wish to login to the server as. - -pass ?
password?The password to login to the server with. - -db ?
database?The name of the database to connect to. - -table ?
tableName?The default table to use when using built-in commands for storing and fetching. - -keyfield ?
keyFieldname?The default field to use as the primary key when using built-in commands for storing and fetching. - -autokey (1 | 0)If this option is set to 1, DIO will attempt to determine an automatic key for keyField when storing and fetching. In most databases, this requires that the sequence also be specified. In the case of MySQL, where sequences do not exist, autokey must be used in conjunction with a table which has a field specified as AUTO.
- -sequence ?
sequenceName?If DIO is automatically generating keys, it will use this sequence as a means to gain a unique number for the stored key.
DIO Object Commands
objectName?array? ?request?Execute request as a SQL query and create an array from the first record found. The array is set with the fields of the table and the values of the record found.objectName?autokey? (value | boolean)Return the current autokey value. If value is specified, it sets a new value for the autokey option.objectName?close?Close the current database connection. This command is automatically called when the DIO object is destroyed.objectName?count?Return a count of the number of rows in the specified (or current) table.objectName?db? ?value?Return the current database. If value is specified, it sets a new value for the database. In most cases, the DIO object will automatically connect to the new database when this option is changed.objectName?delete? ?key? (-option |option| ...)Delete a record from the database where the primary key matches key.objectName?destroy?Destroy the DIO object.objectName?errorinfo? ?value?errorinfo contains the value of the last error, if any, to occur while executing a request. When a request fails for any reason, this variable is filled with the error message from the SQL interface package.objectName?exec? ?request?Execute request as an SQL query. When the exec command is called, the query is executed, and a DIO result object is returned. From there, the result object can be used to obtain information about the query status and records in a generic way. See Result Object CommandsobjectName?fetch? ?key? ?arrayName? (-option |option| ...)Fetch a record from the database where the primary key matches key and store the result in an array called arrayName.objectName?forall? ?request? ?arrayName? ?body?Execute an SQL select request and iteratively fill the array named arrayName with elements named with the matching field names, and values containing the matching values, repeatedly executing the specified code body for each row returned.objectName?host? ?value?Return the current host value. If value is specified, it sets a new value for the host.objectName?insert? ?arrayName? (-option |option| ...)Insert fields from arrayName into the specified table in the database.objectName?interface?Return the database interface type, such asPostgresqlorMysql.objectName?keyfield? ?value?Return the current keyfield. If value is specified, it sets a new value for the keyfield. Value can contain multiple key fields as a Tcl list, if the table has multiple key fields.objectName?keys? ?pattern? (-option |option| ...)Return a list of keys in the database. If pattern is specified, only the keys matching will be returned.objectName?lastkey?Return the last key that was used from sequence. If sequence has not been specified, this command returns an empty string.objectName?list? ?request?Execute request as a SQL query and return a list of the first column of each record found.objectName?makekey? ?arrayName? ?keyfield?Given an array containing key-value pairs and an optional list of key fields (we use the object's keyfield if none is specified), if we're doing auto keys, create and return a new key, otherwise if it's a single key, just return its value from the array, else if there are multiple keys, return all the keys' values from the array as a list.objectName?nextkey?Increment sequence and return the next key to be used. If sequence has not been specified, this command returns an empty string.objectName?open?Open the connection to the current database. This command is automatically called from any command which accesses the database.objectName?pass? ?value?Return the current pass value. If value is specified, it sets a new value for the password.objectName?port? ?value?Return the current port value. If value is specified, it sets a new value for the port.objectName?quote? ?string?Return the specified string quoted in a way that makes it acceptable as a value in a SQL statement.objectName?search? (-option |option| ...)Search the current table, or the specified table if -table tableName is specified, for rows matching one or more fields as key-value pairs, and return a query result handle. See Result Object CommandsFor example,set res [DIO search -table people -firstname Bob]
objectName?sequence? ?value?Return the current sequence value. If value is specified, it sets a new value for the sequence.objectName?store? ?arrayName? (-option |option| ...)Store the contents of arrayName in the database, where the keys are the field names and the array's values are the corresponding values. Do an SQL insert if the corresponding row doesn't exist, or an update if it does.The table name must have been previously set or specified with ?-table?, and the key field(s) must have been previously set or specified with ?-keyfield?.Please note that the store method has significantly higher overhead than the update or insert methods, so if you know you are inserting a row rather than updating one, it is advisable to use the insert method and, likewise, if you know you are updating rather than inserting, to use the update method.objectName?string? ?request?Execute request as a SQL query and return a string containing the first record found.objectName?table? ?value?Return the current table. If value is specified, it sets a new value for the table.objectName?update? ?arrayName? (-option |option| ...)Updates the row matching the contents of arrayName in the database. The matching row must already exist. The table can have already been set or can be specified with ?-table?, and the key field(s) must either have been set or specified with ?-keyfield?.objectName?user? ?value?Return the current user value. If value is specified, it sets a new value for the user.
