

Apache Ignite In-Memory Data Fabric is a high-performance, integrated and distributed in-memory platform for computing and transacting on large-scale data sets in real-time, orders of magnitude faster than possible with traditional disk-based or flash technologies.
Apache Ignite In-Memory Data Fabric is designed to deliver uncompromised performance for a wide set of in-memory computing use cases from high performance computing, to the industry most advanced data grid, highly available service grid, and streaming.
Latest News
-
Pitfalls of the MyBatis Caches With Apache Ignite
Blog, Shamim Bhuiyan, Mar 9, 2016 -
Linking Apache Ignite and Apache Kafka for Highly Scalable and Reliable Data Processing
Blog, Roman Shtykh, Mar 3, 2016 -
Ignite Adds Add-ons
Feb 17, 2016 -
Apache Ignite Streamer based on Apache Camel
Blog, Raúl Kripalani, Jan 28, 2016 -
Apache Ignite 1.5.0.final Released
Jan 4, 2016
Distributed SQL Queries
Apache Ignite supports a very elegant query API with support for:
- Scan Queries (Predicate-based)
- SQL Queries (ANSI 99)
- Text Queries
This video demonstrates how to exectute distributed cache queries in Ignite using standard SQL syntax.
Duration: 03:25
Getting Started with Data Grid
Apache Ignite In-Memory Data Grid is an implementation of JCache (JSR 107) that supports:
- Basic Cache Operations
- ConcurrentMap APIs
- EntryProcessor
- Pluggable Persistence
This video shows how to use basic cache operations and ACID transactions.
Duration: 03:50
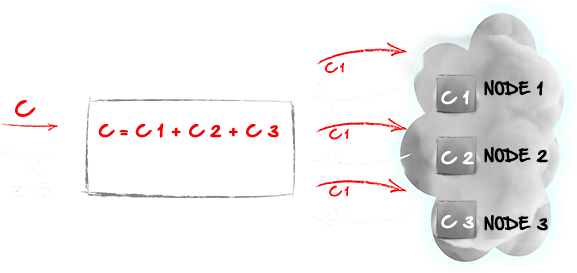
Getting Started with Compute Grid
Apache Ignite has advanced compute and clustering capabilities including:
- Dynamic Sub-Clusters
- Clustered Lambda Execution
- Clustered ForkJoin Tasks
In this video we will broadcast and execute a "Hello World" closure on all the nodes in the cluster.
Duration: 03:50
Ask a Question
If you have any questions about how to use Apache Ignite, please post them to the User Forum.