Title: K-Means Clustering
# k-Means clustering - basics
[k-Means](http://en.wikipedia.org/wiki/Kmeans) is a simple but well-known algorithm for grouping objects, clustering. All objects need to be represented
as a set of numerical features. In addition, the user has to specify the
number of groups (referred to as *k*) she wishes to identify.
Each object can be thought of as being represented by some feature vector
in an _n_ dimensional space, _n_ being the number of all features used to
describe the objects to cluster. The algorithm then randomly chooses _k_
points in that vector space, these point serve as the initial centers of
the clusters. Afterwards all objects are each assigned to the center they
are closest to. Usually the distance measure is chosen by the user and
determined by the learning task.
After that, for each cluster a new center is computed by averaging the
feature vectors of all objects assigned to it. The process of assigning
objects and recomputing centers is repeated until the process converges.
The algorithm can be proven to converge after a finite number of
iterations.
Several tweaks concerning distance measure, initial center choice and
computation of new average centers have been explored, as well as the
estimation of the number of clusters _k_. Yet the main principle always
remains the same.
## Quickstart
[Here](https://github.com/apache/mahout/blob/master/examples/bin/cluster-reuters.sh)
is a short shell script outline that will get you started quickly with
k-means. This does the following:
* Accepts clustering type: *kmeans*, *fuzzykmeans*, *lda*, or *streamingkmeans*
* Gets the Reuters dataset
* Runs org.apache.lucene.benchmark.utils.ExtractReuters to generate
reuters-out from reuters-sgm (the downloaded archive)
* Runs seqdirectory to convert reuters-out to SequenceFile format
* Runs seq2sparse to convert SequenceFiles to sparse vector format
* Runs k-means with 20 clusters
* Runs clusterdump to show results
After following through the output that scrolls past, reading the code will
offer you a better understanding.
## Implementation
The implementation accepts two input directories: one for the data points
and one for the initial clusters. The data directory contains multiple
input files of SequenceFile(Key, VectorWritable), while the clusters
directory contains one or more SequenceFiles(Text, Cluster)
containing _k_ initial clusters or canopies. None of the input directories
are modified by the implementation, allowing experimentation with initial
clustering and convergence values.
Canopy clustering can be used to compute the initial clusters for k-KMeans:
// run the CanopyDriver job
CanopyDriver.runJob("testdata", "output"
ManhattanDistanceMeasure.class.getName(), (float) 3.1, (float) 2.1, false);
// now run the KMeansDriver job
KMeansDriver.runJob("testdata", "output/clusters-0", "output",
EuclideanDistanceMeasure.class.getName(), "0.001", "10", true);
In the above example, the input data points are stored in 'testdata' and
the CanopyDriver is configured to output to the 'output/clusters-0'
directory. Once the driver executes it will contain the canopy definition
files. Upon running the KMeansDriver the output directory will have two or
more new directories: 'clusters-N'' containining the clusters for each
iteration and 'clusteredPoints' will contain the clustered data points.
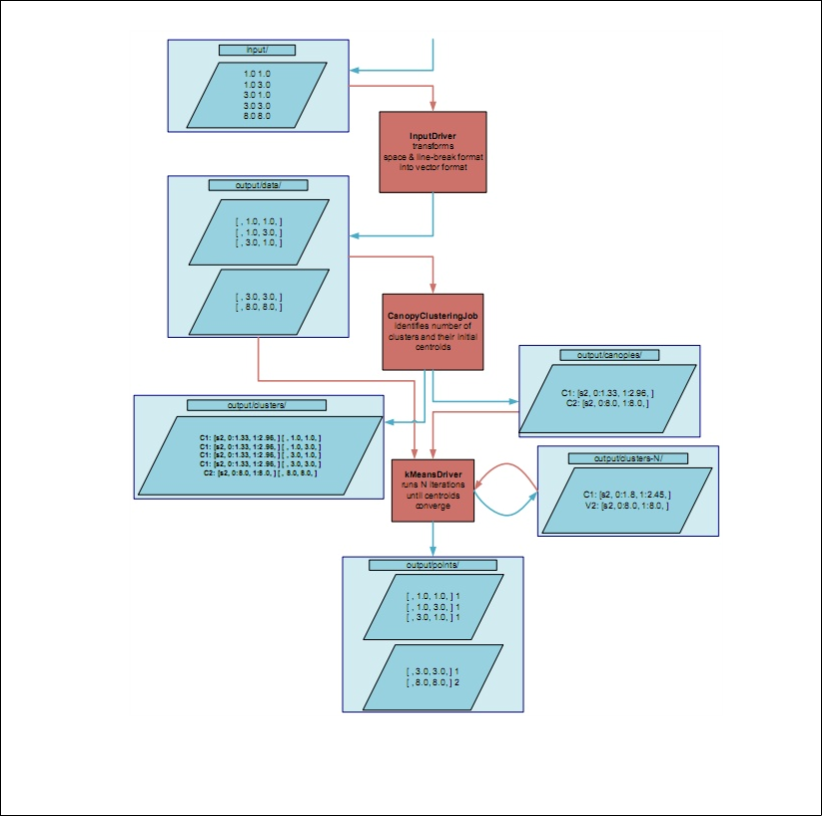
This diagram shows the examplary dataflow of the k-Means example
implementation provided by Mahout:
## Running k-Means Clustering
The k-Means clustering algorithm may be run using a command-line invocation
on KMeansDriver.main or by making a Java call to KMeansDriver.runJob().
Invocation using the command line takes the form:
bin/mahout kmeans \
-i \
-c \
-o
 ## Running k-Means Clustering
The k-Means clustering algorithm may be run using a command-line invocation
on KMeansDriver.main or by making a Java call to KMeansDriver.runJob().
Invocation using the command line takes the form:
bin/mahout kmeans \
-i \
-c \
-o
## Running k-Means Clustering
The k-Means clustering algorithm may be run using a command-line invocation
on KMeansDriver.main or by making a Java call to KMeansDriver.runJob().
Invocation using the command line takes the form:
bin/mahout kmeans \
-i \
-c \
-o