
AgilityGet faster insights from big data with no IT intervention LEARN MORE |
FlexibilityAnalyze semi-structured/nested data coming from NoSQL applications LEARN MORE |
FamiliarityLeverage existing SQL skillsets, BI tools and Apache Hive deployments LEARN MORE |
Apache Drill is an open source, low latency SQL query engine for Hadoop and NoSQL.
Modern big data applications such as social, mobile, web and IoT deal with a larger number of users and larger amount of data than the traditional transactional applications. The datasets associated with these applications evolve rapidly, are often self-describing and can include complex types such as JSON and Parquet. Apache Drill is built from the ground up to provide low latency queries natively on such rapidly evolving multi-structured datasets at scale.
Day-zero analytics & rapid
application development
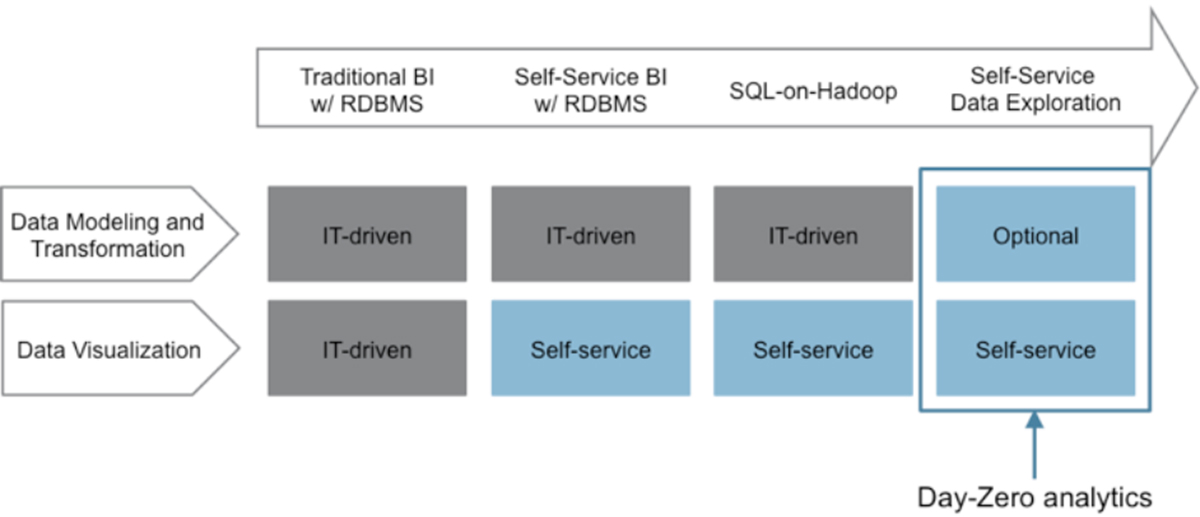
Apache Drill provides direct queries on self-describing and semi-structured data in files (such as JSON, Parquet) and HBase tables without needing to define and maintain schemas in a centralized store such as Hive metastore. This means that users can explore live data on their own as it arrives versus spending weeks or months on data preparation, modeling, ETL and subsequent schema management.
Purpose-built for semi-structured/nested data
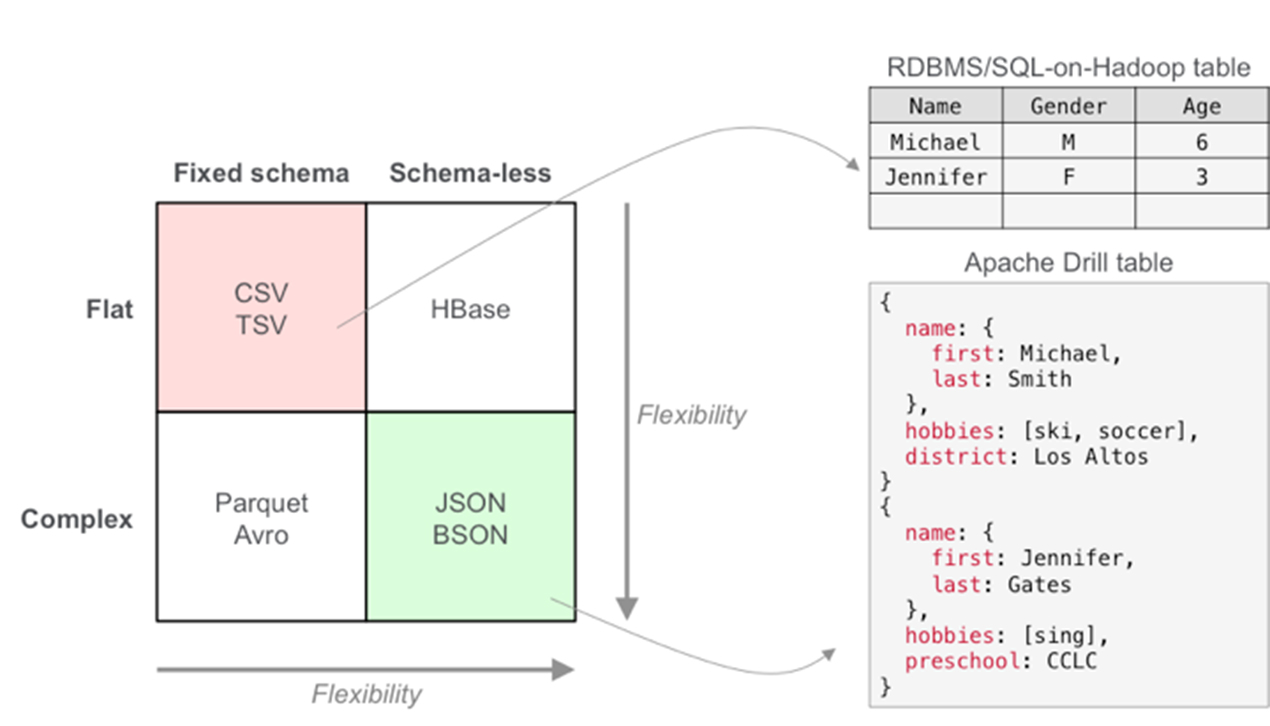
Drill provides a JSON-like internal data model to represent and process data. The flexibility of this data model allows Drill to query, without flattening, both simple and complex/nested data types as well as constantly changing application-driven schemas commonly seen with Hadoop/NoSQL applications. Drill also provides intuitive extensions to SQL to work with complex/nested data types.
Compatibility with existing SQL environments
and Apache Hive deployments
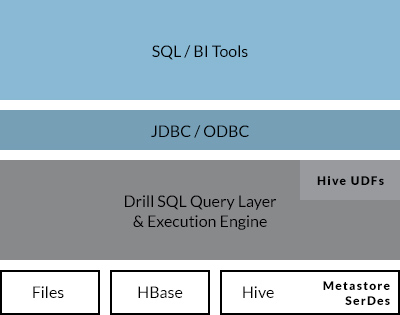
With Drill, businesses can minimize switching costs and learning curves for users with the familiar ANSI SQL syntax. Analysts can continue to use familiar BI/analytics tools that assume and auto-generate ANSI SQL code to interact with Hadoop data by leveraging the standard JDBC/ODBC interfaces that Drill exposes. Users can also plug-and-play with Hive environments to enable ad-hoc low latency queries on existing Hive tables and reuse Hive's metadata, hundreds of file formats and UDFs out of the box.