Result Object Commands
resultObj?autocache? ?value?Return the current autocache value. If value is specified, it sets a new value for autocache.If autocache is true, the result object will automatically cache rows as you use them. This means that the first time you execute a forall command, each row is being cached in the result object itself and will no longer need to access the SQL result. Default is true.resultObj?cache?Cache the results of the current SQL result in the result object itself. This means that even if the database connection is closed and all the results of the DIO object are lost, this result object will still maintain a cached copy of its records.resultObj?errorcode? ?value?Return the current errorcode value. If value is specified, it sets a new value for errorcode.errorcode contains the current code from the SQL database which specifies the result of the query statement which created this object. This variable can be used to determine the success or failure of a query.resultObj?errorinfo? ?value?Return the current errorinfo value. If value is specified, it sets a new value for errorinfo.If an error occurred during the SQL query, DIO attempts to set the value of errorinfo to the resulting error message.resultObj?fields? ?value?Return the current fields value. If value is specified, it sets a new value for fields.fields contains the list of fields used in this query. The fields are in order of the fields retrieved for each row.resultObj?forall? ?-type? ?varName? ?body?Execute body over each record in the result object.Types:- -arrayCreate
varNameas an array where the indexes are the names of the fields in the table and the values are the values of the current row. - -keyvalueSet
varNameto a list containing key-value pairs of fields and values from the current row. (-field value -field value) - -listSet
varNameto a list that contains the values of the current row.
resultObj?next? ?-type? ?varName?Retrieve the next record in the result object.Types:- -arrayCreate
varNameas an array where the indexes are the names of the fields in the table and the values are the values of the current row. - -keyvalueSet
varNameto a list containing key-value pairs of fields and values from the current row. (-field value -field value) - -listSet
varNameto a list that contains the values of the current row.
resultObj?numrows? ?value?Return the current numrows value. If value is specified, it sets a new value for numrows.numrows is the number of rows in this result.resultObj?resultid? ?value?Return the current resultid value. If value is specified, it sets a new value for resultid.resultid in most databases is the result pointer which was given us by the database. This variable is not generic and should not really be used, but it's there if you want it.resultObj?rowid? ?value?Return the current rowid value. If value is specified, it sets a new value for rowid.rowid contains the number of the current result record in the result object. This variable should not really be accessed outside of the result object, but it's there if you want it.
- DIODisplay — Database Interface Objects Display Class
Name
DIODisplay — Database Interface Objects Display Class
Synopsis
objectName | #auto) (-option | option | -option | option | ...)Description
DIODisplay is an HTML display class that uses a DIO object to do the database work and a form object to do the displaying.
Options
-
-DIO
dioObject - The DIO object to be used in conjunction with this display object. This is a required field.
-
-cleanup (1 | 0)
- If cleanup is true, when the display object is shown, it will automatically destroy the DIO object, the form object and itself. Default is true.
-
-confirmdelete (1 | 0)
- If confirmdelete is true, attempting to delete a record from the database first requires that the user confirm that they wish to delete it. If it is false, deletion occurs without prompting the user. Defaults to true.
-
-errorhandler
procName - The name of a procedure to handle errors when they occur. During the processing of requests and pages, sometimes unexpected errors can occur. This procedure will handle any errors. It is called with a single argument, the error string. Use of the Tcl errorInfo and errorCode variables is also recommended though.If no errorhandler is specified, the handle_error method within the Display object will handle the error.
-
-fields
fieldList - Specify a list of fields to be used in this object. The fields list is actually created by using the field command to add fields to the display, but this option can be useful to sometimes over-set the list of fields created.
-
-form
formObject - A Rivet form object to use when displaying a form. If one is not specified, the display object will automatically create one when it is necessary.
-
-functions
functionList - A list of functions to be displayed in the main menu. This is a list of functions the user is allowed to execute.
-
-pagesize
pageSize - How many records to show per page on a search or list. Default is 25.
-
-rowfields
fieldList - A list of fields to display in each row of a search or list. When a search or list is conducted and the resulting rows are displayed, this list will limit which fields are displayed. Default is all fields.
-
-rowfunctions
functionList - A list of functions to display in each row of a search or list.
-
-searchfields
fieldList - A list of fields to allow a user to search by. This list will appear in the main screen as a drop-down box of fields the user can search on.
-
-title
title - The title of the display object. This will be output as the title of the HTML document.
DIO Display Object Commands
-
objectNamecleanup ?value? - Return the current cleanup value. If
valueis specified, it sets a new value for the cleanup option. -
objectNamedeletekey - Delete the specified key from the database.The default action of this method is to call the DIO object's delete command. This method can be overridden.
-
objectNamedestroy - Destroy the diodisplay object.
-
objectNameDIO ?value? - Return the current DIO value. If
valueis specified, it sets a new value for DIO. -
objectNameerrorhandler ?value? - Return the current errorhandler value. If
valueis specified, it sets a new value for errorhandler. -
objectNamefetchkeyarrayName - Fetch the specified
keyfrom the database and store it as an array inarrayNameThe default of this method is to call the DIO object's fetch command. This method can be overridden. -
objectNamefieldfieldName(-arg |arg...) - Create a new field object and add it to the display. When a field is added to the display, a new object of the DIODisplayField class is created with its values. See [FIXME - LINK] DIO Display Fields for options and values.
-
objectNamefields ?value? - Return the current fields value. If
valueis specified, it sets a new value for fields. -
objectNameform ?value? - Return the current form value. If
valueis specified, it sets a new value for form. -
objectNamefunctionfunctionName - Add a new function to the list of possible functions. The display object will only execute methods and procs which are defined as functions by the object. This is to protect the program from executing a different procedure other than what is allowed. The function command adds a new function to the list of allowable functions.
-
objectNamefunctions ?value? - Return the current functions value. If
valueis specified, it sets a new value for functions. See [FIXME - LINK DIO Display Functions] for a list of default functions. -
objectNamepagesize ?value? - Return the current form pagesize. If
valueis specified, it sets a new value for pagesize. -
objectNamerowfields ?value? - Return the current form rowfields. If
valueis specified, it sets a new value for rowfields. -
objectNamerowfooter - Output the footer of a list of rows to the web page.This method can be overridden.
-
objectNamerowfunctions ?value? - Return the current rowfunctions value. If
valueis specified, it sets a new value for rowfunctions. -
objectNamerowheader - Output the header of a list of rows to the web page. By default, this is an HTML table with a top row listing the fields in the table.This method can be overridden.
-
objectNamesearchfields ?value? - Return the current searchfields value. If
valueis specified, it sets a new value for searchfields. -
objectNameshow - Show the display object.This is the main method of the display class. It looks for a variable called
modeto be passed in through a form response and uses that mode to execute the appropriate function. If mode is not given, the Main function is called.This function should be called for every page. -
objectNameshowform - Display the form of the object.This method displays the form for this display object. It is used in the Add and Edit methods but can be called separately if needed.This method can be overridden if the default look of a form needs to be changed. By default, the form displayed is simply the fields in a table, in order.
-
objectNameshowrowarrayName - Display a single row of a resulting list or search.This method is used to display a single row while displaying the result of a list or search.
arrayNameis a fetched array of the record.This method can be overriden if the default look of a row needs to be changed. By default, each row is output as a table row with each field as a table data cell. -
objectNameshowview - Display the view of the object.This method displays the view for this display object. It is used in the Details methods but can be called separately if needed.This method can be overridden if the default look of a view needs to be changed. By default, the view displayed is simply the fields in a table, in order.
-
objectNamestorearrayName - Store the specified
arrayNamein the database.The default of this method is to call the DIO object's store command. This method can be overridden. -
objectNametext ?value? - Return the current text value. If
valueis specified, it sets a new value for text. -
objectNametitle ?value? - Return the current title value. If
valueis specified, it sets a new value for title. -
objectNametype ?value? - Return the current type value. If
valueis specified, it sets a new value for type. -
objectNamevalue ?value? - Return the current value value. If
valueis specified, it sets a new value for value.
DIO Display Functions
These functions are called from the
show method when a form response
variable called mode is set. If no
mode has been set, the default mode is
Main. The show method will handle
the necessary switching of functions. The show method
also handles checking to make sure the function given is a
true function. If not, an error message is displayed.
New functions can be added as methods or by use of the
function command, and any of the
default functions can be overridden with new methods to
create an entirely new class. These are the default
functions provided.
- Add
- Show a form that allows the user to add a new entry to the database. This function calls showform to display the form for adding the entry.
- Cancel
- The Cancel function does nothing but redirect back to the Main function. This is handy for forms which have a cancel button to point to.
- Delete
- If
confirmdeleteis true (the default), the Delete function will ask the user if they're sure they want to delete the record from the database. Ifconfirmdeleteis false, or if the user confirms they wish to delete, this function calls the DoDelete function to do the actual deletion of a record. - Details
- Display the view of a single record from the database. This function calls the showview method to display a single record from the database.
- DoDelete
- This function actually deletes a record from the database. Once it has deleted the record, it redirects the user back to the Main function.
- Edit
- Show a form that allows the user to edit an existing entry to the database. This function calls showform to display the form for editing the entry and fills in the fields with the values retrieved from the database.
- List
- This function lists the entires contents of the database. Each record is output in a row using the showrow method.
- Main
- This function is the main function of the display object. If there is no mode, or once most commands complete, the user will be redirected to this function. The default Main function displays a list of functions the user can execute, a list of searchfields the user can search on, and a query field. This query field is used by all of the other functions to determine what the user is trying to find.In the case of a search, query specifies what string the user is looking for in the specified search field. In the case of delete, details or edit, the query specifies the database key to access.
- Save
- This function saves any data passed to using the store method. This is primarily used by the add and edit commands to store the results of the form the user has filled out.
- Search
- This function searches the database for any row whose
searchByfield matchesquery. Once any number of records are found, Search displays the results in rows.
DIO Display Fields
Display fields are created with the field command of the DIODisplay object. Each field is created as a new DIODisplayField object or as a subclass of DIODisplayField. The standard form fields use the standard field class, while specialized field types use a class with different options but still supports all of the same commands and values a generic field does.
displayObject field fieldname (-option | option...)These are the standard options supported by field types:
-
-formargs
arguments - When a field is created, any argument which is not a standard option is assumed to be an argument passed to the form object when the field is shown in a form. These arguments are all appended to the
formargsvariable. You can use this option to override or add options after the initial creation of an object -
-readonly (1 | 0)
- If
readonlyis set to true, the field will not display a form entry when displaying in a form. -
-text
text - The text displayed next to the form or view field. By default, DIODisplay tries to figure out a pretty way to display the field name. This text will override that default and display whatever is specified.
-
-type
fieldType - The type of field this is. This type is used when creating the field in the form object.
fieldTypecan be any of the accepted form field types. See [FIXME - LINK DIO Field Types] for a list of types available.
All other arguments, unless specified in an individual field type, are passed directly to the form object when the field is created. So, you can pass -size or -maxsize to specify the length and maximum length of the field entry. Or, if type were textarea, you could define -rows and -cols to specify its row and column count.
DIO Display Field Types
The following is a list of recognized field types by DIODisplay. Some are standard HTML form fields, and others are DIODisplay fields which execute special actions and functions.
This is session management code. It provides an interface to allow you to generate and track a browser's visit as a "session", giving you a unique session ID and an interface for storing and retrieving data for that session on the server.
This is an alpha/beta release -- documentation is not in final form, but everything you need should be in this file.
Using sessions and their included ability to store and retrieve session-related data on the server, programmers can generate more secure and higher-performance websites. For example, hidden fields do not have to be included in forms (and the risk of them being manipulated by the user mitigated) since data that would be stored in hidden fields can now be stored in the session cache on the server. Forms are then faster since no hidden data is transmitted -- hidden fields must be sent twice, once in the form to the broswer and once in the response from it.
Robust login systems, etc, can be built on top of this code.
Rivet. Currently has only been tested with Postgresql. All DB interfacing is done through DIO, though, so it should be relatively easy to add support for other databases.
Create the tables in your SQL server. With Postgres,
do a psql www or whatever DB you
connect as, then a backslash-i on
session-create.sql
(If you need to delete the tables, use session-drop.sql)
The session code by default requires a DIO handle
called DIO (the name of which can be
overridden). We get it by doing a
RivetServerConf ChildInitScript "package require DIO" RivetServerConf ChildInitScript "::DIO::handle Postgresql DIO -user www"
In your httpd.conf, add:
RivetServerConf ChildInitScript "package require Session; Session SESSION"
This tells Rivet you want to create a session object named SESSION in every child process Apache creates.
You can configure the session at this point using numerous key-value pairs (which are defined later in this doc). Here's a quick example:
RivetServerConf ChildInitScript "package require Session; Session SESSION \ -cookieLifetime 120 -debugMode 1"
Turn debugging on -debugMode 1 to figure out what's going on -- it's really useful, if verbose.
In your .rvt file, when you're generating the <HEAD> section:
SESSION activate
Activate handles everything for you with respect to creating new sessions, and for locating, validating, and updating existing sessions. Activate will either locate an existing session, or create a new one. Sessions will automatically be refreshed (their lifetimes extended) as additional requests are received during the session, all under the control of the key-value pairs controlling the session object.
The main methods your code will use are:
- SESSION idAfter doing a SESSION activate, this will return a 32-byte ASCII-encoded random hexadecimal string. Every time this browser comes to us with a request within the timeout period, this same string will be returned (assuming they have cookies enabled).
- SESSION is_new_sessionreturns 1 if it's a new session or 0 if it has previously existed (i.e. it's a zero if this request represents a "return" or subsequent visit to a current session.)
- SESSION new_session_reasonThis will return why this request is the first request of a new session, either "no_cookie" saying the browser didn't give us a session cookie, "no_session" indicating we got a cookie but couldn't find it in our session table, or "timeout" where they had a cookie and we found the matching session but the session has timed out.
- SESSION store ?
packageName? ?key? ?data?Given the name of a package, a key, and some data. Stores the data in the rivet session cache table. - SESSION fetch ?
packageName? ?key?Given a package name and a key, return the data stored by the store method, or an empty string if none was set. (Status is set to the DIO error that occurred, it can be fetched using the status method.)
The following key-value pairs can be specified when a session object (like SESSION above) is created:
- sessionLifetime
- how many seconds the session will live for. 7200 == 2 hours
- sessionRefreshInterval
- If a request is processed for a browser that currently has a session and this long has elapsed since the session update time was last updated, update it. 900 == 15 minutes. so if at least 15 minutes has elapsed and we've gotten a new request for a page, update the session update time, extending the session lifetime (sessions that are in use keep getting extended).
- cookieName
- name of the cookie stored on the user's web browser default rivetSession
- dioObject
- The name of the DIO object we'll use to access the database (default DIO)
- gcProbability
- The probability that garbage collection will occur in percent. (default 1%, i.e. 1)
- gcMaxLifetime
- the number of seconds after which data will be seen as "garbage" and cleaned up -- defaults to 1 day (86400)
- refererCheck
- The substring you want to check each HTTP referer for. If the referer was sent by the browser and the substring is not found, the session will be deleted. (not coded yet)
- entropyFile
- The name of a file that random binary data can be read from. (
/dev/urandom) Data will be used from this file to help generate a super-hard-to-guess session ID. - entropyLength
- The number of bytes which will be read from the entropy file. If 0, the entropy file will not be read (default 0)
- scrambleCode
- Set the scramble code to something unique for the site or your app or whatever, to slightly increase the unguessability of session ids (default "some random string")
- cookieLifetime
- The lifetime of the cookie in minutes. 0 means until the browser is closed (I think). (default 0)
- cookiePath
- The webserver subpath that the session cookie applies to (defaults to
/) - cookieDomain
- The domain to set in the session cookie (FIXME - not coded yet)
- cookieSecure
- Specifies whether the cookie should only be sent over secure connections, 0 = any, 1 = secure connections only (default 0)
- sessionTable
- The name of the table that session info will be stored in (default
rivet_session) - sessionCacheTable
- The name of the table that contains cached session data (default
rivet_session_cache) - debugMode
- Set debug mode to 1 to trace through and see the session object do its thing (default 0)
- debugFile
- The file handle that debugging messages will be written to (default
stdout)
The following methods can be invoked to find out information about the current session, store and fetch server data identified with this session, etc:
- SESSION statusReturn the status of the last operation
- SESSION idGet the session ID of the current browser. Returns an empty string if there's no session (will not happen is SESSION activate has been issued.)
- SESSION new_session_reasonReturns the reason why there wasn't a previous session, either "no_cookie" saying the browser didn't give us a session cookie, "no_session" indicating we got a cookie but couldn't find it in the session table, or "timeout" when we had a cookie and a session but the session had timed out.
- SESSION store ?
packageName? ?key? ?data?Given a package name, a key string, and a data string, store the data in the rivet session cache. - SESSION fetch ?
packageName? ?key?Given a package name and a key, return the data stored by the store method, or an empty string if none was set. Status is set to the DIO error that occurred, it can be fetched using the status method. - SESSION deleteGiven a user ID and looking at their IP address we inherited from the environment (thanks, Apache), remove them from the session table. (the session table is how the server remembers stuff about sessions). If the session ID was not specified the current session is deleted.
- SESSION activateFind and validate the session ID if they have one. If they don't have one or it isn't valid (timed out, etc), create a session and drop a cookie on them.
RivetServerConf ChildInitScript "Session SESSION -entropyFile /dev/urandom \ -entropyLength 10 -debugMode 1"
This options say we want to get randomness from an entropy file (random data pseudo-device) of /dev/urandom, to get ten bytes of random data from that entropy device, and to turn on debug mode, which will cause the SESSION object to output all manner of debugging information as it does stuff. This has been tested on FreeBSD and appears to work.
The Rivet mailing list is the first place you should turn for
help, if you haven't found the solution to your problem in the
documentation. Send email to
<rivet-dev@tcl.apache.org>. If you have a
question, idea, or comment about the Rivet code itself, please
send us email at <rivet-dev@tcl.apache.org>. To
subscribe to either list, post email to
<rivet-,
where list-subscribe@tcl.apache.org>list is either dev or user.
Currently, dev is the preferred list to use.
The mailing list archives are available at http://mail-archives.apache.org/eyebrowse/SummarizeList?listId=118
The news:comp.lang.tcl newsgroup is a good place to ask about Tcl questions in general. Rivet developers also follow the newsgroup, but it's best to ask Rivet-specific questions on the Rivet list.
There are several web sites that cover Apache and Tcl extensively.
- http://tcl.apache.org is the home for the Apache Tcl project. Go there for the latest versions of our software (if you aren't reading these pages off of the site!).
- http://httpd.apache.org/docs/ is the first place to go for questions about the Apache web server.
- http://www.tcl.tk is the canonical site for Tcl information.
- http://wiki.tcl.tk is the Tcl'ers Wiki, a free-form place to search for answers and ask for help.
Apache Rivet uses the Apache Bug Tracking system at http://issues.apache.org/bugzilla/. Here, you can report problems, or check and see if existing issues are already known and being dealt with.
Rivet makes available code for two popular editors,
emacs and
vim to facilitate the editing of
Rivet template files. The key concept is that the editor is
aware of the <? and ?> tags and switches back and forth
between Tcl and HTML modes as the cursor moves. These files,
two-mode-mode.el and
rvt.vim are available in the
contrib/ directory.
This section easily falls out of date, as new code is added, old code is removed, and changes are made. The best place to look is the source code itself. If you are interested in the changes themselves, the Subversion revision control system (svn) can provide you with information about what has been happening with the code.
When Apache is started, (or when child Apache processes are
started if a threaded Tcl is used),
Rivet_InitTclStuff is called, which
creates a new interpreter, or one interpreter per virtual
host, depending on the configuration. It also initializes
various things, like the RivetChan
channel system, creates the Rivet-specific Tcl commands, and
executes Rivet's init.tcl. The caching
system is also set up, and if there is a
GlobalInitScript, it is run.
The RivetChan system was created in order to have an actual Tcl channel that we could redirect standard output to. This lets us use, for instance, the regular puts command in .rvt pages. It works by creating a channel that buffers output, and, at predetermined times, passes it on to Apache's IO system. Tcl's regular standard output is replaced with an instance of this channel type, so that, by default, output will go to the web page.
Rivet aims to run standard Tcl code with as few surprises as possible. At times this involves some compromises - in this case regarding the global command. The problem is that the command will create truly global variables. If the user is just cut'n'pasting some Tcl code into Rivet, they most likely just want to be able to share the variable in question with other procs, and don't really care if the variable is actually persistant between pages. The solution we have created is to create a proc ::request::global that takes the place of the global command in Rivet templates. If you really need a true global variable, use either ::global or add the :: namespace qualifier to variables you wish to make global.
When a Rivet page is requested, it is transformed into an ordinary Tcl script by parsing the file for the <? ?> processing instruction tags. Everything outside these tags becomes a large puts statement, and everything inside them remains Tcl code.
Each .rvt file is evaluated in its own
::request namespace, so that it is not
necessary to create and tear down interpreters after each
page. By running in its own namespace, though, each page will
not run afoul of local variables created by other scripts,
because they will be deleted automatically when the namespace
goes away after Apache finishes handling the request.
| Note |
|---|---|
| One current problem with this system is that while variables are garbage collected, file handles are not, so that it is very important that Rivet script authors make sure to close all the files they open. |
After a script has been loaded and parsed into it's "pure Tcl" form, it is also cached, so that it may be used in the future without having to reload it (and re-parse it) from the disk. The number of scripts stored in memory is configurable. This feature can significantly improve performance.
If you are interested in hacking on Rivet, you're welcome to contribute! Invariably, when working with code, things go wrong, and it's necessary to do some debugging. In a server environment like Apache, it can be a bit more difficult to find the right way to do this. Here are some techniques to try.
The first thing you should know is that Apache can be launched as a single process with the -X argument:
httpd -X.
On Linux, one of the first things to try is the system call tracer, strace. You don't even have to recompile Rivet or Apache for this to work.
strace -o /tmp/outputfile -S 1000 httpd -X
This command will run httpd in the system call tracer,
which leaves its output (there is potentially a lot of it) in
/tmp/outputfile. The -S
option tells strace to only record the
first 1000 bytes of a syscall. Some calls such as
write can potentially be much longer than
this, so you may want to increase this number. The results
are a list of all the system calls made by the program. You
want to look at the end, where the failure presumably occured,
to see if you can find anything that looks like an error. If
you're not sure what to make of the results, you can always
ask on the Rivet development mailing list.
If strace (or its equivalent on your operating system) doesn't answer your question, it may be time to debug Apache and Rivet. To do this, you will need to run the ./configure.tcl script with the -enable-symbols option, and recompile.
Since it's easier to debug a single process, we'll still run Apache in single process mode with -X:
@ashland [~] $ gdb /usr/sbin/apache.dbg
GNU gdb 5.3-debian
Copyright 2002 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "powerpc-linux"...
(gdb) run -X
Starting program: /usr/sbin/apache.dbg -X
[New Thread 16384 (LWP 13598)]
.
.
.
When your apache session is up and running, you can request a web page with the browser, and see where things go wrong (if you are dealing with a crash, for instance). A helpful gdb tutorial is available here: http://www.delorie.com/gnu/docs/gdb/gdb_toc.html
Rivet is a break from the past, in that we, the authors, have attempted to take what we like best about our past efforts, and leave out or change things we no longer care for. Backwards compatibility was not a primary goal when creating Rivet, but we do provide this information which may be of use to those wishing to upgrade from mod_dtcl or NWS installations.
Rivet was originally based on the dtcl code, but it has changed (improved!) quite a bit. The concepts remain the same, but many of the commands have changed.